






 Spark作为通用的大数据计算框架,以其快速高效的特点,在大数据处理领域占据了重要位置。它不仅速度快、易开发,还具备极高的通用性和活跃度。本文介绍了Spark相较于MapReduce的优势,包括基于内存的计算方式以及在不同场景下的应用,如替代Hive查询引擎和通过Spark Streaming实现准实时计算。
Spark作为通用的大数据计算框架,以其快速高效的特点,在大数据处理领域占据了重要位置。它不仅速度快、易开发,还具备极高的通用性和活跃度。本文介绍了Spark相较于MapReduce的优势,包括基于内存的计算方式以及在不同场景下的应用,如替代Hive查询引擎和通过Spark Streaming实现准实时计算。
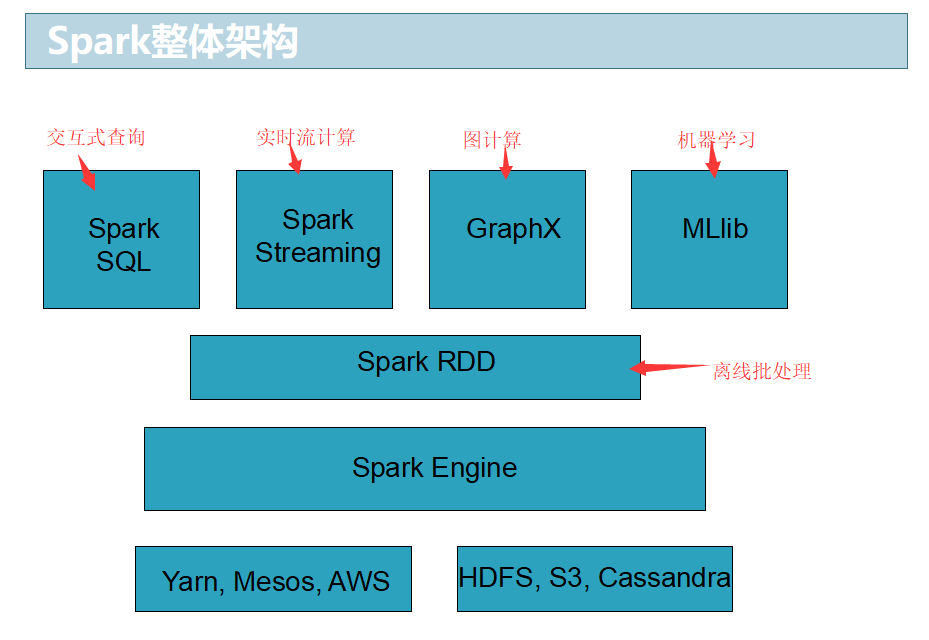
Spark 是一种“One Stack to rule them all”通用的大数据计算框架,期望使用一个技术栈就完美地
解决大数据领域的各种计算任务。
Spark特点:速度快、容易上手开发、超强的通用性、集成Hadoop、极高的活跃度。
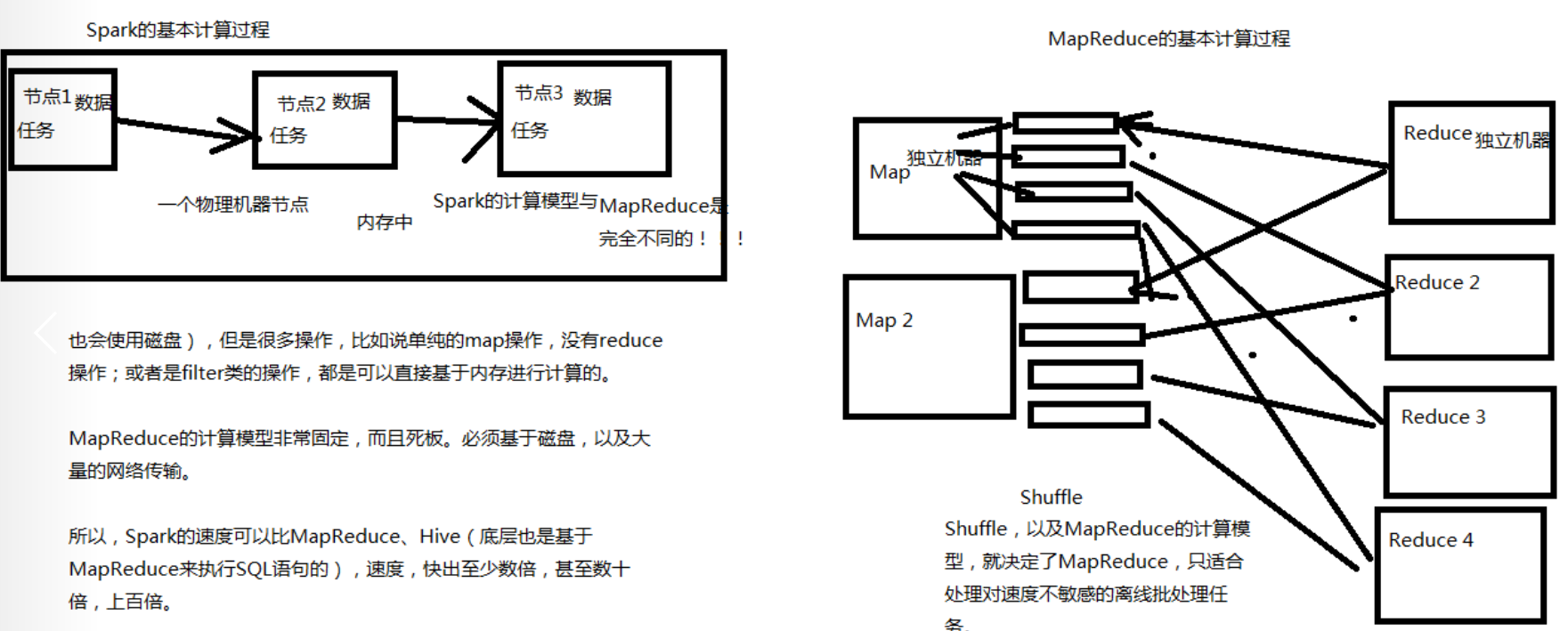
Spark的速度比MapReduce快:MR计算模型太死板,而且里面最好性能的就是shuffle,shuffle
中间的过程都是基于磁盘来读写的。而Spark是基于内存进行计算的。
Spark缺陷:Spark是基于内存进行计算的,如果数据量太大,没有调优的情况下,会出现OOM。
但是此时MR尽管运行速度慢,但是其可以完成任务。
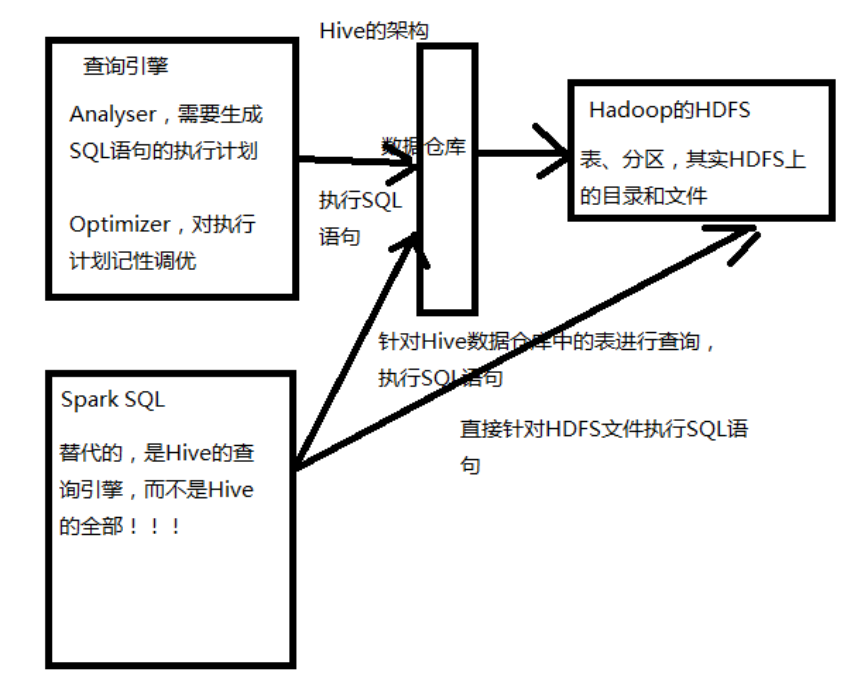
Spark替代的是Hive的查询引擎,而不是Hive的全部!!!

Spark Streaming严格意义上来说,是一种准实时的计算框架。而Storm是真正意义上的实时计算框架。
Spark Streaming的吞吐量远远比Storm大。

















 2161
2161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









