






 本文介绍搜索引擎的工作原理,包括两个主要步骤:建立目录和查找信息。详细解释了如何使用哈希表进行目录构建,并介绍了两种文件查找方式:蜘蛛和爬虫。此外还提供了一个用于递归查找文件的爬虫算法示例。
本文介绍搜索引擎的工作原理,包括两个主要步骤:建立目录和查找信息。详细解释了如何使用哈希表进行目录构建,并介绍了两种文件查找方式:蜘蛛和爬虫。此外还提供了一个用于递归查找文件的爬虫算法示例。
搜索引擎有两个主要步骤:
- 建立。即处理文件,导航内容并且建立目录。
- 查找。利用建立的目录进行查找,针对关键字进行查找。
要建立这样一个目录,有两种手段,一是二叉查找树,二是哈希表,searcharoo第一版为了保持简单,选择了哈希表。建议最好熟悉哈希表的建立过程,我也需要补补。
按原文,searcharoo的对象模型如下:
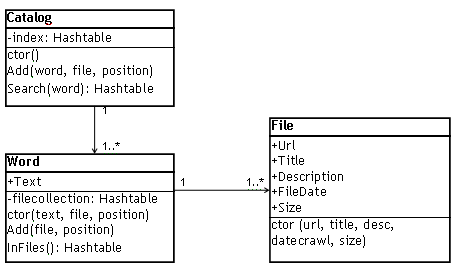
注:ctor是构造函数。
File:成员就不解释了,简单易懂。
Word:
- text:存放单词
- InFiles():返回单词所在的所有文件。
- add():向word对象中的哈希表添加File对象。
Catalog:成员就不解释了,简单易懂。
查找文件的方式有两种:
1、蜘蛛。通过在html的网页的网络链接,去查找整个网站。
2、爬虫。利用文件系统,爬一系列的文件和文件夹,找到所有的文件。但这种方式只限于locally accessible。
像google,yahoo这样的大型搜索引擎,是通过蜘蛛的方式,去建立他们的目录。通过一个链接去查找文件,要求我们去写一个html转换器,这个转换器可以找到链接并且解释它。这对于一篇文章工作量太大,所以使用爬虫的方式。
用爬虫方式查找文件,只需通过下面的递归算法可找出所有文件。

 View Code
View Code
private void CrawlPath (string root, string path) {
System.IO.DirectoryInfo m_dir = new System.IO.DirectoryInfo (path);
// ### Look for matching files to summarise what will be catalogued ###
foreach (System.IO.FileInfo f in m_dir.GetFiles(m_filter)) {
Response.Write (path.Substring(root.Length) + @"\" + f.Name + "<br>");
} // foreach
foreach (System.IO.DirectoryInfo d in m_dir.GetDirectories()) {
CrawlPath (root, path + @"\" + d.Name);
} // foreach
}
System.IO.DirectoryInfo m_dir = new System.IO.DirectoryInfo (path);
// ### Look for matching files to summarise what will be catalogued ###
foreach (System.IO.FileInfo f in m_dir.GetFiles(m_filter)) {
Response.Write (path.Substring(root.Length) + @"\" + f.Name + "<br>");
} // foreach
foreach (System.IO.DirectoryInfo d in m_dir.GetDirectories()) {
CrawlPath (root, path + @"\" + d.Name);
} // foreach
}
未完待续。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









