






 探讨了机器学习模型在贷款等场景中的应用与潜在偏见问题,介绍了伯克利AI研究协会提出的方法来解决由此产生的不公平性。
探讨了机器学习模型在贷款等场景中的应用与潜在偏见问题,介绍了伯克利AI研究协会提出的方法来解决由此产生的不公平性。

近期频频登上头条的几项研究大多如此:比如利用算法识别犯罪团伙或者,利用图像识别判定同性恋。
这些问题的出现往往是因为历史数据中的偏差特征,比如种族和性别上的小众团体,往往因此在机器学习预测中产生不利的歧视结果。在包括贷款,招聘,刑事司法和广告在内的各种广泛使用AI的领域,机器学习因其预测误差伤害到了历史上弱势群体,而广受诟病。
本月,在瑞典斯德哥尔摩举行的第35届机器学习国际会议上,伯克利AI研究协会发布了一篇论文,来试图解决这一问题。

这篇文章的主要目标,是基于社会福利的长期目标对机器学习的决策进行了调整。
通常,机器学习模型会给出一个表述了个体信息的分数,以便对他们做出决定。 例如,信用评分代表了一个人的信用记录和财务活动,某种程度上银行也会根据信用评分判断该用户的信誉度。本文中将继续用“贷款”这一行为作为案例展开论述。
如下图所示,每组人群都有信用评分的特定分布。
信用评分和还款之间的分布
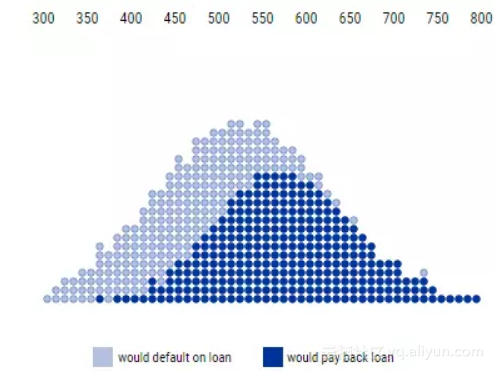
上图中,最上面的数字表示信用评分,评分越高表示偿还能力越强。每一圆圈表示一个人,深蓝色的圆圈表示将会偿还贷款的人,浅蓝色的圆圈表示将会拖欠贷款的人。
通过定义一个阈值,就可以根据信用评分进行决策。例如,向信用评分超过阈值的人发放贷款,而拒绝向信用评分低于阈值的人发放贷款。这种决策规则被称为阈值策略。
信用评分可以被解释为对拖欠贷款行为的估计概率。例如,信用评分为650的人中估计有90%的人可能会偿还他们的贷款。
银行就可以给信用评分为650的个人发放相同的贷款,并获得预期的利润。同样,银行可以给所有信用评分高于650的个人发放贷款,并预测他们的利润。
贷款阈值和盈亏结果
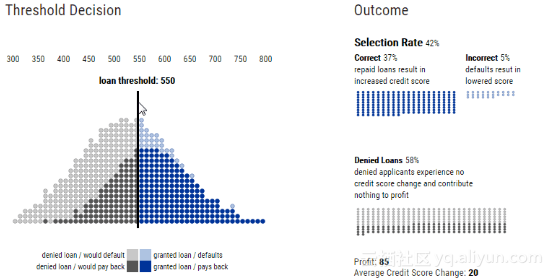
不考虑其他因素,银行肯定会最大化自己的总利润。利润取决于银行从偿还贷款中获得的金额与从拖欠贷款中损失的金额之比。在上面的动图中,营收与亏损的比率的取值是-4~1。
当损失的成本相对高于收益成本时,银行会更保守地发放贷款,并提高贷款阈值。我们称信用评分超过该阈值的人群比例为选择率(selection rate)。
信用评分变化曲线
是否发放贷款的决策不仅影响机构,而且影响个人。违约事件(借款人未能偿还贷款)不仅会让银行损失利润,也降低了借款人的信用评分。
按时偿还贷款的行为会为银行带来利润,同时也会增加借款人的信用评分。在本文的示例中,借款人信贷评分变化率为-2~1,-2表示拖欠贷款,1表示偿还贷款。
对于阈值策略,评分结果(outcome)的定义是人群信用评分的预期变化,也是选择率函数的一个参数,我们称这个函数为结果曲线。每组人群的选择率不同,信用评分曲线也不尽相同。

















 2309
2309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









