






 本文介绍了一种使用ABBYY FineReader 12将PDF文件转换为HTML网页格式的简便方法。该软件支持自动化处理,能够快速识别PDF内容并转换为可编辑、可搜索的HTML格式,适合需要将大量PDF资料快速转化为网页形式的用户。
本文介绍了一种使用ABBYY FineReader 12将PDF文件转换为HTML网页格式的简便方法。该软件支持自动化处理,能够快速识别PDF内容并转换为可编辑、可搜索的HTML格式,适合需要将大量PDF资料快速转化为网页形式的用户。

将PDF转换成HTML网页格式,是快速打造专业级网站的方法之一。当用户找到了非常详实的PDF资料,打算将之制作成为网页格式时,如果重新开发 往往需要耗费大量的时间,可是又不知道怎么样才可以将PDF文件转换成HTML网页格式,此时如果能够借助PDF转换器工具来进行处理,效率将得到大幅提升。
这里重点给大家介绍一款简单易用的OCR文字识别软件:ABBYY FineReader 12,这款软件可快速、方便地将扫描纸质文档、PDF文件和数码相机的图像转换成可编辑、可搜索的文本,其中就包括HTML网页格式。
那么如何使用ABBYY FineReader 12将PDF转换成HTML呢?方法如下:
1、打开ABBYY FineReader 12,在任务首页上点击‘其他’,然后选择图像或PDF文件到HTML;
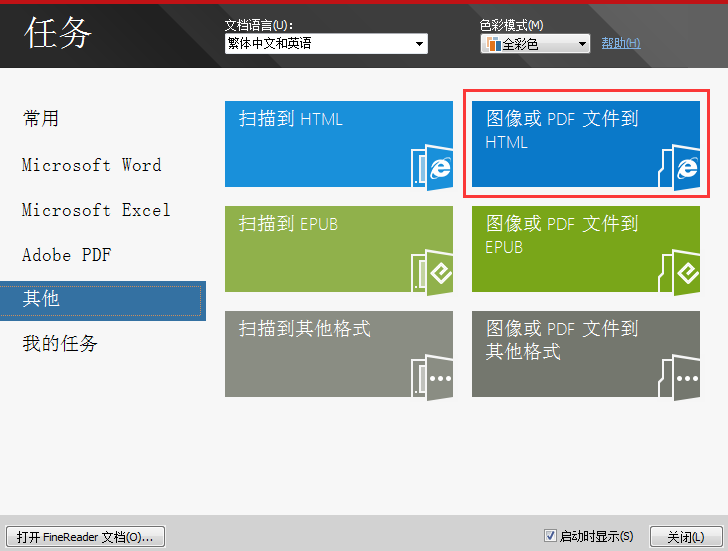
2、在打开图像对话框中选择要转换为HTML的PDF文件,点击打开;
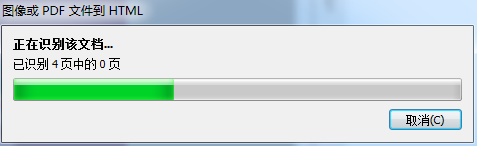
3、打开PDF文件之后,软件会自动识别PDF文件,等待识别过程,识别完成之后会自动生成HTML页面,整个过程全自动,无需任何手动操作;
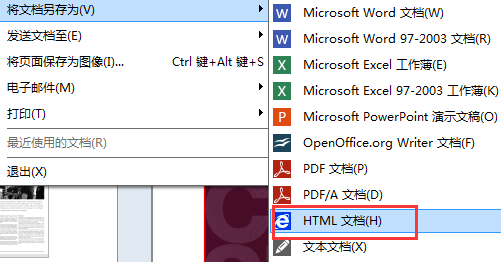
4、如果发现转换之后的HTML网页与原PDF文件有个别不一致的地方,可以返回到软件,第3步中识别之后的文档会在屏幕右侧显示,这里的文档是可以编辑的,可对照原PDF文件进行校对修改,再点击文件选项卡,在‘将文档另存为’下拉列表中选择HTML文档,保存即可。
使用ABBYY FineReader 12的好处是,整个转换过程快速自动化,无需专业知识就能获得想要的结果,是你的办公必备产品,如果你还想了解更多关于ABBYY FineReader 12这款OCR文字识别软件的内容,大家可前往那个ABBYY中文网了解相关信息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









