



这周我们了解了解释器风格 通过看书和查找资料对解释器相关的资料进行了整理
首先我们来了解一下什么是解释器:
An interpreter is a program that executes another program (解释器是一个用来执行其他程序的程序).
An interpreter implements a virtual machine, which may be different from the underlying hardware platform. (解释器针对不同的硬件平台实现了一个虚拟机)
To close the gap between the computing engine expected by the semantics of the program and the computing engine available in hardware.
(将高抽象层次的程序翻译为低抽象层次所能理解的指令,以消除在程序语言与硬件之间存在的语义差异)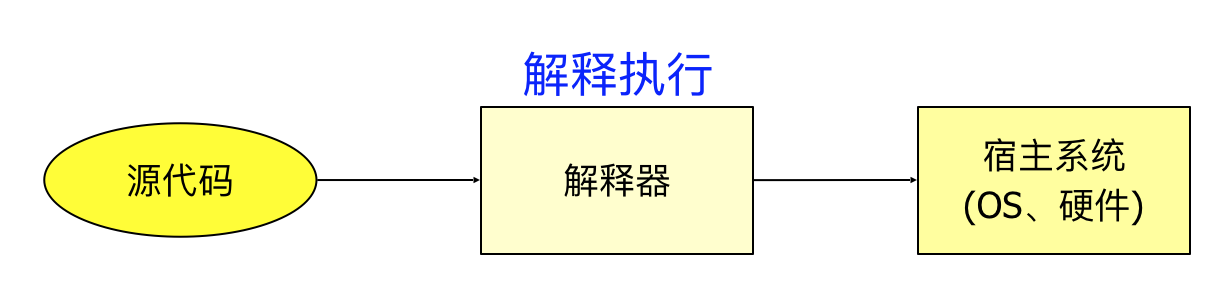
解释器的应用:
包括各类语言环境、Internet浏览器、数据分析与转换等;
LISP、Prolog、JavaScript、VBScript、HTML、Matlab、数据库系统(SQL解释器)、各种通信协议等。
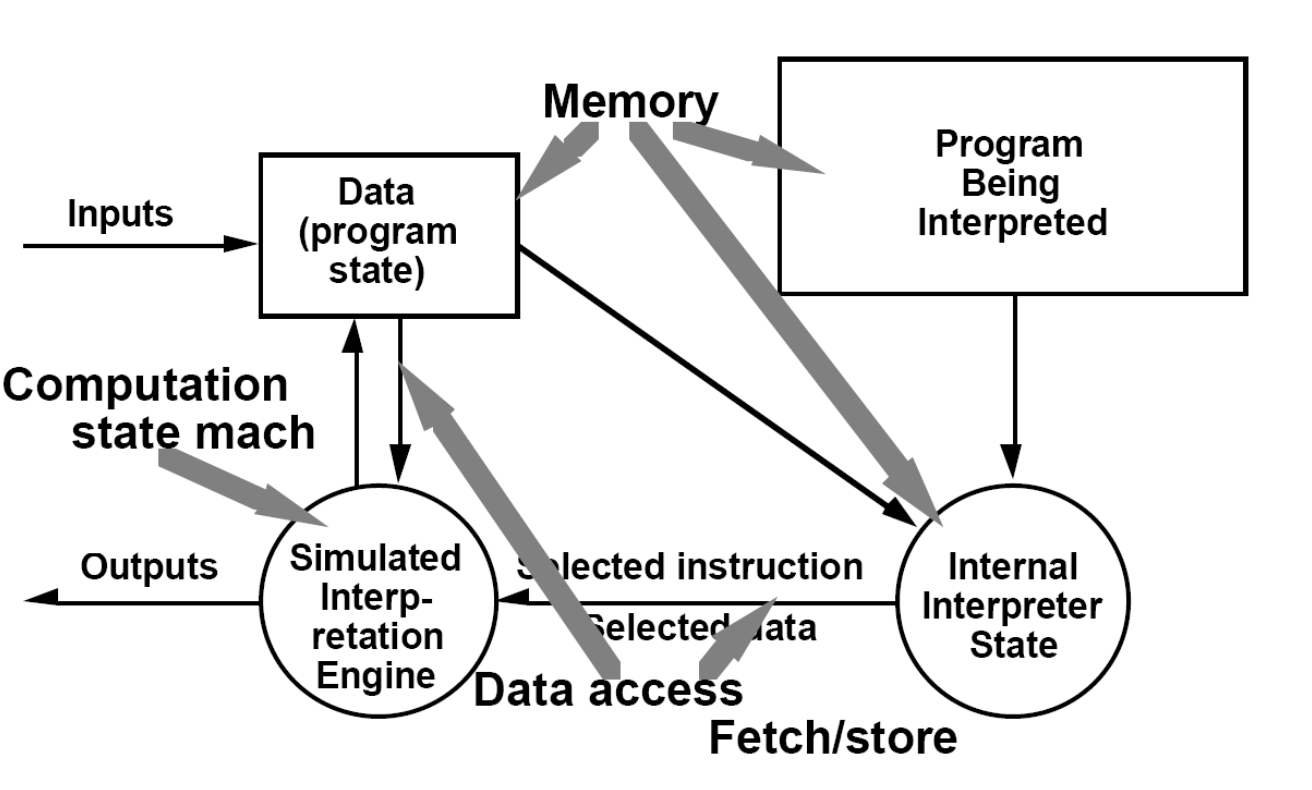
解释器的组成:
解释器风格:
基本构件:
An interpretation engine (解释器引擎)
A Memory that contains(存储区):
The pseudo-code to be interpreted (被解释的源代码)
A representation of the control state of the interpretation engine (解释器引擎当前的控制状态的表示)
A representation of the current state of the program being simulated. (程序当前执行状态的表示)
连接器:
Data access (对存储区的数据访问)
解释器的三种策略:
传统解释器(traditionally interpreted)
纯粹的解释执行
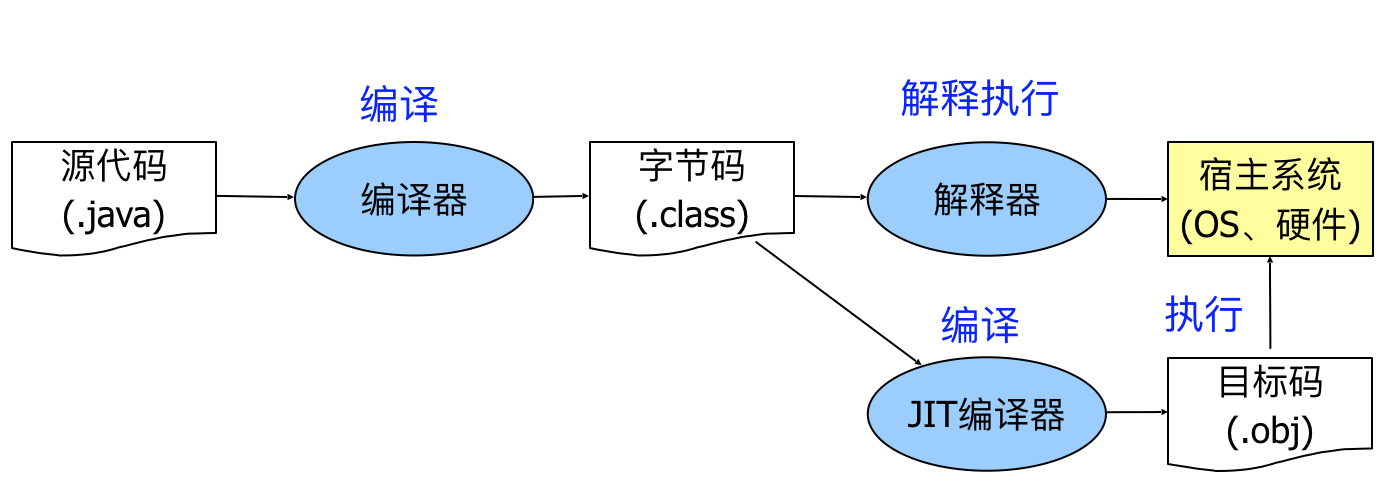
基于字节码的解释器 (compiled to bytecode which is then interpreted)
编译解释执行

Just-in-Time (JIT)编译器
编译||解释执行

















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









