 TOPN与ROW_NUMBER性能对比
TOPN与ROW_NUMBER性能对比




 本文通过实验对比了SQL Server中使用TOPN与ROW_NUMBER进行前N行数据查询的性能差异,发现虽然两种方法在小规模数据上的性能相近,但在大规模数据查询时,TOPN的性能更优。
本文通过实验对比了SQL Server中使用TOPN与ROW_NUMBER进行前N行数据查询的性能差异,发现虽然两种方法在小规模数据上的性能相近,但在大规模数据查询时,TOPN的性能更优。
前言
抱歉各位,从八月份开始一直在着手写EntityFramework 6.x和EntityFramework Core 2.0的书籍写作,所以最近一直遗漏了对博客的管理,后面会着手于写SQL Server、EntityFramework Core和.NET Core方面的博客。我们知道如果需要查询前N行数据,除了可以利用TOP N进行查询外,同样也可以利用ROW_NUMBER来达到同样的效果,那么二者使用哪个性能会更好呢?下面我们来比较下。
ROW_NUMBER VS TOP N
我们利用AdventureWorks2012示例库中的Production.Product表来进行演示,如下:

DBCC DROPCLEANBUFFERS() DBCC FREEPROCCACHE() GO --ROW_NUMBER QUERY SELECT ProductID FROM ( SELECT ProductID, ROW_NUMBER() OVER (ORDER BY ProductID) AS RN FROM Production.Product ) AS T WHERE T.RN <= 100 GO -- TOP N QUERY SELECT TOP 100 ProductID FROM Production.Product ORDER BY ProductID GO
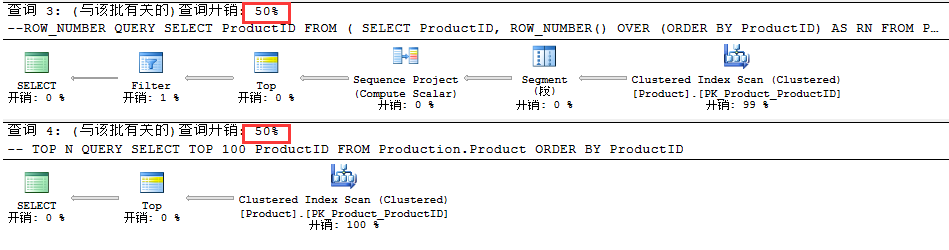
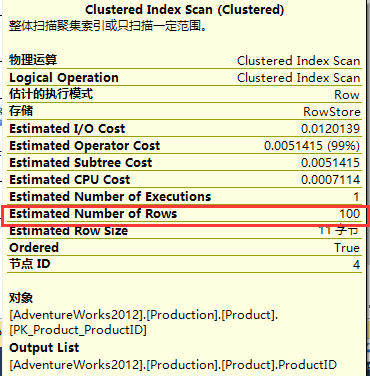
如上图所知,对于这两个查询计划的成本是一样的,都为50%。 如果我们要检查在两个聚集索引扫描操作符中读取的估计行数,那么我们会注意到两者都显示相同的值,即100。可以说聚集索引扫描的估计和实际行数是相同的都是100,如下。
是不是就以此说明二者性能是一样的呢?稍等片刻,接下来我们将查询基数再设置大一点看看,比如1000而不再是100,如下:
DBCC DROPCLEANBUFFERS() DBCC FREEPROCCACHE() GO SET STATISTICS IO ON SET STATISTICS TIME ON --ROW_NUMBER QUERY SELECT ProductID FROM ( SELECT ProductID, ROW_NUMBER() OVER (ORDER BY ProductID) AS RN FROM Production.Product ) AS T WHERE T.RN <= 1000 GO -- TOP N QUERY SELECT TOP 1000 ProductID FROM Production.Product ORDER BY ProductID GO

从如上截图可以看出,使用ROW_NUMBER进行查询的速度要明显快于TOP N,即29%和71%。 但是,我们还需要在等一下,因为我们在这里看到的成本只是估计成本。 如果操作的估算不准确,那么查询计划估算成本也将不准确。 接下来我们检查两个计划中的聚集索引扫描的属性:
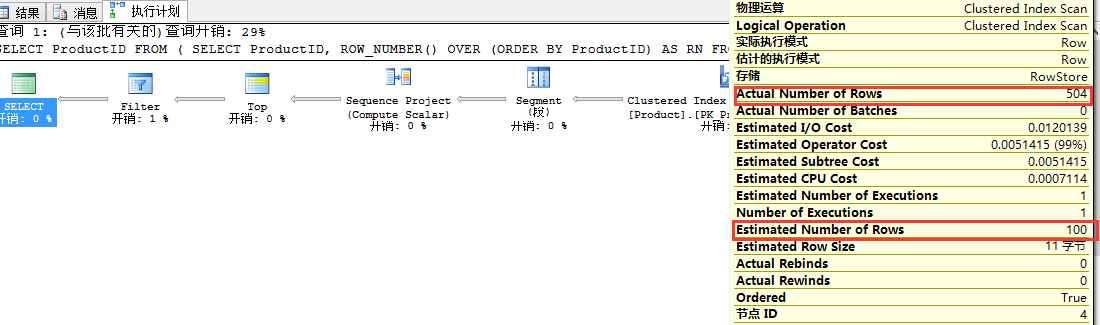
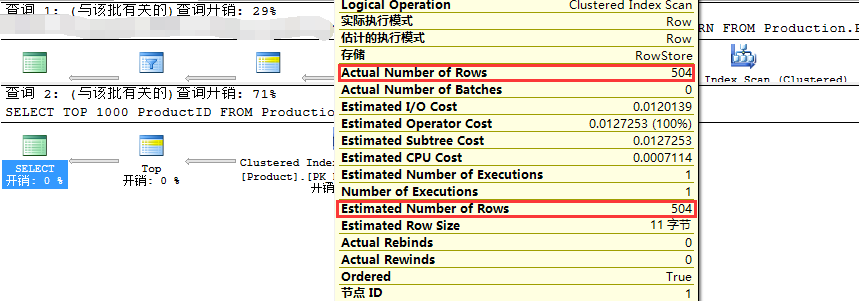
我们可以看到,使用ROW_NUMBER查询的估计行数为100,而实际数量为504,查询计划的估计成本是基于估计的行数所计算得来,即100。我们还是不能够相信估计的计划成本。 我们再来看看统计数据:

经过上面的统计,我们可以根据统计数据而做出最终决定,而不是比较执行计划的估计成本。TOP N的查询性能优于ROW_NUMBER。
总结
从上比较TOP N和ROW_NUMBER的查询得知,查询计划所得到的成本并不是判断性能的最终依据,只是基础性的判断,我们最终还得集合IO和TIME等来综合判断性能差异。
本文转自Jeffcky博客园博客,原文链接:http://www.cnblogs.com/CreateMyself/p/8138248.html,如需转载请自行联系原作者

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









