



 本文介绍了一个使用Python3和Requests库实现的多线程爬虫实例,该爬虫能够从特定网站抓取视频资源链接,并利用正则表达式提取下载地址,最终将数据存储至MongoDB数据库。
本文介绍了一个使用Python3和Requests库实现的多线程爬虫实例,该爬虫能够从特定网站抓取视频资源链接,并利用正则表达式提取下载地址,最终将数据存储至MongoDB数据库。
- 一个比较简单,python3多线程使用requests库爬取都挺好,并使用正则提取下载链接,保存到mongodb
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author:Aiker Zhao
@file:doutinghao.py
@time:下午8:18
"""
import requests
import re
import pymongo
from multiprocessing import Pool
MONGO_URL = 'localhost:27017'
MONGO_DB = 'doutinghao'
MONGO_TABLE = 'doutinghao'
client = pymongo.MongoClient(MONGO_URL, connect=False)
db = client[MONGO_DB]
def get_result(url):
response = requests.get(url).text
# print(reponse.text)
pattern = re.compile('<a href="(ed2k.*?)"\srel.*?title="(.*?.mp4).*?".*?>', re.S)
result = re.findall(pattern, response)
if result:
for i in result:
url, name = i
yield {
"name": name,
'url': url
}
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print('存储到MongoDB成功', result)
return True
return False
def main(result):
# result = get_result(url)
save_to_mongo(result)
if __name__ == '__main__':
pool = Pool()
url = "https://www.xl720.com/thunder/34283.html"
item = [item for item in get_result(url)]
# print(item)
pool.map(main, item)
pool.close()
pool.join()
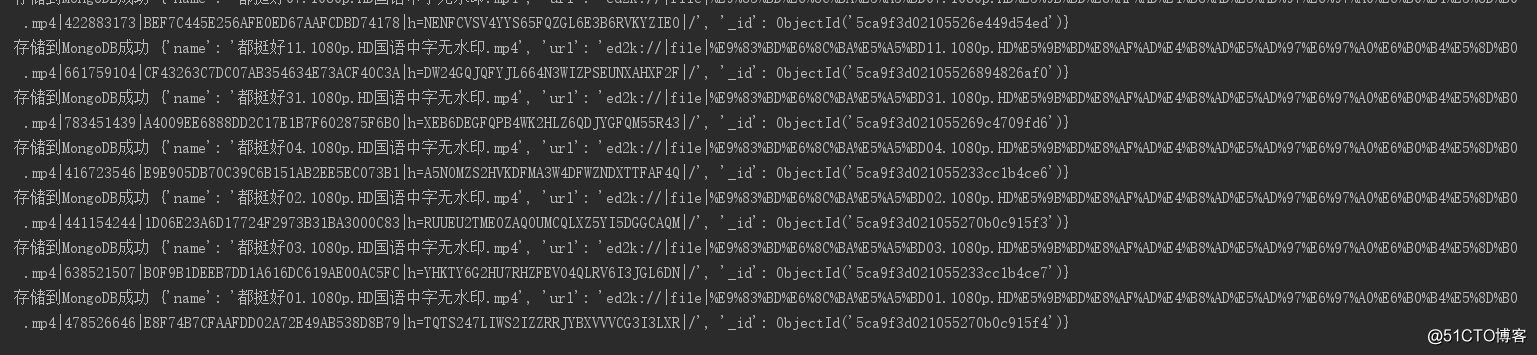
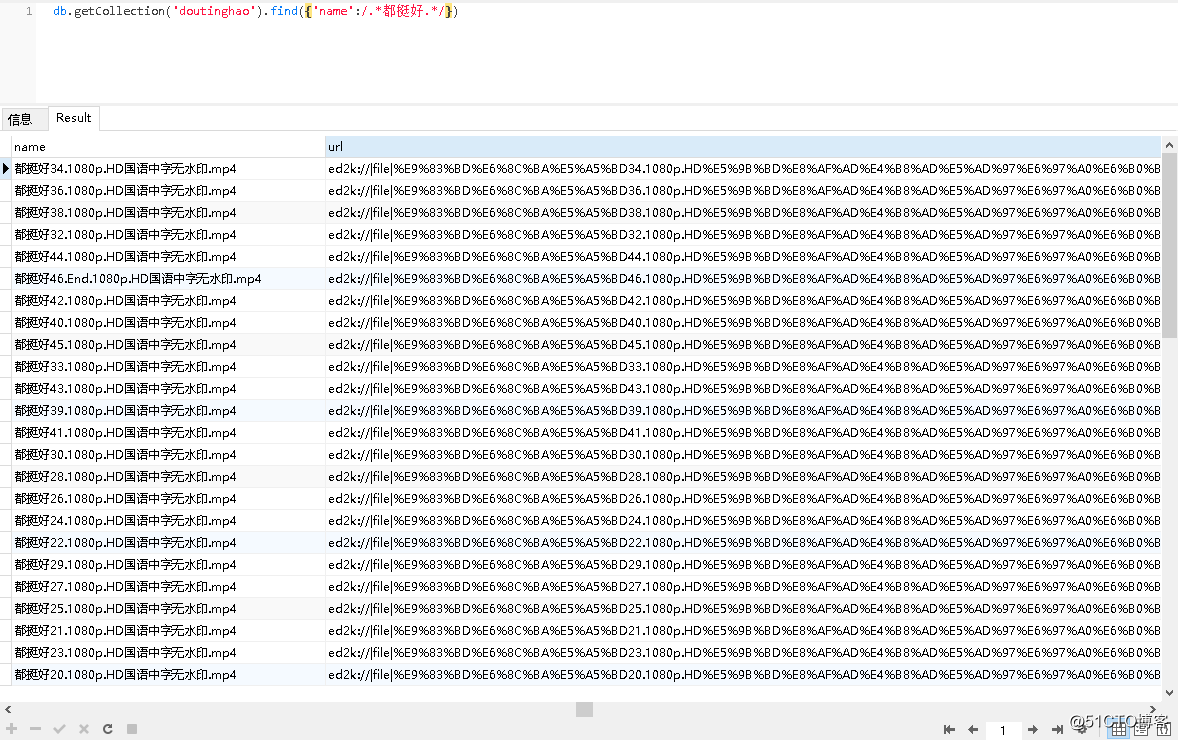
转载于:https://blog.51cto.com/m51cto/2375053

















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









