






 本文详细介绍了Linux系统中进程与线程的概念、进程描述符、任务结构、进程状态、进程创建与终结的过程。深入探讨了Linux如何实现线程、进程状态的管理和进程资源的释放。
本文详细介绍了Linux系统中进程与线程的概念、进程描述符、任务结构、进程状态、进程创建与终结的过程。深入探讨了Linux如何实现线程、进程状态的管理和进程资源的释放。
一、进程与线程
进程是处于执行期的程序,但是并不仅仅局限于一段可执行程序代码。通常,进程还要包含其他资源,像打开的文件,挂起的信号,内核内部数据,处理器状态,一个或多个具有内存映射的内存地址空间及一个或多个执行线程,当然还包括用来存放全局变量的数据段等。在Linux内核中,进程也通常叫做任务。
执行线程,简称线程,是在进程中活动的对象。每个线程都拥有一个独立的程序计数器、进程栈和一组进程寄存器。内核调度的对象是线程,而不是进程。在传统的UNIX系统中,一个进程只包含一个线程,但在现在的系统中,包含多个线程的多线程程序司空见惯。在Linux系统中,线程和进程并不特别区分,对Linux而言,线程是一种特殊的进程。
Linux实现线程的机制很独特。从内核角度来说,它并没有线程这个概念。Linux把所有的线程都当做进程来实现。内核并没有准备特别的调度算法或是定义特别的数据结构来表征线程。相反,线程仅仅被视为一个与其他进程共享某些资源的进程。每个线程都拥有唯一隶属于自己的 task_struct ,所以在内核中,它看起来就像是一个普通的进程。
二、进程描述符及任务结构
1)进程描述符
内核把进程的列表存放在任务队列中,任务队列是一个双向循环链表如图1所示。链表中每一项都是类型为 task_struct 的结构体,被称为 进程描述符,该结构定义在 <linux/sched.h>文件中。进程描述符中包含一个具体进程的所有信息。进程描述符中包含的数据能完整地描述一个正在执行的程序:它打开的文件、进程的地址空间、挂起的信号、进程的状态以及其他信息。
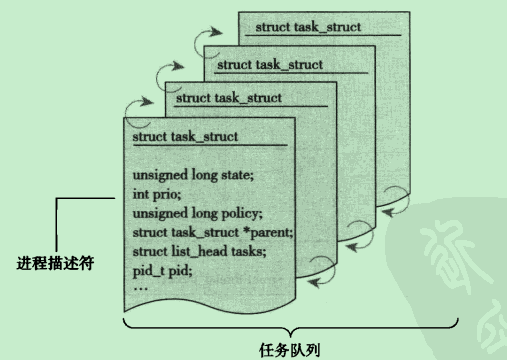
图1 进程描述符及任务队列
Linux通过slab分配器分配 task_struct 结构,这样能达到对象复用和缓存着色的目的,为了找到 task_struct,只需在栈底(对于向下增长的栈)或栈顶(对于向上增长的栈)创建一个新的结构 struct thread_info,该结构存放着指向任务实际 task_struct 的指针。结构的定义如下:
struct thread_info{ struct task_struct *task; struct exec_domain *exec_domain; _u32 flags; _u32 status; _u32 cpu; int preempt_count; mm_segment_t addr_limit; struct restart_block restart_block; void *sysenter_return; int uaccess_err; };
2)进程状态
进程描述符中的 state 域描述了进程的当前状态。系统中进程的状态大致有以下这几种:
| TASK_RUNNING(运行) | 表示进程正在执行,或者在运行队列中等待执行; |
| TASK_INTERRUPTIBLE(可中断) |
表示进程正在睡眠(被阻塞),等待某些条件的达成。一旦这些条件达成,内核就会把进程状态设置为运行,处于此状态的进程也会因为接收到信号而提前被唤醒并随时准备投入运行; |
| TASK_UNINTERRUPTIBLE(不可中断) | 除了就算接收到信号也不会被唤醒或者准备投入运行外,这个状态与可中断状态相同。这个状态通常在进程必须等待时不受干扰或者等待事件很快就会发生时出现; |
| __TASK_TRACED | 被其他进程跟踪的进程; |
| __TASK_STOPPED(停止) |
进程停止执行,进程没有投入运行也不能投入运行。通常,这种状态发生在接收到 SIGSTOP、SIGTSTP、SIGTTIN、SIGTTOU等信号的时候。此外,在调试期间接收到任何信号,都会使进程进入这种状态。 |
| EXIT_ZOMBIE(僵死状态) |
进程已经退出,但是进程本身所占的内存还没有被释放,如进程描述符等结构还保留着,以便父进程能够获得其停止运行的信息。当父进程获得需要的信息或者通知内核剩余的信息没用时,进程所占有的剩余的资源将被释放 |
| EXIT_DEAD(死亡状态) | 进程所占用的所有资源完全被释放 |
可以使用 set_task_state(task,state) 函数来设置当前进程状态:
set_task_state(task,state); // 将进程task的状态设置为 state
三、进程创建
linux使用 fork() 和 exec() 函数来创建进程。首先,使用 fork()函数拷贝当前进程创建一个子进程,这个子进程与父进程之间的区别仅在于 PID、PPID 以及某些资源统计量不同;然后调用 exec() 函数,把当前进程映像替换成新的进程文件,得到一个新程序。
传统的 fork() 系统调用直接把所有的资源复制给新创建的进程。这种实现过于简单且效率低下,因为它拷贝的数据也许并不共享。Linux 的 fork() 使用写时拷贝页实现,写时拷贝是一种可以推迟甚至免除拷贝数据的技术。内核此时并不复制整个进程地址空间,而是让父进程和子进程共享同一个拷贝。只有在需要写入的时候,数据才会被复制,从而使各个进程拥有各自的拷贝。也就是说,资源的复制只有在需要写入的时候才会进行,在此之前,只是以只读的方式共享。这种技术使得地址空间上的页的拷贝被推迟到实际发生写入的时候才进行。在页根本不会被写入的情况下,它们就无须复制了。
四、进程终结
调用 do_exit() 来终结进程。当一个进程被终结时,内核必须释放它所占有的资源,并告知其父进程。
在调用 do_exit() 之后,尽管线程已经僵死不能再运行了,但是系统还是保留了它的进程描述符。在父进程获得已终结的子进程的信息后,或者通知内核它并不关注那些信息后,子进程的 task_struct 结构才被释放。调用 release_task() 来释放进程描述符。

















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









