




继续以前的博客写,之前一直说要写一个实例,今天终于有机会了。。。
http://my.oschina.net/zimingforever/blog/181206
http://my.oschina.net/zimingforever/blog/185763
先进行一下问题描述,今天下午线上应用访问特别卡,最后应用都刷不出来,上机器查,两个节点,主备关系,前面有负载均衡设备。
TOP一下,其中主节点的CPU彪到200%,内存1.8G,另一个节点CPU和内存都正常。怀疑主节点内存泄露或者gc导致。
解决方案,第一步先立刻关掉主节点,这时候备节点CPU和内存都飙升。
然后没办法重启主节点,这时候备节点load依旧很高。
接下来干脆主备都同时重启,这时候两个节点的load比较平均。
不过没过多久其中一个节点的CPU和内存又飙升上去。
果断dump内存
jmap -dump:format=b,file=heap1.bin 3148然后先停掉后面的一个调用服务,这时候应用正常启动。但是由于后面的调用服务停掉,所以后面的服务还是没有启动的。
然后本地用Memoery analyzer tool查看下载下来的bin文件,发现如下情况
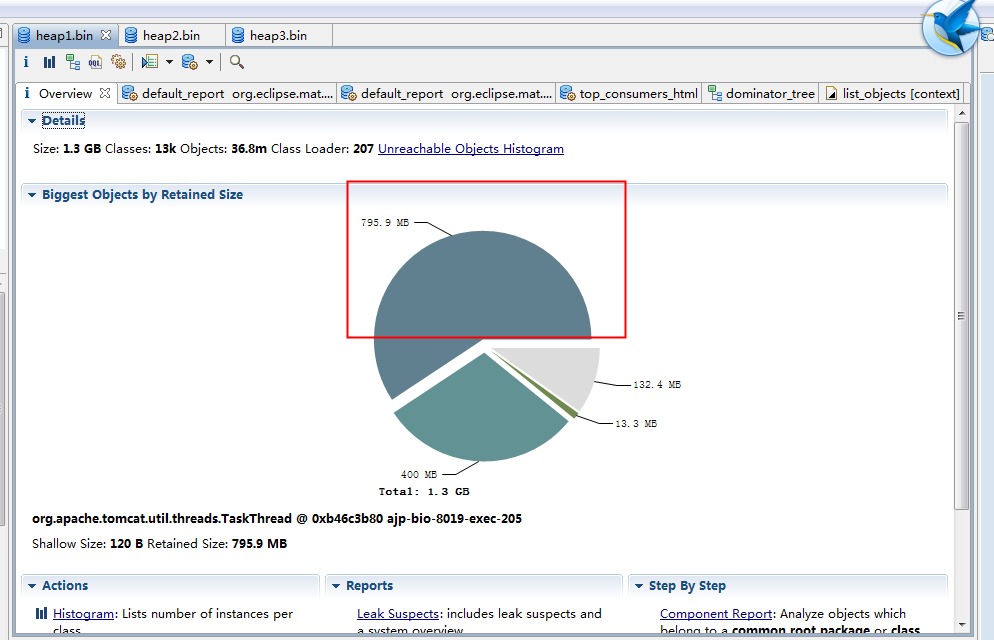
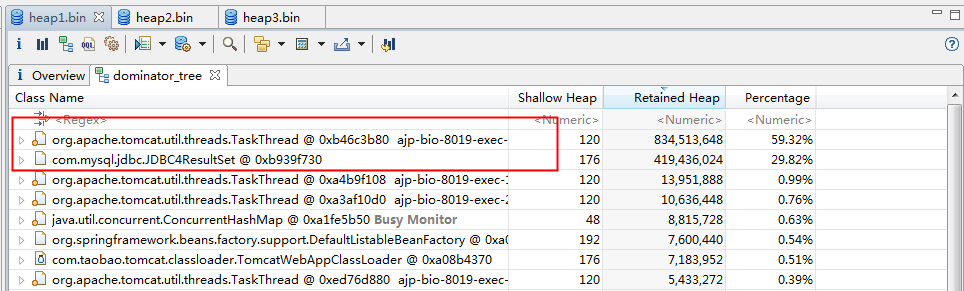
然后查看dominator tree 来找到内存中的大对象,可以看到前两个对象占了很大一部分比列
打开内容,发现里面是20W个相同的json串,json串的内容正好是一个表的字段结构,于是感觉是因为某个查询返回的结果把内存撑爆了(其实我们的preparestament都是有查询限制的,大查询基本上都采用分页查询)
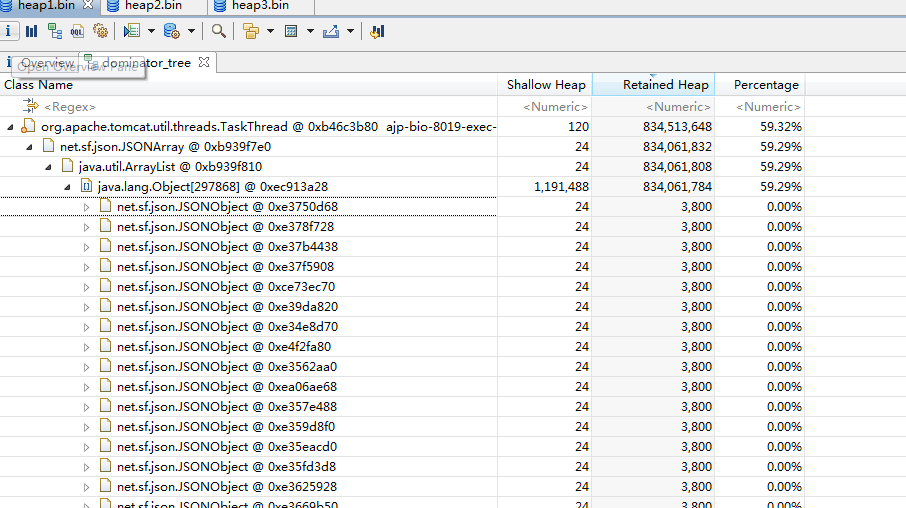
打开JSONobject,里面对应的是表的结构

这样就好判断多了,有两个表结构,我们去反查那张表,找到了对应的表再去找对应的执行历史,但是发现这个执行历史中没有这个执行数据。。。奇怪了。。。
这时候应用和后台服务都起来了。机器负载稳定。
于是先吃个饭,在回来慢慢发现问题。终于在内存中找到了相关的执行sql
update XXX set hash_code=1 ,gmt_modified=now() where biz_type='CFP_CHARGE' and status <5 order by gmt_create limit 2000 ;这个sql是一个upate语句是不会返回那么多结果集的,于是继续找,找到了如下sql
select /*idb_dml_bak*/ * from XXX where biz_type = 'CFP_CHARGE' AND status < 5这个sql其实是用来对上面update语句做备份的,一眼就看出问题了,limit 2000没有了,count下发现有53多W数据。估计就是这50多万数据放到内存中把内存撑爆了
另外这里提一下,update 后面加limit的语法是对的。
另外今天使用的是mat这个工具,还有一个很强大的jprofiler今天也顺便用了一下。感觉功能很多,用起来略微复杂了。
还有,今天只dump了内存数据,其实在解决类似问题的时候需要dump一份 threaddump
首先找到相应的pid
ps -ef | grep java然后使用jstack命令
sudo jstack 18933也可以把内容打到文件里
sudo jstack 18933 >>/home/xiaoming.wm/threaddump.txtwindow里可以使用
psexec -s jstack <pid> >> threaddumps.log可以参考 http://www.ibm.com/developerworks/cn/websphere/library/techarticles/0903_suipf_javadump/
http://blog.youkuaiyun.com/rachel_luo/article/details/8920596
/**
2014.01.26
*/
这里补充一下,dump出来的文件大概有1.7G,用MAT32位版是打不开的(设置最大内存也不行),后来下载了64位版本的。感谢本机SSD和8g内存,大概5分钟就打开了dump文件,同事是普通硬盘,打了一个多小时还是没打开文件。
总结一下,今天第一次用java profile工具解决了一个线上的内存问题。以后遇到线上机器性能问题可以仔细看看dump文件说不定就能找到相关问题。

















 1831
1831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









