




最近看了一些关于mysql中索引的内容,以下的内容都是自已的理解,不正确的地方欢迎指正。
什么是索引
索引的英文名字叫index(食指),就是指引的意思。如果把数据库比为一本书的话,索引就相当于书的目录,它存在的意义就是使得我们查找信息的时候更加的快。
为什么需要索引
上面提到过,索引之于数据库如同目录之于书本。就如同我们在查阅一本书的时候,如果我们在一本没有目录的书本上查找一个具体的信息,而且非常不幸的是我们还是第一次拿到这本书,对书中的内容和组织方式几乎是一无所知,那我们要查找这个具体的信息需要怎么做呢?
当然,如果你的运气足够好的话,可能随便一翻就直接到相关页了,但你如果运气不够的话,恐怕最明智和几乎唯一保险的做法就是从第一页一直翻到最后一页,如果很不幸的,你要查找的信息正好在书的最后一页,恐怕你在没有通读全书之前是不会找到你要的东西的。
数据库也是一样,如果一张表对应于一本书,那如果不设置索引,那要找到一条记录,就不得不从头到尾的查找数据库的第一条记录,不过这种操作我们有一个更专业的叫法称为全表扫描。
但如果把数据库加上了索引,就等于一本书加上了目录,说白了就是告诉我们需要的数据在数据库哪里放着。之前我们需要把书读一遍才能查找到需要的信息,现在只需要读目录的对应章节就可以了。想到这里是否还有点小激动呢?
索引的存储
在mysql中,不同的引擎存储索引的结构是不同的,我们只举最常用到的两个存储引擎:MYISAM和INNODB两种存储。
在MYISAM存储引擎中,索引是单独作为一个文件存储的,而在INNODB存储引擎中,索引是和数据库的数据存储在一起的。
索引的数据结构
目前的索引类型根据数据结构划分大致可以分为全文索引、哈希索引和B+树索引。
全文索引是在MYISAM存储引擎下才能创建的索引,这里不做讨论。
而对于最经常使用的索引,恐怕哈希索引和B+树索引才是使用的最多的。
B+树索引
B+树索引在数据结构上讲是一个B+树(废话)。它本质上讲是一棵树。但这个树有一定的特点,主要有以下:
1.这个树的度通常是非常大的(通常1000多都是正常的)
2.这个树的高度一般是很低的。
3.这是一棵平衡树,不会在增加索引内容的过程中一条分支数据过多而另一条分支几乎没有数据。
为什么要这样设计呢?主要原因就是为了效率。查找数据的过程是寻道+读取数据两个过程的和。说白了,就是知道去哪里找数据+把数据读取出来的过程之和。从目前的数据的存储来看,寻道(查找数据的存储位置)的时间占了大头。而寻道的时间是由查找的次数来决定的,而在B+树中所有的索引数据都是存储在叶结点上的,因此从根结点到叶结点所走的次数(也就是树的高度)就是寻道的次数,也就决定了数据的查找效率。所以我们一切的努力都是为了2特点服务的。
哈希索引
哈希索引就是一个字典结构。它会把要存入的所有数据都计算一个哈希值,然后做一个映射。当我们要查找一个数据的时候,只要知道这条数据的哈希值的话,就可以直接通过映射关系找到这条数据。
哈希索引非常适合哈希值不重复且一次只查找一条数据的情况。但如果发生了哈希值重复的情况,那重复的这些数据就会以链表的形式存储在哈希值指向的区域内,要获取指定的数据就只能遍历这个链表了。
而如果查找的不是一条数据而是一个范围内的数据,那因为哈希值是分散的形式存储的,那索引就完成没有作用了。
索引的创建
在mysql数据库中,创建一条索引是非常容易的,我们以一张如下的表为例:
create table idx_student(
id int unique not null,
name varchar(30) not null,
age tinyint ,
score int
);创建索引:
alter table idx_student add index idx_name (name);
这样在idx_student表上就创建了一个以字段name为查找字段的索引。我们可以看下表idx_student的索引:
show index from idx_student;
在我的电脑上显示的结果如下

这时候会很奇怪,明明只创建了一个name字段的索引,怎么还会在id上也创建一个索引呢?因为在INNODB存储引擎下,如果没有显式的创建索引,那么它会自动找唯一的字段自发的创建一个索引(很有些雷锋精神)。
添加索引的性能优化
添加索引在性能上的优化在上面只是说了一说,现在我们就切实的感受下它的威力。
还是以上面的表为例,我们先在表中添加一些数据:
delimiter ;;
create procedure test_insert()
begin
declare i int default 1;
while (i < 100000) do
insert into idx_student (id ,name ,age,score ) values (i,concat('abc',i),10,10);
set i = i+1;
end while;
commit ;
end;;
delimiter ;
call test_insert();这里我们插入了100000条数据,然后我们进行一次查询(未加索引):
select * from idx_student where name='abc6000';
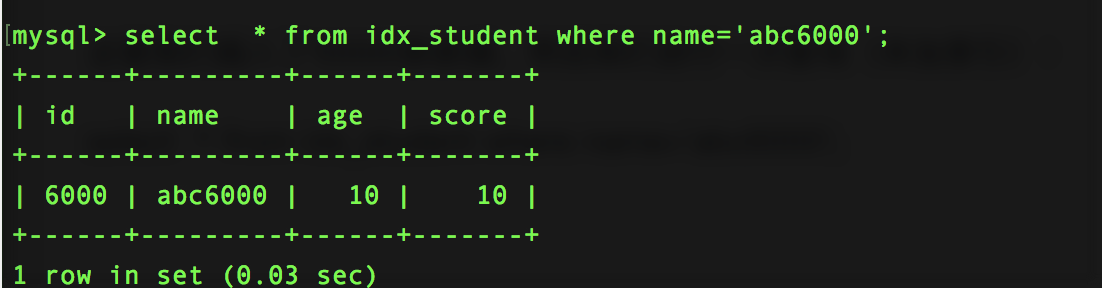
加上了索引之后:
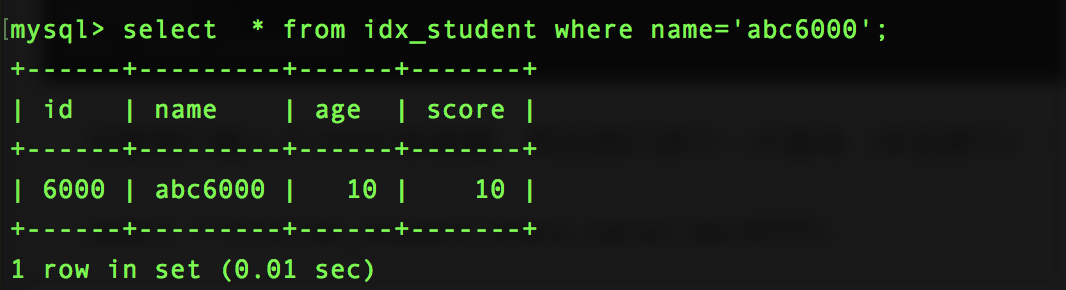
看来效果不明显,如果我们把上述的数字改成1000000(一百万),我们来试下:
select * from idx_student where name='abc600000';
未加索引:
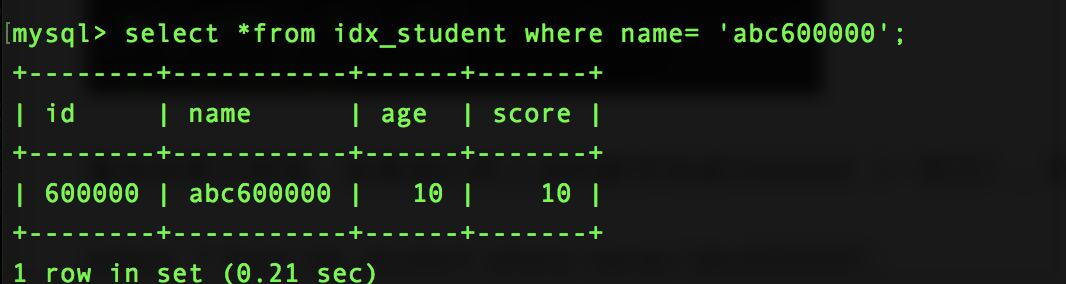
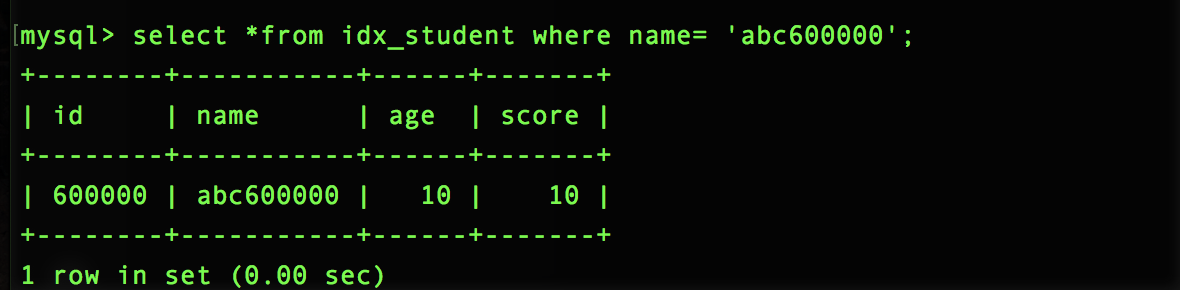
加上索引:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









