



 本文探讨了在VSCode中调试Promise时遇到的错误,并详细分析了错误原因。该问题出现在使用koa框架并大量依赖Promise、async和await时。文章提供了代码示例,并给出了解决方案:调整VSCode的调试设置。
本文探讨了在VSCode中调试Promise时遇到的错误,并详细分析了错误原因。该问题出现在使用koa框架并大量依赖Promise、async和await时。文章提供了代码示例,并给出了解决方案:调整VSCode的调试设置。
vscode
版本 1.19.2
提交 490ef761b76b3f3b3832eff7a588aac891e5fe80
日期 2018-01-10T16:16:25.767Z
Shell 1.7.9
渲染器 58.0.3029.110
Node 7.9.0
架构 ia32
昨天在使用vscode写node后台服务的时候出现了一个莫名其妙的bug:代码执行到promise内部,然后执行reject的时候vscode产生断点报错。通过命令行启动程序不会报错,但是通过vscode F5启动调试就会出现这个错误。
因为后台框架使用的是koa,所以大量的使用了Promise、async和await,然后就出现了这个问题,代码如下
checkLogin: async (ctx, next) => { ctx.status = 200 try { let decoded = await checkToken(ctx.request.body.token) ctx.body = JSON.stringify({state: 'OK'}) } catch(err) { console.log(err) ctx.body = JSON.stringify({error: err}) } } /** * 检查token是否可用 */ checkToken: (token) => { return new Promise((resolve, reject) => { if (token) { jwt.verify(token, 'zyx', (err, decoded) => { //解码token if (err) { return reject(err) } resolve(decoded) }) } else { reject('NO_TOKEN') } }) }
然后代码运行时报错如下(jsonwebtokenerror是err的类型,可以无视,因为不管reject传入的是什么,都会报相应数据类型的异常错误)
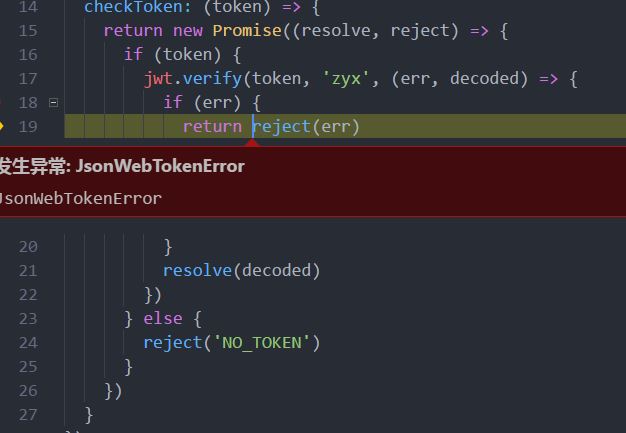
而且经过测试,不管在promise的何处调用reject都是会报相同的错误
最后在google上找到了具体的答案,连接在此
原文的解释是:
If a promise is rejected before an error handler is attached, the debugger will break, even if only "uncaught exceptions" is checked. If it's rejected after the error handler is attached, it works as expected. And really the problem is the way the promise doesn't know whether its rejection will be handled or not.
大致的意思就是说:
如果在promise处理异常之前就执行了jeject,vscode就会认为这个promise没有处理异常的过程,然后就报错了。
换句话说只要没有在promise的后面紧跟.catch或.then处理异常就会触发这个错误机制。而且不能在同步过程中触发reject,因为这个时候异常处理还没有挂载到promise上
最后关于这个问题的解决方法:
这个问题应该算是vscode的一个关于js promise 的 bug,而我的代码是没有问题的,没有必要为了避免这个异常断点而hack来写代码。所以直接修改vscode的断点机制就可以了。
打开vscode的调试工具栏

然后在左下角取消选中 ‘未捕获的异常’ 选项
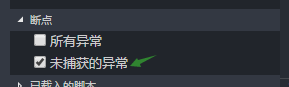
这样就解决了问题。

















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









