







深度学习大部分是监督学习,而且需要海量,高质量的数据对。这在现实世界,是非常难的事情。人类的学习过程里,不可能让一个孩子,看一亿张图片,才学会识别一只猫。
强化学习则更像人类的学习过程,这次3天达到世界顶尖高手水平的alpha zero也是基于强化学习的算法,从0开始。连接主义学习里,有监督学习,非监督学习,还有强化学习,强化学习靠环境提供的强化信号对动作的优劣做评价。
下面这篇文章对RL做了很好的总结:
http://karpathy.github.io/2016/05/31/rl/
OpenAI gym提供一个很好的强化学习的工具箱:
https://github.com/openai/gym

我们看看强化学习能做什么有意思的事情。
Atari是一个古老的打乒乓球的游戏。

再看一个MDP决策:
![]()
我们就让RL做类似的事情,本文先介绍让计算机从像素开始学会打乒乓球。
乒乓球的游戏规则就不多介绍,直接看系统如何实现,我们不只针对这个游戏做系统设计,我们设计尽量通过的系统,能完成更多任务,看如下的策略网络。
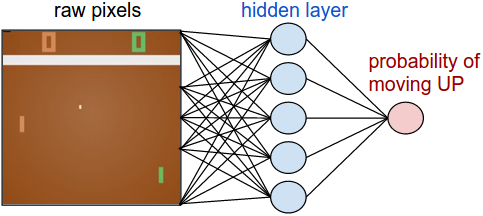
pip install gym,这个强化学习的开发包是需要的。atari_py这个包也是需要的。
t_states = tf.placeholder(tf.float32, shape=[None,80,80]) # policy network network = InputLayer(t_states, name='input') network = DenseLayer(network, n_units=H, act=tf.nn.relu, name='hidden') network = DenseLayer(network, n_units=3, name='output') probs = network.outputs sampling_prob = tf.nn.softmax(probs) t_actions = tf.placeholder(tf.int32, shape=[None]) t_discount_rewards = tf.placeholder(tf.float32, shape=[None]) loss = tl.rein.cross_entropy_reward_loss(probs, t_actions, t_discount_rewards) train_op = tf.train.RMSPropOptimizer(learning_rate, decay_rate).minimize(loss)
这里损失函数,我们仍然使用交叉熵损失:
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, targets=actions)
但在这个基础上,乘以环境反馈的回报reward:
loss = tf.reduce_sum(tf.multiply(cross_entropy, rewards))
action = tl.rein.choice_action_by_probs(prob.flatten(), [1,2,3]) observation, reward, done, _ = env.step(action)
每一次行动,系统会给出一个reward,奖励或惩罚,然后训练最优的行动方案。
强化还可以做很多很酷的事情,后续继续更新。
关于作者:魏佳斌,互联网产品/技术总监,北京大学光华管理学院(MBA),特许金融分析师(CFA),资深产品经理/码农。偏爱python,深度关注互联网趋势,人工智能,AI金融量化。致力于使用最前沿的认知技术去理解这个复杂的世界。
扫描下方二维码,关注:AI量化实验室(ailabx),了解AI量化最前沿技术、资讯。


















 68
68

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









