



 本文详细解析了ArrayList的工作原理,包括其实现机制、内部结构、增删改查等操作的实现细节。
本文详细解析了ArrayList的工作原理,包括其实现机制、内部结构、增删改查等操作的实现细节。

1. 简述
ArrayList其实就是动态数组,是Array的复杂版本,动态扩容和缩容,灵活的设置数组的大小,等等。
其定义如下
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.SerializableArrayList继承了AbstractList(这是一个抽象类,对一些基本的List操作进行了实现),实现了List。
ArrayList实现了RandmoAccess接口,即提供了随机访问功能。
ArrayList 实现了Cloneable接口,即覆盖了函数clone(),能被克隆。
ArrayList 实现java.io.Serializable接口,这意味着ArrayList支持序列化,能通过序列化去传输。
和Vector不同, ArrayList中的操作不是线程安全的 !所以,建议在单线程中才使用ArrayList,而在多线程中可以选择Vector或者CopyOnWriteArrayList。
其继承结构如下图
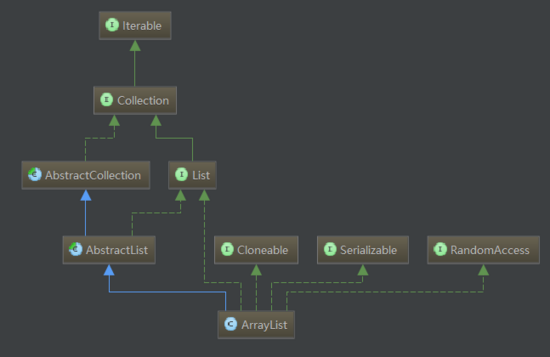
蓝色线条:继承
绿色线条:接口实现
2.List接口
Iterable和Collection接口里面声明的方法我们已经看过,现在看下List里面的方法:
List基础了Collection的所有方法,还自己声明了一些针对List操作的独有的方法
public interface List<E> extends Collection<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean addAll( int index, Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
//上面是继承自Collection的方法,下面就是List自己独有的方法
E get( int index);
E set( int index, E element);
void add( int index, E element);
E remove( int index);
int indexOf(Object o);
int lastIndexOf(Object o);
ListIterator<E> listIterator();
ListIterator<E> listIterator( int index);
List<E> subList( int fromIndex, int toIndex);
}
而AbstractCollection实现了Collection的部分方法和AbstractList继承了该AbstractCollection和实现了List部分方法,两个的源码就不再这儿分析了,主角是ArrayList。
3.ArrayList的底层存储
private transient Object[] elementData;
private int size;可以看出,底层存储是数组,还是Object类型。elementData数组是使用transient修饰的,关于transient关键字的作用简单说就是java自带默认机制进行序列化的时候,被其修饰的属性不需要维持, 简单的理解就是:
java序列化的时候,带有transient 修饰的属性,不被序列化进去。
size是是用来记数的,表示容器的元素个数。为什么不用elementData.length来表示容器的个数呢?
答:因为数组的大小刚开始默认分配是10,但是如果只存了5个对象,那么,后面几个为null,没有意义,所以需要使用size来记数,容器的元素到底有几个。这就是这个设计的目的。
4.ArrayList的构造方法
它有三个构造方法,分别针对不同情况下的初始化情况,代码如下;
//按照指定的容量进行初始化
public ArrayList(int initialCapacity) {
super();//调用父类的构造函数,父类的构造函数本身没做什么事情
if (initialCapacity < 0) //检查所传入的参数的合法性
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
}
/**
//默认初始化容量为10
public ArrayList() {
this(10);
}
//将一个容器来初始化成自己的容器元素
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
size = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
}
下面介绍其增删改查
5.增加方法
//增加指定的元素到容器,在末尾
public boolean add(E e) {
//检查容量
ensureCapacity(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
//在指定位置插入自己想增加的元素
public void add(int index, E element) {
//检查要插入的位置释放合法
if (index > size || index < 0)
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: "+size);
//确保容量
ensureCapacity(size+1); // Increments modCount!!
//将数组的index机器以后的元素拷贝到index+1的位置极其以后
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++; //容量加1
}
//增加一个集合的元素到ArrayList里面去
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacity(size + numNew); // Increments modCount
//将该内容拷贝容器的数组的后面
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
// 在指定的位置加入一个集合的元素
public boolean addAll(int index, Collection<? extends E> c) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(
"Index: " + index + ", Size: " + size);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacity(size + numNew); // Increments modCount
int numMoved = size - index;
if (numMoved > 0)
//先将该容器的index后面的元素拷贝到index+newNew之后,因为要留出位置拷贝要加入的内容
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
将c集合容器的内容拷贝到容器的index极其之后
System.arraycopy(a, 0, elementData, index, numNew);
//容器元素个数增加
size += numNew;
return numNew != 0;
}6.数组扩容
其实在每次增加之前,都进行检查了,不够就扩容
检查并扩容的方法如下:
//数组容量检查,不够就进行扩容
//参数为容器最小需要的容量(长度)
public void ensureCapacity(int minCapacity) {
modCount++;
//取得当前数组的长度
int oldCapacity = elementData.length;
如果容器需要的长度大于数组的总容量(长度)
if (minCapacity > oldCapacity) {
Object oldData[] = elementData;
//则数组的长度变为当前数组长度的1.5倍+1
int newCapacity = (oldCapacity * 3)/2 + 1;
if (newCapacity < minCapacity)
//如果新的数组长度还是小于其容器需要的最小容量,则数组长度则直接等于容器的需要的容量
newCapacity = minCapacity;
// minCapacity is usually close to size, so this is a win:
//创建这个扩容后的长度的数组,没有值的默认为null
elementData = Arrays.copyOf(elementData, newCapacity);
}
}7.删除
//根据元素的位置删除元素
public E remove(int index) {
//检查位置的范围
RangeCheck(index);
modCount++;
E oldValue = (E) elementData[index];
int numMoved = size - index - 1;
if (numMoved > 0)
//将index后面的元素拷贝到index上面,长度为后面的该移动的元素个数
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//将最后一位数组元素置为null,这样垃圾回收机制就可以回收了(做的很好),然后将size大小减一
elementData[--size] = null; // Let gc do its work
//返回老的元素
return oldValue;
}
//删除指定的元素
public boolean remove(Object o) {
//如果元素为null
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
//可以看出这个私有方法,只能它自己使用,根据位置,快速删除
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // Let gc do its work
}
private void RangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: "+size);
}
//清空容量里面的元素,并将大小置为0
public void clear() {
modCount++;
// Let gc do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
总结:可以看出指定元素删除和根据位置删除方法比,速度要快很多,因为少了查找位置的循环。如果知道位置的话,我们应该尽量选择根据元素的位置删除。
8.缩容
我们知道,在添加元素的时候,我们有可能会扩容,但是我删除元素的时候,却没有缩容,虽然我们将数组对应位置置为null,其引用的对象会被gc回收,但是数组容量会越来越大了(这个操作类库里面只提供,自己基本没有调用,应用程序应该 谨慎调用)。
//将数组的容量大小变为实际的容器的元素个数那么大
public void trimToSize() {
modCount++;
int oldCapacity = elementData.length;
if (size < oldCapacity) {
elementData = Arrays.copyOf(elementData, size);
}
}9.更新容器元素
//将指定位置的元素更改为指定的元素,并返回老的元素
public E set(int index, E element) {
RangeCheck(index);
E oldValue = (E) elementData[index];
elementData[index] = element;
return oldValue;
}10.查找容器元素
//获取指定位置的容器元素
public E get(int index) {
RangeCheck(index);
return (E) elementData[index];
}
小结:增加和删除的时候,我们发现代码写的很多,而且用到了System.arraycopy来移动元素,效率极低,而查找和更新的时候,直接使用下标,非常简单,效率极高。
11.其余的容器操作
11.1 查找元素是否在容器中
//判断容器是否包含元素
public boolean contains(Object o) {
//如果位置返回为正,则包含
return indexOf(o) >= 0;
}
//查看元素在容器中位置序号
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))//注意这儿是使用Object里面的equal方法,所以是判断两个对象的引用是不是同一个对象。
return i;
}
return -1;
}
//返回元素在容器中最后一次的位置
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}(o.equals(elementData[i]))
//注意这儿是使用Object里面的equal方法,所以是判断两个对象的引用是不是同一个对象。如果不是为-1
所以在下面有一个例子来说明
一个Recipe类
package it_cast.day01;
import java.util.LinkedList;
import java.util.List;
public class Recipe {
private String name;
private String key;
private List<Recipe> childrenDepend;
private Integer order;
//private Recipe mRecipe;
public List<Recipe> getChildrenDepend() {
return childrenDepend;
}
public void setChildrenDepend(List<Recipe> childrenDepend) {
this.childrenDepend = childrenDepend;
}
public Recipe() {
super();
// TODO Auto-generated constructor stub
}
public Recipe(String name, String key) {
super();
this.name = name;
this.key = key;
}
public Integer getOrder() {
return order;
}
public void setOrder(Integer order) {
this.order = order;
}
public Recipe(String name, String key,
Integer order) {
super();
this.name = name;
this.key = key;
this.order = order;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getKey() {
return key;
}
public void setKey(String key) {
this.key = key;
}
//@Override
/*public String toString() {
return "Recipe [name=" + name + ", key=" + key + "]";
}*/
}
应用测试类
public class LinklistTestDemo2 {
public static void main(String[] args) {
// TODO Auto-generated method stub
List <Recipe> a=new ArrayList<Recipe>();
Recipe rec=new Recipe("keepalive服务","A");
Recipe rec1=new Recipe("keepalive服务","B");
Recipe rec2=new Recipe("keepalive服务","C");
Recipe rec3=new Recipe("keepalive服务","D");
Recipe rec4=new Recipe("keepalive服务","E");
Recipe rec5=new Recipe("keepalive服务","E");
a.add(rec);
a.add(rec1);
a.add(rec2);
a.add(rec3);
a.add(rec4);
for(Recipe re:a){
System.out.println("the app is:"+re.getKey());
System.out.println(a.indexOf(re));
}
System.out.println(a.indexOf(rec5));
}
}打印结果
the app is:A
0
the app is:B
1
the app is:C
2
the app is:D
3
the app is:E
4
-1注意:由于rec5不是数组里面引用的对象,只是值相等,所以找不到很正常,这儿编写程序的人一定要注意了。
11.2 ArrayList转为数组
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
public <T> T[] toArray(T[] a) {
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}11.3克隆
public Object clone() {
try {
ArrayList<E> v = (ArrayList<E>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError();
}
}11.4序列化
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out array length
s.writeInt(elementData.length);
// Write out all elements in the proper order.
for (int i=0; i<size; i++)
s.writeObject(elementData[i]);
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in array length and allocate array
int arrayLength = s.readInt();
Object[] a = elementData = new Object[arrayLength];
// Read in all elements in the proper order.
for (int i=0; i<size; i++)
a[i] = s.readObject();
}打完收工,基本的差不多了
-------------------------------------------------------------------------------
后来看到好像有一个叫做FastArrayList的,刚开始还以为比ArrayList要快很多,但是有篇文章说两个测试效率差不多。
http://blog.youkuaiyun.com/feng27156/article/details/8504763
------------------------------------以下更新于2019年6月8号-------------------------
现在复习这块知识之后,又有新的理解。
之前ArrayList的底层存储里面,使用了transient关键字,存储这个数组,如下:
private transient Object[] elementData;当时在前面解释了,但是当时并没有真正的理解,所以当时也就是随便解释了一下,其实任何事物背后必有道理。我们应该认真思考一下,为什么这个数组修饰符上面一定要加transient关键字呢?
1. transient 关键字的作用是java对象在序列化的时候,被该关键字修饰的变量,不进行默认的序列化。
那我们要思考,其实ArrayList这个实现了Serializable接口,表示可以进行对象的序列化,但是不想对底层数组序列化,而且自己重写了序列化和反序列化方法,如下:
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
//调用默认的序列化的方法,将没有transient 关键字的字段给序列化了
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
//序列化数组里面的内容,因为这个内容被关键字transient修饰了,只能手动序列化了
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
/**
* Reconstitute the <tt>ArrayList</tt> instance from a stream (that is,
* deserialize it).
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}可以看得到自己序列化里面,只序列化了,其真正存放的大小,而不是整个底层数组的内容,因为底层数组的大小一般都比实际的大小大很多,这些值,一般没有值的时候,默认的是null, 没有必要进行序列化。这个才是主要目的。
如果对象方法里面自动写了writeObject和readObject的话,那么对象序列化的时候,会调用这两个方法进行序列化,而不是默认的,可以在这两个里面调用defaultWriteObject和defaultReadObject进行默认的序列化。
这个可以参考:java编程思想的序列化的章节

















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









