






 本文介绍了一种基于倍增策略的后缀数组构建方法,并提供了完整的C++实现代码。该方法通过多轮基数排序,逐步增加比较长度来构建后缀数组,同时计算后缀间的最长公共前缀。
本文介绍了一种基于倍增策略的后缀数组构建方法,并提供了完整的C++实现代码。该方法通过多轮基数排序,逐步增加比较长度来构建后缀数组,同时计算后缀间的最长公共前缀。
直接解释代码
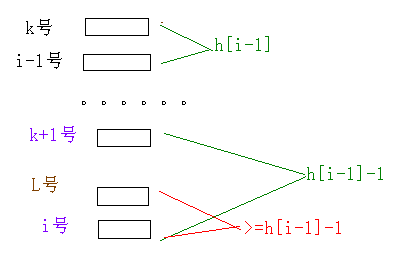
#include<cstdio> #include<cstring> #include<algorithm> using namespace std; #define N 100001 char ch[N]; int n,k,a[N],v[N],p,q=1,sa[2][N],rk[2][N],h[N]; void mul(int *sa,int *rk,int *SA,int *RK)//sa,rk是上一轮基数排序的结果,SA,RK是本轮结束后基数排序的结果 // 把后缀从前往后编号,sa[i]排第i名(排名即字典序大小)的后缀是谁,rk[i]i号后缀的排名是多少 { for(int i=1;i<=n;i++) v[rk[sa[i]]]=i; //v用另一种方法统计了前缀和,i是排名,v[j]=i为排名为1——j的数一共有i个 for(int i=n;i;i--) if(sa[i]>k) //只有sa[i]>k,i才能既是sa[i]的第一关键字排名,又是sa[i]-k的第二关键字排名 SA[v[rk[sa[i]-k]]--]=sa[i]-k;//倍增之后新的sa数组 for(int i=n-k+1;i<=n;i++) //n-k之后的二元组无第二关键字,排在所属前缀和范围的最前面 SA[v[rk[i]]--]=i; for(int i=1;i<=n;i++) //倍增之后新的rk数组 RK[SA[i]]=RK[SA[i-1]]+(rk[SA[i]]!=rk[SA[i-1]]||rk[SA[i]+k]!=rk[SA[i-1]+k]); //对比两个关键字 } void presa() { for(int i=1;i<=n;i++) v[a[i]]++;//相同字母的个数(相同的后缀起始位置) for(int i=1;i<=26;i++) v[i]+=v[i-1];//前缀和,为设定初始排名(即只对一个字母的排名)做准备 for(int i=1;i<=n;i++) sa[p][v[a[i]]--]=i; //有了前缀和数组v后,数i的排名便在v[i-1]+1——v[i]之间,实际上v[i]-v[i-1]个数的排名相等,这里不设为相等 for(int i=1;i<=n;i++) rk[p][sa[p][i]]=rk[p][sa[p][i-1]]+(a[sa[p][i-1]]!=a[sa[p][i]]); //sa数组与rk数组相反,sa[i]=j表示排名为i的后缀起始位置为j,rk[i]=j表示起始位置为i的后缀排名为j for(k=1;k<n;k<<=1,swap(p,q))//真正开始倍增排序 //p所代表的的是上一轮信息,q代表的是要进行的本轮排序信息 //上一轮基数排序的结果,是本轮基数排序的要利用的信息 ,所以p,q交换 mul(sa[p],rk[p],sa[q],rk[q]); //求height数组: //height[i]:排名为i的后缀和排名为i-1的后缀的 最长公共前缀 //设h[i]表示rk[i]和rk[i]-1的最长公共前缀,即i号后缀和排在i号后缀前一名的后缀的最长公共前缀 //那么有一个性质:h[i]>=h[i-1]-1 //注:字符串中,i号后缀的顺序在i-1号后缀后面,排名就不一定了,后面的排在XX哪儿均指排名 //证明: //若h[i-1]=1,显然成立 //若h[i-1]>1,设排名为rk[i-1]-1的后缀为k号后缀,即后缀k排在后缀i-1的前一位 //那么h[i-1]=后缀i-1和后缀k的最长公共前缀,显然他们至少前两个字符相同 //i号后缀即为i-1号后缀去掉第一个字母,k+1号后缀即为k号后缀去掉第一个字母 //显然k+1号后缀一定排在i号后缀的前面,否则k号后缀就不会排在i-1号后缀的前面 //若k+1号后缀恰好排在i号后缀的前一名,显然成立 //否则,设排在i好后缀的前一名是L号后缀,L号后缀一定在k+1号后缀的后面 //L号后缀和i号后缀的最长公共前缀>=k+1号后缀和i号后缀的最长公共前缀 //因为i号后缀和k+1号后缀的最长公共前缀一定是在L的前缀,否则L不会排名在i和k+1的中间;L号后面还会有可能继续与i号匹配 //所以h[i]>=h[i-1]-1,即i号后缀和排在i号前一名的后缀的最长公共前缀>=i-1号后缀和排在i-1号前一名的后缀的最长公共前缀-1 for(int i=1,k=0;i<=n;i++) { int j=sa[p][rk[p][i]-1]; //p:虽然倍增过程中新的一轮排序信息存在q里,但结束后还要执行swap,所以用p里的信息 while(a[i+k]==a[j+k]) k++; h[rk[p][i]]=k;if(k) k--; //这里的h数组指的是上面说的height数组,上面的h数组的信息是用来辅助计算height的,可以不用存 } } int main() { scanf("%s",ch+1); n=strlen(ch+1); for(int i=1;i<=n;i++) a[i]=ch[i]-'a'+1;//字符串转化为数字 presa(); for(int i=1;i<=n;i++) printf("%d ",sa[p][i]);puts(""); for(int i=2;i<=n;i++) printf("%d ",h[i]); }

















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









