




中文分词有很多算法,同时大都是基于四种基本的分词方式,在基本的分词基础上做一些歧义消除、未登录词识别等功能。
下面以“南京市长江大桥”为例,分享一下四种基本的分词
正向最大匹配
从字面就很好理解,就是一句话从头开始读,可着最长的词取。
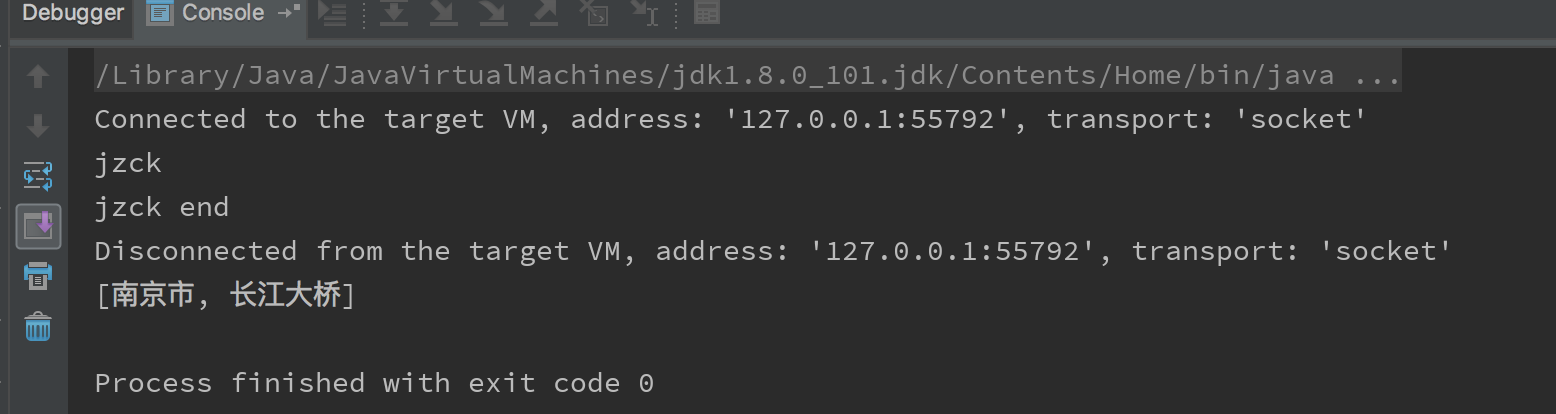
// 南京市长江大桥 --> 南京市 长江大桥
代码
List<Word> segmentation(String text) {
Queue<Word> results = new LinkedList<>();
int textLength = text.length();
// 设置词的最大长度,词库中最长词的长度跟目标句子长度中,取最小
int wordMaxLength = min(DictionaryFactory.getDictionary().getMaxWordLength(), textLength);
int start = 0; // 开始分词的位置
while (start < textLength) {
int currentLength = min(textLength - start, wordMaxLength); // 未分词的句子长度
boolean isSeg = false;
while (start + currentLength <= textLength) {
if (DictionaryFactory.getDictionary().contains(text, start, currentLength)) {
addWord(results, text, start, currentLength); // 成功分词 加入results中
isSeg = true;
break;
} else if (--currentLength <= 0) { // 剩余长度为0 跳出当前循环
break;
}
}
if (isSeg) {
start += currentLength;
} else {
addWord(results, text, start++, 1); // 没有分出词 单字成词
}
}
return new ArrayList<>(results);
}结果
正向最小匹配
跟上边的正好形成对比,这个也是正向,但是是可着最小的词先分
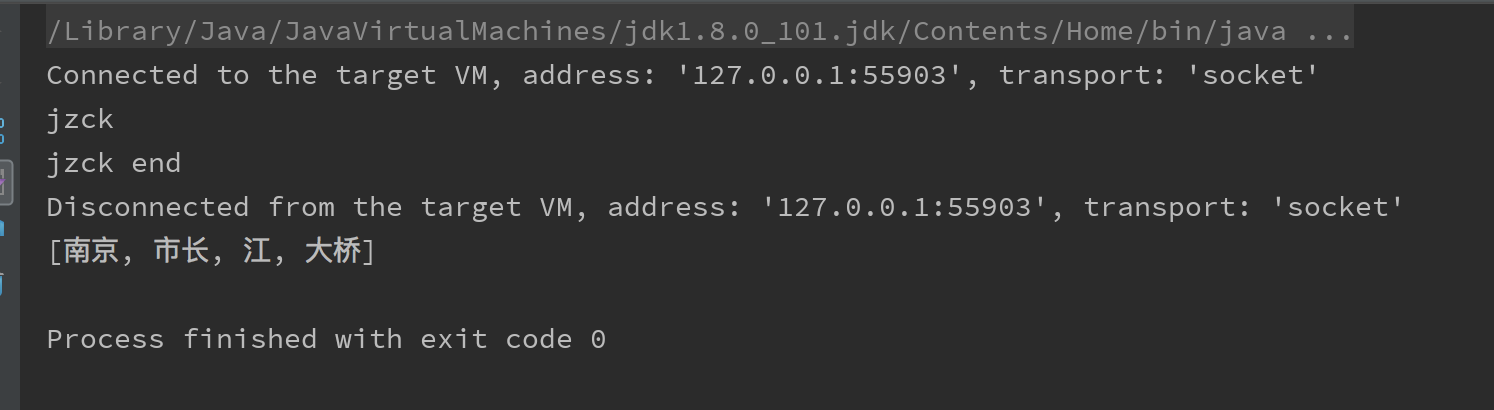
// 南京市长江大桥 --> 南京 市长 江 大桥代码
List<Word> segmentation(String text) {
Queue<Word> results = new LinkedList<>();
int textLength = text.length();
int wordMinLength = 2; //最小词长 这里不考虑单字的词
int start = 0;
while (start < textLength) {
int currentLength = wordMinLength; // 从start处开始 从长度为2开始查找可分的词
boolean isSeg = false;
while (start + currentLength <= textLength) {
if (DictionaryFactory.getDictionary().contains(text, start, currentLength)) {
addWord(results, text, start, currentLength);
isSeg = true;
break;
} else if (++currentLength > DictionaryFactory.getDictionary().getMaxWordLength()) { // 没有的话就让currentLength+1,如果大于词典中最长的词就跳出循环
break;
}
}
if (isSeg) {
start += currentLength;
} else {
addWord(results, text, start++, 1);
}
}
return new ArrayList<>(results);
}结果
逆向最大匹配
也是可着最大的词先分,不过是从后往前开始分
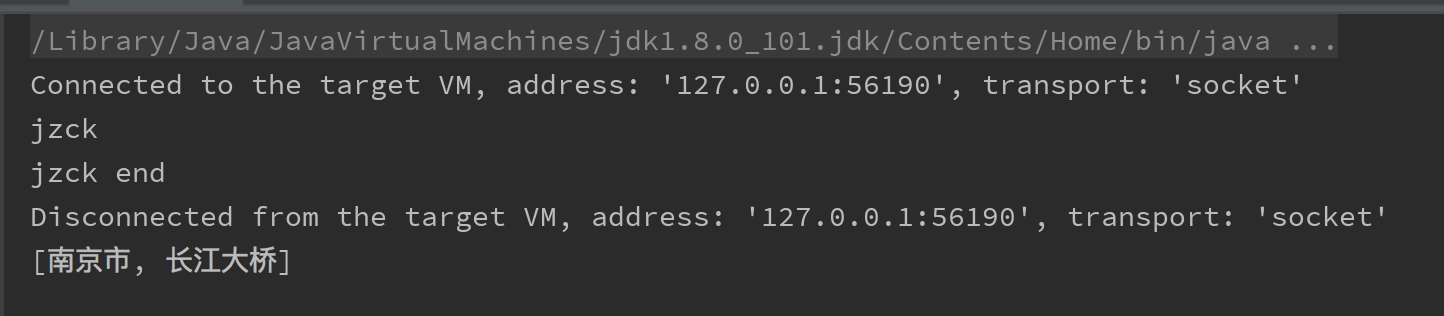
// 南京市长江大桥 --> 南京市 长江大桥代码
public List<Word> segmentation(String text) {
Deque<Word> results = new ArrayDeque<>();
int wordMaxLength = min(DictionaryFactory.getDictionary().getMaxWordLength(), text.length());
int end = text.length();
while (end > 0) {
int currentLength = min(wordMaxLength, end);
boolean isSeg = false;
while (end - currentLength >= 0) {
if (DictionaryFactory.getDictionary().contains(text, end - currentLength, currentLength)) {
addWord(results, text, end - currentLength, currentLength);
isSeg = true;
break;
} else if (--currentLength <= 0) {
break;
}
}
if (isSeg) {
end -= currentLength;
} else {
addWord(results, text, --end, 1);
}
}
return new ArrayList<>(results);
}结果
逆向最小匹配
正向最小匹配倒过来即可
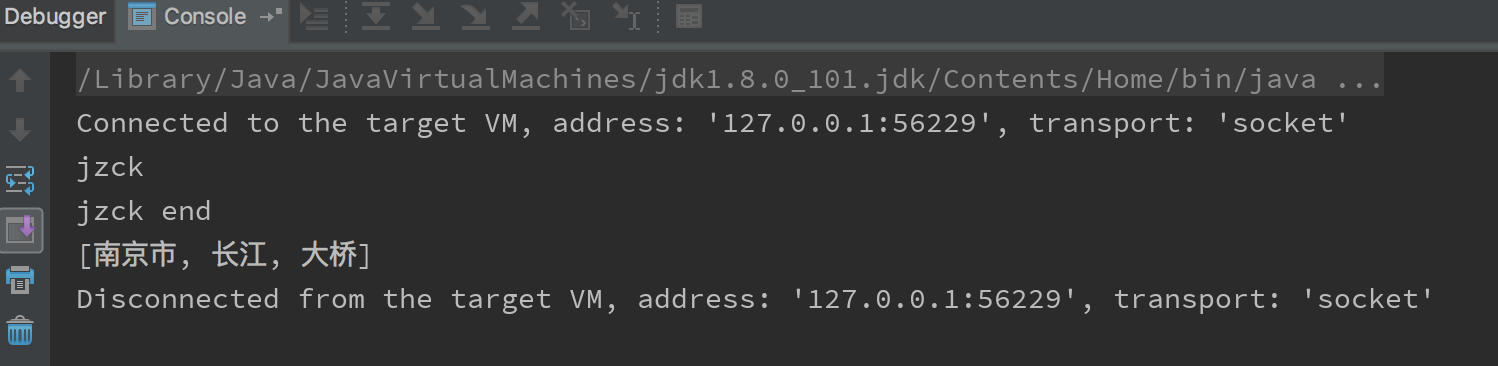
// 南京市长江大桥 --> 南京市 长江 大桥代码
public List<Word> segmentation(String text) {
Deque<Word> results = new ArrayDeque<>();
int wordMinLength = 2;
int end = text.length();
while (end > 0) {
int currentLength = wordMinLength;
boolean isSeg = false;
while (end - currentLength >= 0) {
if (DictionaryFactory.getDictionary().contains(text, end - currentLength, currentLength)) {
addWord(results, text, end - currentLength, currentLength);
isSeg = true;
break;
} else if (++currentLength > DictionaryFactory.getDictionary().getMaxWordLength()) {
break;
}
}
if (isSeg) {
end -= currentLength;
} else {
addWord(results, text, --end, 1);
}
}
return new ArrayList<>(results);
}结果

















 1736
1736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









