



 XenServer7.0通过在tapdisk3中实施轮询技术显著提高了存储I/O性能,实测单线程顺序读取IOPS从15,000提升至22,500。轮询技术避免了事件驱动方式中的中断及调度延迟,尤其适用于现代低延迟存储设备。
XenServer7.0通过在tapdisk3中实施轮询技术显著提高了存储I/O性能,实测单线程顺序读取IOPS从15,000提升至22,500。轮询技术避免了事件驱动方式中的中断及调度延迟,尤其适用于现代低延迟存储设备。
本文翻译自:http://xenserver.org/discuss-virtualization/virtualization-blog/entry/dundee-tapdisk3-polling.html
在XenServer 7.0版本中,我们实现了若干性能和扩展性的显著提升。本文是介绍这一系列提升的第一篇文章。
首先是关于存储I/O性能提升。在XenServer中,tapdisk3负责处理虚拟存储设备I/O,我们采用了轮询的技术以提升其性能。在我们的测试场景中,相比非轮询方式,虚拟存储I/O性能提升了50%,由15,000 IOPS提高到了22,500 IOPS。
什么是轮询?
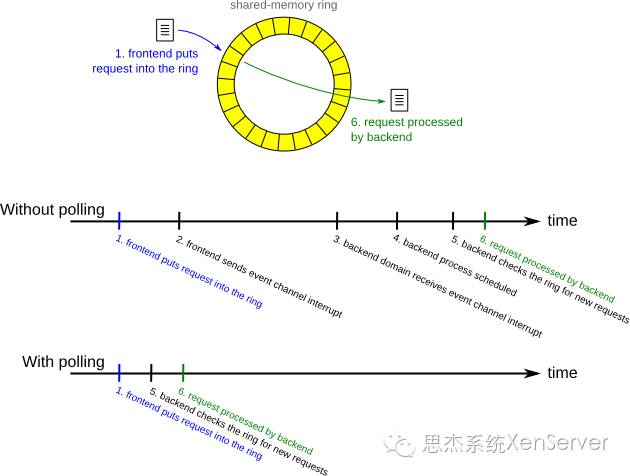
通常,tapdisk3以事件驱动的方式运行。以下是虚拟机进行存储I/O操作的步骤:
虚拟机的半虚拟化存储驱动(前端驱动,在Linux虚拟机中为blkfront,在Windows虚拟机中为xenvbd)在环(ring)中放入一个请求。该环由虚拟机和domain 0共享。
驱动通过事件通道(event-channel)给tapdisk3发送一个通知。
该通知由Xen以中断的形式送达domain 0。domain 0需要被调度以接受该中断。
当接收到中断,domain 0内核调度相应的后端进程即tapdisk3来处理。
tapdisk3检查共享内存环。
最后,tapdisk3发现该存储I/O请求并交由物理I/O处理。
轮询是另一种处理方式,tapdisk3循环地检查环以获取新的请求。这样可以跳过以上步骤2-4:不需要等待消息通道中断,也不用等待tapdisk3被调度因为它已经在运行。这样tapdisk3可以更迅速地处理I/O请求因为消息驱动方式带来的延迟被避免了。
下图为两种处理方式在时间轴上的对比,清楚地展示了轮询方式大大降低了从虚拟机发起存储I/O请求到被后端驱动处理所花费的时间。
轮询如何提升提升存储I/O性能?
轮询技术用于降低事件驱动系统的延迟。(另一个例子是Linux网络驱动采用NAPI来缓解中断造成的延迟。)
要提升I/O性能,必须及时地处理I/O请求,降低延迟是保证较低虚拟化开销的关键。因为物理I/O设备越来越快,任何在虚拟化层面的延迟都会越来越显著并导致吞吐率的降低。
从虚拟机到物理存储设备的I/O的请求路径很长,tapdisk3采用轮询可以优化此路径。
轮询会过度占用CPU并导致负面影响吗?
这的确会发生,所以我们要非常小心地处理,否则轮询会占用大量domain 0的CPU时间片,使其他进程得不到及时处理从而导致系统整体性能下降。
我们采用以下两种措施来避免过度占用CPU:
只有当存储I/O请求发生概率较大时才进行轮询。虚拟机的行为是无法预测的,但是遵循一些原则可以让我们在恰当的时机进行轮询。例如,我们会在虚拟机存储I/O请求发生后轮询一小段时间,因为当虚拟机发起一个请求后很可能在短时间内再度发起请求。如果的确发现了新的请求,轮询更长一些时间以处理更多的请求。但如果一段时间内不再有存储I/O请求,我们就暂停轮询并切换到事件驱动的处理方式。
当domain 0很忙的时候不进行轮询。因为轮询会大量消耗CPU时间片,只有当确保其他需要CPU时间片的进程不会被过度影响时才进行轮询。
存储I/O会快多少?
采用轮询方式获得的存储I/O性能提升主要取决于物理存储设备的延迟。如果是老式的机械硬盘或是NFS,仅在虚拟化层面因轮询路径缩短而节省的数微秒不会带来太大的变化。但是对于现代存储设备和低延迟的网络存储设备,轮询会来带可观的速度提升。尤其当处理的存储I/O请求粒度较小时,因为粒度越小对延迟越敏感。
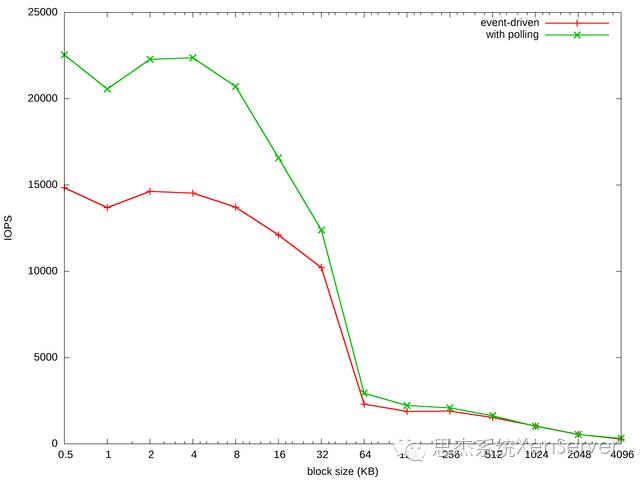
如下图所示,单线程顺序进行存储I/O读取,对于较小的粒度,采用轮询带来了50%的性能提升-从15,000 IOPS提高到22,500 IOPS。测试工具为iometer,虚拟机为32位Windows 7 SP1,物理机为Dell PowerEdge R730xd,存储设备为Intel P3700 NVMe。
轮询具体实现?
请参见https://github.com/xapi-project/blktap/pull/179/commits
转载于:https://blog.51cto.com/kaiqian/1811270

















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









