



 本文展示了一个简单的Python爬虫示例,用于从豆瓣网站抓取活动信息。通过使用正则表达式匹配特定HTML标签来抽取活动名称。
本文展示了一个简单的Python爬虫示例,用于从豆瓣网站抓取活动信息。通过使用正则表达式匹配特定HTML标签来抽取活动名称。
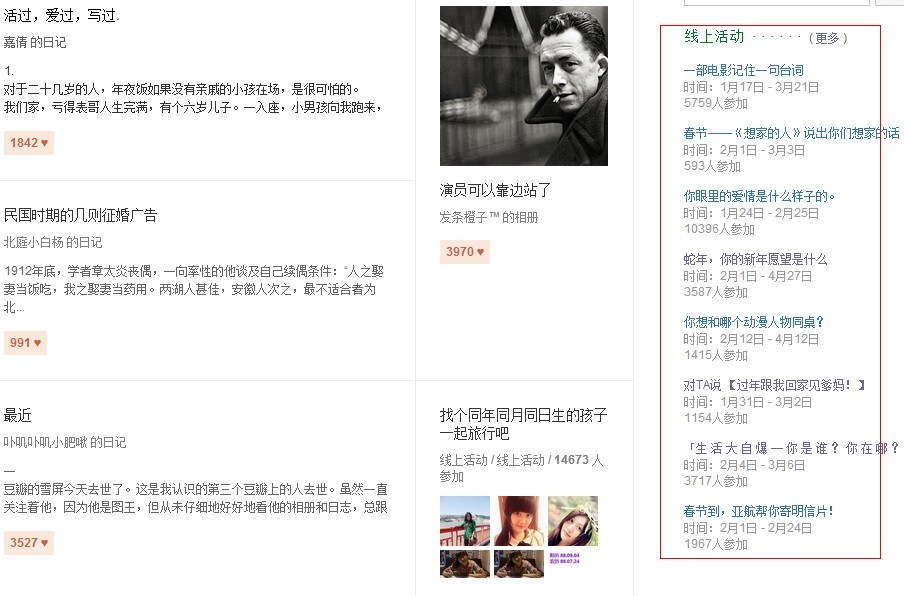
比如你抽取右边的活动
代码段如下:
import re #正则类 from urllib import urlopen #提取内容类 #打开链接 webpage = urlopen("http://www.douban.com") #提取读取内容 info = webpage.read() #正则匹配 party = re.findall("<a.href=\"http://www.douban.com/online/[0-9]+.\">(.{1,50})</a>",info) if len(party)>0: for x in xrange(len(party)):print party[x]
效果如下:
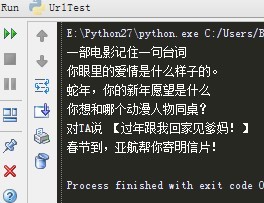

















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









