



 本文探讨Java中的并行执行环境及Fork/Join框架的应用,通过实例对比自建多线程与Fork/Join框架处理IO密集型与计算密集型任务的性能。
本文探讨Java中的并行执行环境及Fork/Join框架的应用,通过实例对比自建多线程与Fork/Join框架处理IO密集型与计算密集型任务的性能。

1.并行的执行环境
Java并行无处不在。一般分为两种情况:
- 每个线程都在独立的状态环境下运行,说通俗一点就是,每个线程对应一套不同的Java对象;
- 所有线程都在一个无状态或状态不可变的环境下运行。
显然,第一种情况更占内存。应该尽可能地设计成无状态或状态不可变的环境。最典型的就是Spring Bean。默认情况下,Spring Bean是单例的,因为Spring Bean的成员变量一般都是另外一些Spring Bean或者一些不可变配置,所以不管多少线程同时执行Spring Bean,都不会改变Spring Bean的状态。这样的设计非常节省内存。
但是如果执行结果必须要保存状态(一般是给别的线程种类消费),就该设计成第一种情况。因为这种设计可能会产生过多对象,一定要管理好这些对象的生命周期,防止内存溢出。比如,不要让它们在使用完了之后还一直被引用。
并行还容易产生过多的线程。这可以用线程池来解决。关于线程池会在别的专题讲。
2.Fork/Join框架
Java并行还有一种特殊需求模型,那就是分支/合并模型。Java 7引入了Fork/Join框架处理这种模型。Fork/Join框架是一种将大任务动态拆分成小任务,小任务还可以继续拆分成更小的任务,最后把结果汇总合并的模型。
Fork/Join框架主要类介绍:
- ForkJoinTask:ForkJoinTask提供在任务中执行fork()和join()操作的机制,通常情况下我们会扩展ForkJoinTask的两个子类来使用Fork/Join框架框架:
- RecursiveAction:适用于没有返回结果的任务;
- RecursiveTask :适用于有返回结果的任务。
- ForkJoinPool :ForkJoinTask要用ForkJoinPool线程池执行。
Fork/Join框架工作原理:
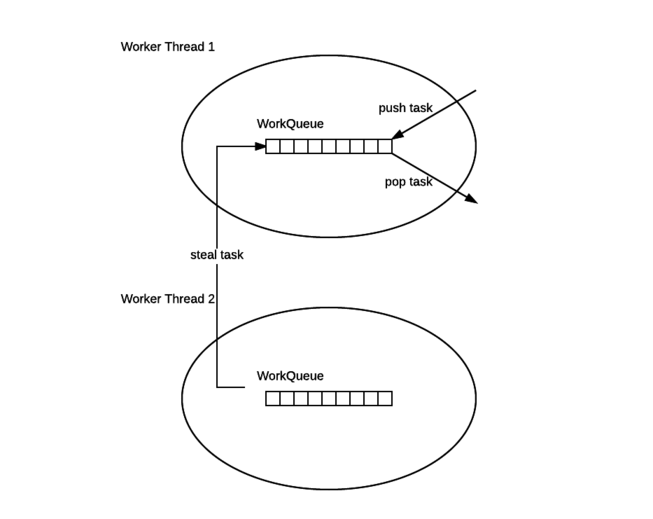
- ForkJoinPool里面的每个线程都是ForkJoinWorkerThread,它是Thread的扩展。每个ForkJoinWorkerThread都维护着一个工作队列WorkQueue,WorkQueue是一个双端队列;
- 每个ForkJoinWorkerThread在运行时产生新任务的时候(通常是调用了fork()方法),就会从头部放入自己的WorkQueue;
- ForkJoinWorkerThread在自己没有任务的时候,就会尝试偷其它ForkJoinWorkerThread的任务,从对方的工作队列的尾部窃取;
- 每个ForkJoinWorkerThread在需要等待join时候,就会尝试执行其它任务,如果自己的工作队列有其它任务,就会去执行,从自己工作队列的头部获取;如果没有,就会去偷其它ForkJoinWorkerThread的任务,从对方的工作队列的尾部窃取;
- ForkJoinWorkerThread在既没有自己的任务,又偷不到其它任务时,会选择休眠。
下图是工作窃取算法的示意图:
下图是工作窃取流程图:
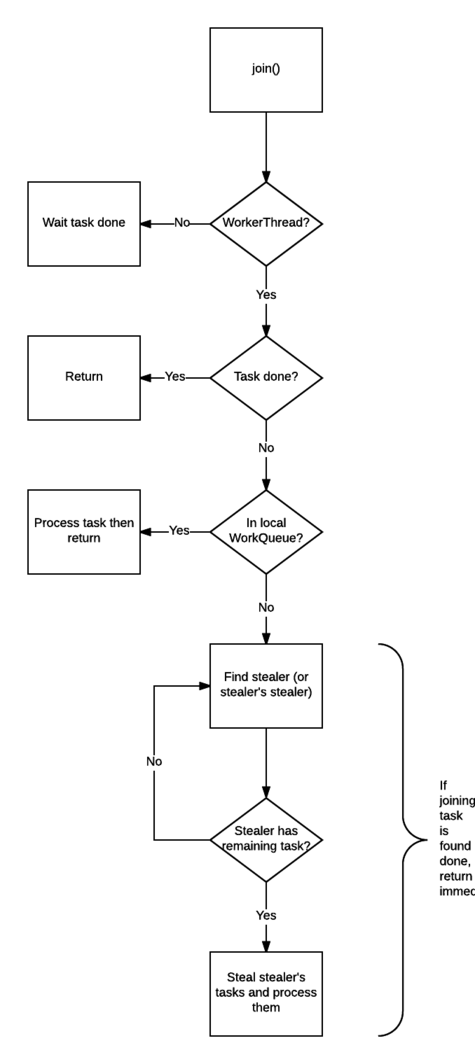
- 检查调用join()的线程是否是 ForkJoinWorkerThread线程。如果不是(例如 main 线程),则阻塞当前线程,等待任务完成。如果是,则不阻塞;
- 查看任务的完成状态,如果已经完成,直接返回结果;
- 如果任务尚未完成,但处于自己的工作队列内,则完成它;
- 如果任务已经被其他的工作线程偷走,则窃取这个小偷的工作队列内的任务(以 FIFO 方式),执行,以期帮助它早日完成欲 join 的任务;
- 如果偷走任务的小偷也已经把自己的任务全部做完,正在等待需要 join 的任务时,则找到小偷的小偷,帮助它完成它的任务;
- 递归地执行第5步。
可见,如果任务本身不阻塞,整个执行过程是不阻塞的。工作窃取机制不会让任何线程呆在那不干活。这就是Fork/Join框架最大的优势。假设阻塞时间为0,也就是整个执行过程都是CPU运算,那么最佳线程数量就是计算机的CPU个数。在这种情况下,用少量的线程就能达到最佳性能。
现在引出一个有趣的问题:如果任务被阻塞了,被阻塞的原因有很多,可能因为sleep(),可能因为I/O阻塞,也可能因为线程间同步……用Fork/Join框架处理会怎么样?
假设计算机CPU个数为4,最小任务数为10000个,每个任务阻塞的时间为99ms,总共执行时间为100ms。那么用Fork/Join框架执行这个任务总共要多久呢?没错,大约就是250s。这里忽略fork、join和窃取任务的时间,因为线程数量小,可以忽略不计。但是,这样的处理性能明显很差,因为没有充分利用好CPU的计算能力。
好,那就应该增加线程数量。线程数量应该为多少才能最大限度地利用CPU的计算能力呢?答案是400个线程。因为每个任务占CPU的时间是百分之一,同时执行一百个任务才能占满一个CPU,同时执行400个任务就能占满4个CPU。理论上最佳性能是2.5秒完成任务。
这时,工作窃取算法的问题就出来了,工作窃取算法本身是有CPU损耗的,最大的开销可能就在双端队列尾部被多个工作线程窃取的时候。4个线程的时候可以忽略不计,但是如果到了400个线程,这种损耗可能比任务执行时间(2.5s)要大得多,是无法接受的。
当然,上面的数据都是一些假设,实际数据可能会很不一样。但是至少能说明一个问题,就是当任务阻塞时间比较长的情况下,用Fork/Join框架处理的性能不会很理想。
一句话总结:Fork/Join框架适合用少量的线程执行符合分支/合并模型的计算密集型任务。
但是,我们一般不会直接使用Fork/Join框架。它实际上是Java 8中Stream的底层支持框架,还有Java 9的Flow API也是以Fork/Join框架为基础。
3.并发实战
现在我们来做一个题目:
有100000个页面,每个页面的内容是一个四位数的随机整数。要求用并行的办法,获取这100000个页面,提取页面内容,统计内容为偶数的页面总数。
分析:这是一个IO密集型任务。也就是说,阻塞时间远远大于CPU执行时间,访问一个网页大概需要20-60ms,而提取内容并判断是不是偶数几乎不需要时间。同时,它也符合分支/合并模型。
3.1 自建多线程处理
思路:把所有任务切割成WORK_COUNT个任务块,就是说线程每次执行一次任务,就处理WORK_COUNT个页面。启动一个线程池,设置线程池的大小为THREAD_POOL_SIZE。记录每个任务块中内容为偶数的页面数,等所有任务都执行完毕后,汇总结果。
结果:在最佳设置情况下(WORK_COUNT=30000,THREAD_POOL_SIZE=3000),耗时:1970ms。
import java.util.Date;
import java.util.Random;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/** *
* 测试类(测试机器cpu i5-4200M,双核四线程)
* * 获取每个页面数据的模拟速度是20-60ms,平均每个页面40ms,单线程执行大约需要67min
* * 可以把整个任务切割成N个子任务,然后合并各个子任务的统计数据
* 如果子任务数过大(极端情况N=10w),在线程池数量配置得当的情况下,也要7s以上。最佳子任务数大约在3000-30000之间
* * 线程池最佳线程数大约为3000-5000之间 * 在合适的子任务数和线程池大小的情况下,执行时间可以控制在2s以内。是单线程性能的2000倍以上。
* * @author xiaoyilin *
* */
public class PageHandlerInvoker {
//配置要处理的页面数
private static final int PAGE_COUNT = 100000;
//配置切割的任务数
private static final int WORK_COUNT = 30000;
//配置线程池大小
private static final int THREAD_POOL_SIZE = 3000;
public static void main(String[] args) {
//记录执行开始时间
long startTime = new Date().getTime();
//每个小任务要执行的页面数
int pageCountPerWork = (PAGE_COUNT / WORK_COUNT) + 1;
//确保所有工作都已完成,然后进行统计工作
final CountDownLatch doneLatch = new CountDownLatch(WORK_COUNT);
//线程池,避免创建过多线程
ExecutorService excutorService = Executors.newFixedThreadPool(THREAD_POOL_SIZE);
//工作线程类集合,做统计用
PageHandlerThread[] handlers = new PageHandlerThread[WORK_COUNT];
for (int i = 0; i < WORK_COUNT; i++) {
if ((pageCountPerWork * i) >= PAGE_COUNT) {
//空任务,如果所有页面都处理完了,还剩下一些任务,就走这个空任务
new Thread(String.valueOf(i)) {
@Override
public void run() {
doneLatch.countDown();
}
}.start();
} else if ((pageCountPerWork * (i + 1)) >= PAGE_COUNT) {
//最后一个任务,任务数没有其他任务多
PageHandlerThread handler = new PageHandlerThread(pageCountPerWork * i,
PAGE_COUNT, doneLatch);
excutorService.execute(handler);
handlers[i] = handler;
}
else {
//给每个任务分配相同的页面数
PageHandlerThread handler = new PageHandlerThread(pageCountPerWork * i,
pageCountPerWork * (i + 1), doneLatch);
excutorService.execute(handler);
handlers[i] = handler;
}
}
try {
doneLatch.await();
//等待所有任务执行完毕,再往下执行
}catch (InterruptedException e) {
//省略异常处理
}
//聚合所有任务的统计数据
int count = 0;
for (int i = 0; i < WORK_COUNT; i++) {
if (handlers[i] != null) {
count += handlers[i].getCount();
}
}
//打印出结果
System.out.println("偶数页面总数:" + count + " ,执行时间:" +
(new Date().getTime() - startTime) + "ms");
//关闭线程池
excutorService.shutdown();
}
}
/**
* * 页面处理工作线程类
* * @author xiaoyilin *
* */
class PageHandlerThread implements Runnable {
private final CountDownLatch doneLatch;
private final int start;
private final int end;
private int count = 0;
public PageHandlerThread(int start, int end, CountDownLatch doneLatch) {
this.start = start;
this.end = end;
this.doneLatch = doneLatch;
}
@Override
public void run() {
count = PageHandler.countEvens(start, end);
doneLatch.countDown();
}
public int getCount() {
return count;
}
}
/**
* * 页面处理工具类
* * @author xiaoyilin *
* */
class PageHandler {
//每个线程拥有一个单独的页面处理对象
private static final ThreadLocal<ThreadSpecificPageHandler> tl = new ThreadLocal<ThreadSpecificPageHandler>();
/** * 委托当前线程的页面处理对象,处理新的任务,返回当前线程处理的偶数页面总数 * 当前线程可能执行过多次任务 * @param start * @param end * @return */
public static int countEvens(int start, int end) {
return getThreadSpecificPageHandler(start, end).countEvens();
}
/**
* * 获取当前线程的页面处理对象,并给这个对象设置最新的任务
* * @param start
* * @param end
* * @return
* */
private static ThreadSpecificPageHandler getThreadSpecificPageHandler(
int start, int end) {
ThreadSpecificPageHandler tsph = tl.get();
if (tsph == null) {
tsph = new ThreadSpecificPageHandler();
}
tsph.setStart(start);
tsph.setEnd(end);
tl.set(tsph);
return tsph;
}
}
/**
* * 线程隔离的页面处理类
* * @author xiaoyilin
* * */
class ThreadSpecificPageHandler {
private int start;
private int end;
private int count = 0;
/**
* * 统计当前线程获取到的偶数页面数
* * @return
* */
public int countEvens() {
for (int i = start; i < end; i++) {
if (i == start) {
count = 0;
//如果这个线程执行过其他任务,就要清理掉以前的统计数据
}
count += getPageResultMock(i);
}
return count;
}
/**
* * 模拟获取页面内容是奇数还是偶数的方法,如果是偶数返回1,奇数返回0。
* * 休眠时间20ms-60ms,由一个随机数控制,模拟获取页面的时间;用一个四位随机数模拟页面内容。
* * @param i
* * @return
* */
private int getPageResultMock(int i) {
//long startTime = new Date().getTime();
try {
Random randTime = new Random();
int randTimeInt = randTime.nextInt(60 - 20 + 1) + 20;
Thread.sleep(randTimeInt);
//System.out.println(Thread.currentThread().getId()+"休眠时间:"+(randTimeInt));
}catch (InterruptedException e) {
//省略异常处理
}
Random rand = new Random();
int randomInt = rand.nextInt(9999 - 1000 + 1) + 1000;
int flag = 0;
if ((randomInt % 2) == 0) {
flag = 1;
}else {
flag = 0;
}
//System.out.println(Thread.currentThread().getId()+"单个执行时间:"+(new Date().getTime() - startTime));
return flag;
}
public void setStart(int start) {
this.start = start;
}
public void setEnd(int end) {
this.end = end;
}
}
3.2 用Fork/Join框架处理
思路:借助Fork/Join框架来实现
结果:当线程数量大约为500个时,表现最佳,耗时:21568ms
import java.util.Date;
import java.util.Random;
import java.util.concurrent.Executors;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
/**
* 启动类,用ForkJoinPool线程池执行
* @author XIAOYILIN
*
*/
public class PageHandlerForkJoinInvoker {
//配置要处理的页面数
private static final int PAGE_COUNT = 100000;
public static void main(String[] args) {
//记录执行开始时间
long startTime = new Date().getTime();
ForkJoinPool pool = (ForkJoinPool) Executors.newWorkStealingPool(400);
Integer result = pool.invoke(new ForkJoinPageHandler(0,PAGE_COUNT));
//打印出结果
System.out.println("偶数页面总数:" + result + " ,执行时间:" +
(new Date().getTime() - startTime) + "ms");
}
}
/**
*
* @author XIAOYILIN
*
*/
class ForkJoinPageHandler extends RecursiveTask<Integer> {
private static final long serialVersionUID = 6729677280054383408L;
private int start;
private int end;
public ForkJoinPageHandler(int start,int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
if(end==start) {
return getPageResultMock(end);
}
ForkJoinPageHandler f1 = new ForkJoinPageHandler(start,(start+end)/2);
f1.fork();
ForkJoinPageHandler f2 = new ForkJoinPageHandler((start+end)/2+1,end);
return f2.compute() + f1.join();
}
private int getPageResultMock(int i) {
//long startTime = new Date().getTime();
try {
Random randTime = new Random();
int randTimeInt = randTime.nextInt(60 - 20 + 1) + 20;
Thread.sleep(randTimeInt);
//System.out.println(Thread.currentThread().getId()+"休眠时间:"+(randTimeInt));
}catch (InterruptedException e) {
//省略异常处理
}
Random rand = new Random();
int randomInt = rand.nextInt(9999 - 1000 + 1) + 1000;
int flag = 0;
if ((randomInt % 2) == 0) {
flag = 1;
}else {
flag = 0;
}
//System.out.println(Thread.currentThread().getId()+"单个执行时间:"+(new Date().getTime() - startTime));
return flag;
}
}
从上面两种实现对比可以看出,用Fork/Join框架实现的性能差了10倍都不止。因为这个任务是IO密集型任务,不是计算密集型任务。
如果把这个任务变成计算密集型任务,结果会怎样呢?你可以把任务中,休眠的那部分代码注释掉,整个任务就没有阻塞的存在了,然后再加上一点计算任务。
try {
Random randTime = new Random();
int randTimeInt = randTime.nextInt(60 - 20 + 1) + 20;
Thread.sleep(randTimeInt);
}catch (InterruptedException e) {
//省略异常处理
}换成:
int count = 0;
while(count<1000000000) {
count++;
}
System.out.println(count);再把两种实现的线程数都改为4(=CPU个数)。结果两种实现大约都在1s左右,Fork/Join框架实现大约要多几十毫秒。但是Fork/Join框架实现的代码整洁清晰多了,通用性也高得多,这就是Fork/Join框架的优势!

















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









