



 本文通过对比使用系统自旋锁、无锁控制及定制自旋锁的三种方式,在多线程环境下对list进行操作后的结果差异,展示了自旋锁在短时间锁定场景下能有效减少线程上下文切换带来的性能损耗。
本文通过对比使用系统自旋锁、无锁控制及定制自旋锁的三种方式,在多线程环境下对list进行操作后的结果差异,展示了自旋锁在短时间锁定场景下能有效减少线程上下文切换带来的性能损耗。
短时间锁定的情况下,自旋锁(spinlock)更快。(因为自旋锁本质上不会让线程休眠,而是一直循环尝试对资源访问,直到可用。所以自旋锁线程被阻塞时,不进行线程上下文切换,而是空转等待。对于多核CPU而言,减少了切换线程上下文的开销,从而提高了性能。)
以下是简单实例(并行执行10000次,每次想list中添加一项。执行完后准确的结果应该是10000):
foo1:使用系统的自旋锁。
foo4:不使用锁。结果必然是不正确的。
foo5:通过Interlocked实现自旋锁。
1 public class SpinLockDemo 2 { 3 int i = 0; 4 List<int> li = new List<int>(); 5 SpinLock sl = new SpinLock(); 6 int signal = 0; 7 8 public void Execute() 9 { 10 foo1(); 11 //li.ForEach((t) => { Console.WriteLine(t); }); 12 Console.WriteLine("Li Count - Spinlock: "+li.Count); 13 li.Clear(); 14 foo4(); 15 Console.WriteLine("Li Count - Nolock: " + li.Count); 16 li.Clear(); 17 foo5(); 18 Console.WriteLine("Li Count - Customized Spinlock: " + li.Count); 19 20 } 21 22 public void foo1() 23 { 24 Parallel.For(0, 10000, r => 25 { 26 bool gotLock = false; //释放成功 27 try 28 { 29 sl.Enter(ref gotLock); //进入锁 30 //Thread.Sleep(100); 31 if (i == 0) 32 { 33 i = 1; 34 li.Add(r); 35 i = 0; 36 } 37 } 38 finally 39 { 40 if (gotLock) sl.Exit(); //释放 41 } 42 43 }); 44 } 45 46 public void foo4() 47 { 48 Parallel.For(0, 10000, r => 49 { 50 if (i == 0) 51 { 52 i = 1; 53 li.Add(r); 54 i = 0; 55 } 56 }); 57 } 58 59 public void foo5() 60 { 61 Parallel.For(0, 10000, r => 62 { 63 while (Interlocked.Exchange(ref signal, 1) != 0)//加自旋锁 64 {} 65 li.Add(r); 66 Interlocked.Exchange(ref signal, 0); //释放锁 67 }); 68 69 } 70 71 public void foo6() 72 { 73 //Console.WriteLine(i); 74 //Task.Run(new Action(foo2)).ContinueWith(new Action<Task>(t => 75 //{ 76 // Console.WriteLine("foo2 completed: " + i); 77 //})); 78 //Console.WriteLine(i); 79 //Task.Run(new Action(foo2)).ContinueWith(new Action<Task>(t => 80 //{ 81 // Console.WriteLine("foo3 completed: " + i); 82 //})); 83 //Console.WriteLine(i); 84 } 85 public void foo2() 86 { 87 bool lck = false; 88 sl.Enter(ref lck); 89 Thread.Sleep(100); 90 ++i; 91 if (lck) sl.Exit(); 92 } 93 94 public void foo3() 95 { 96 bool lck = false; 97 sl.Enter(ref lck); 98 ++i; 99 if (lck) sl.Exit(); 100 } 101 }
结果如下:
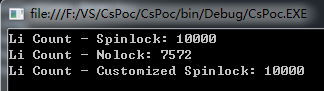


















 1788
1788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









