






 本文详细介绍了Redis的特点、安装步骤、启动方式、基本命令及数据类型,并探讨了其在任务队列、发布订阅等方面的应用。
本文详细介绍了Redis的特点、安装步骤、启动方式、基本命令及数据类型,并探讨了其在任务队列、发布订阅等方面的应用。

简介
remote directory server 远程字典服务;
特性:
- 数据类型丰富
- 内存存储支持持久化
- 功能丰富(例如可以做队列并支持阻塞读取)
- 简单稳定
测试网址:http://try.redis.io/
安装
1:下载安装包
2:redis没有任何依赖,所以解压直接make && make install ; 二进制程序被复制到/usr/local/bin

3:make test 测试一下是否正确编译

启动
方法一:直接启动 默认6379端口
redis-server [--port 6380]
方法二:启动脚本 生产环境推荐这种方法,使redis随系统启动,基本路径如下:
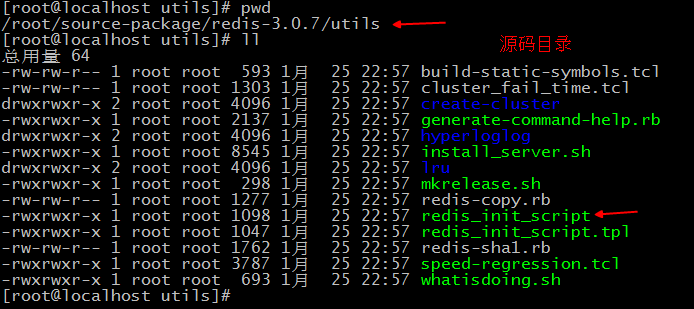
1,把脚本复制到 /etc/init.d 下文件名 redis_端口号,完后修改脚本里面端口号保持一样。
2,建立文件夹:
/etc/redis 存放redis配置文件
/var/redis/端口号 存放redis持久化文件
3,修改配置文件:把配置文件模板(在源码包一级目录下)复制到 /etc/redis中 6379.conf 并修改

4,启动 /etc/init.d/redis_6379 start
(注意:这是自带的启动方法,文件名配置严格按照上面执行,要不对不上来)
5,设置为开机启动
停止
发送SHUDOWN信号,kill pid 也是一样,但是不要强制杀死,因为有数据在内存中,所以需要先断开连接,完后持久化,杀掉进程。
redis-cli SHUDOWN
客户端
redis-cli
连接服务端:redis-cli -h 主机 -p 6379
连接成功:127.0.0.1:6379>
配置
启动的时候可以指定配置文件启动(redis-server /etc/redis.conf)
也可以加启动参数(redis-server /etc/redis.conf --loglevel waring)
redis 命令行下运行 CONFIG SET 可以动态配置:


数据库
一个redis的实例提供了多个用来存数据的字典,这个字典就类似于关系型数据库的DB的概念,redis在配置文件中通过 database来修改 默认支持16个。
redis数据库不支持自定义名字,也不支持独立设置访问密码,而且这些数据库不是完全独立的,flushall 清空所有的数据。所以不适合在一个实例中存储不同应用的数据
数据类型
redis不支持数据类型嵌套,复合类型里都是字符串,会自己转成字符串
- 字符串
是其他类型的基础,最大512M,3.0以后的版本放宽了,但是在内存中512已经很大了
- 散列
适合存储对象
- 列表
最大2的23次方减一个元素 不唯一 有序 内部双向链表实现 支持阻塞读取
- 集合
最大2的23次方减一个元素 唯一 无序;hashTable实现 删除,查找时间复杂度为O(1)
- 有序集合
为每个元素关联了一个分数,集合中每个元素不同但是他们的分数可以相同
热身
命令格式:keys pattern 支持通配符 redis命令不区分大小写 但是我们一般用大写
# 设置值 成功返回ok
set bar 1
# 获取所有key key较多的时候会有效率问题
keys *
# key是否存在 成功返回1 失败返回0
exists bar
# 删除键 返回删除键的个数
del key [key ....]
del不支持通配符,所以不能批量删除,曲线救国方法:
方法一:
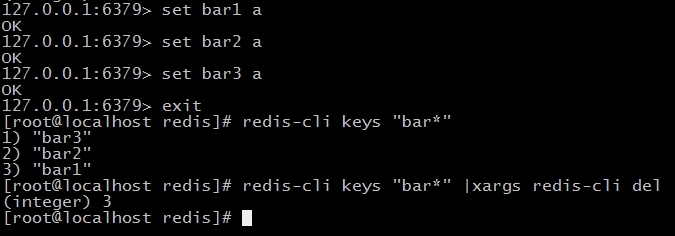
方法二(没验证成功,以后研究):
![]()
# 获取键值类型
type key
# 自增1 返回自增后的结果 如果key不存在则相当于设置key为1 不是整数会报错
incr num
# 自增指定的数num
incrby key num
# 增加浮点数
incrbyfloat key float
# decr / decrby 和上面2个相反
# append 向尾部追加 返回追加完字符串长度
append key string
# strlen获取字符串长度 不存在返回0
strlen key
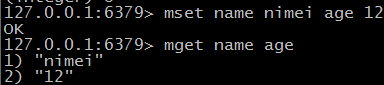
# mget mset 同时设置获取多个键值
# setrange 字符串替换
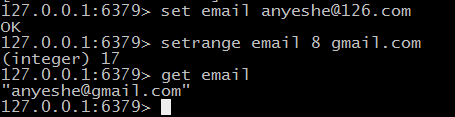
#getrange 获取部分字符串
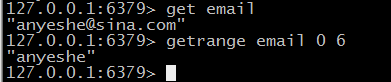
# setget 设置key的值并返回旧值
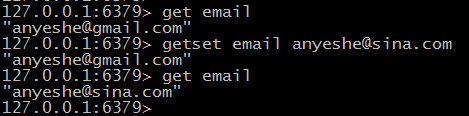
散列操作
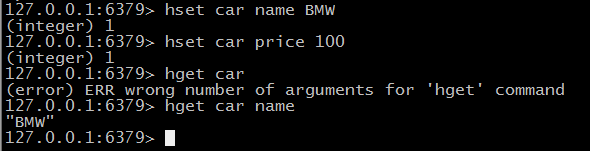
> HSET / HGET
散列表操作,hset方便在于不用事先判断key是否存在来判断是执行新增还是更新,插入返回1更新返回0
> HMGET / HMSET 用于一次操作多个
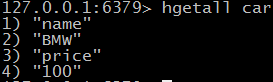
> HGETALL key 获取key全部 value
> HEXISTS key的某个值是否存在

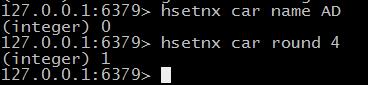
> hsetnx key不存在的时候设置
>hincrby 把某个value增加

> hdel 删除key

> hkeys / hvals 获取所有的key 或者value
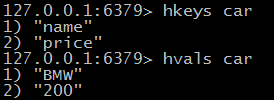
> hlen 获取字段数量
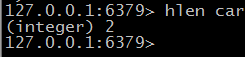
列表操作
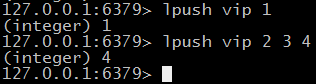
$ lpush key [ key ... ] / rpush key [ key ... ] 返回列表长度
$ lpop key / rpop key 弹出数据
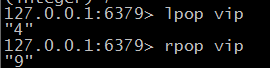
$llen key 列表长度
![]()
$ lrange key start end 获取列表的片段
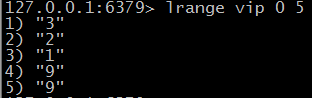
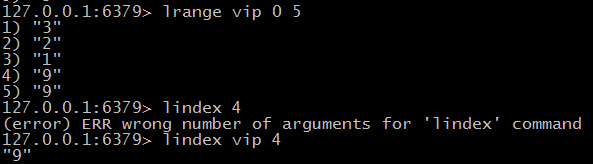
$ lrem key count value 删除列表中前count个值为value的元素

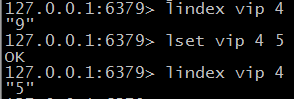
$ lindex key index 获取指定索引的值 index为负数表示从右边索引
$ lset key index value 设置指定索引的值
$ ltrim key start end 删除指定范围之外的元素
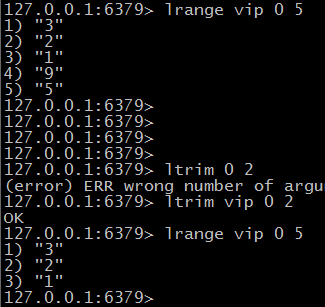
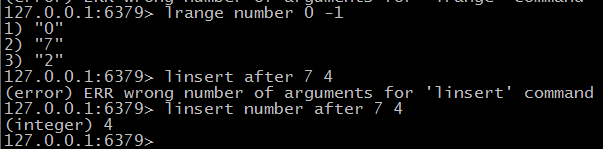
$ linsert key befor|after pivot value 插入元素value到pivot前或者后 返回列表的长度
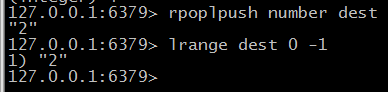
$ rpoplpush source dest 从source队列中pop一个元素 到 dest队列中,原子操作,允许多个客户端操作
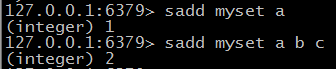
集合操作
@ sadd key value [ value ... ] 向集合中添加元素 已经存在则忽略
@ srem myset value [ value ... ] 删除元素可多个,不存在则忽略
![]()
@ smembers key 获取集合中所有元素

@ sismember key value 判断元素是否存在
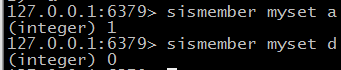
@ sdiff seta setb [ setN ... ] 所有属于a但不属于b的元素(差集) 如果多个的话按顺序2个2个计算
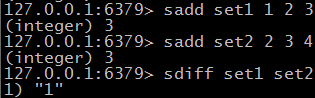
@ sinter seta setb [ seyN ... ] 既属于seta同时也属于setb (交集)

@ sunion seta setb [ setN ... ] 求并集
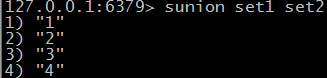
@ 上面三个函数后面加store表示把计算的结果存储起来(sdiffstore sinterstore sunionstore)
@ scard seta 获取集合元素的个数
![]()
@ srandmember key [ count ] 随机去数据
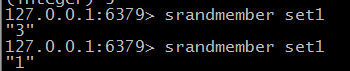

@ spop key 随机弹出一个元素 由于集合是无序的
![]()
有序集合
~ zadd key score member [ score member ] 有序集合中添加元素 修改的话只需要继续添加会覆盖的,分数可以是浮点数
![]()
~ zscore key member 获取元素的分数
![]()
~zrange key start stop 返回从小到大排序完在这个范围的元素 后面加withscores 同分数一起返回
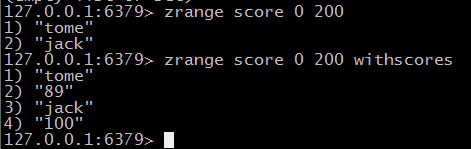
返回0-200这个范围,(表示第0个到200个)元素相同按字典排序;
zrevrange 是按照分数排序后返回的
~zrangebyscore 按分数排序返回 前面加(表示不包含这个端点
![]()
![]()
![]() +inf -inf 无穷大
+inf -inf 无穷大
~zincrby key addnum value 为某个元素的分数加值 返回加后的值
![]()
~zcard key 获取数量
![]()
事务

multi 告诉redis接下来的命令不要执行
queued 准备好了
exec执行
错误处理:
1,语法错误 只要有一条语句有错误对的也不会执行
2,运行错误 这种错误是执行之前redis查不到,比如数据类型用错命令,这种会执行下去,所以出现错误需要程序员自己去处理。

演示一下wahch
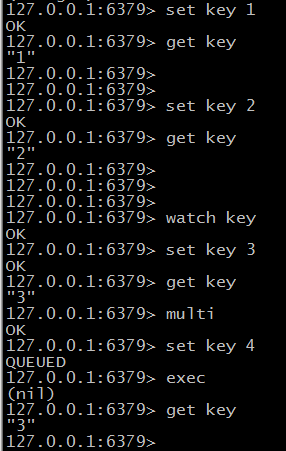
生存时间
expire key time // 设置生存时间 单位秒
ttl key // 一个key还剩多少时间 不存在或者永久生效都是 -1
persist // 取消生存期
pexpire key time // 单位是毫秒
上面一组前面加p是一组
SORT命令
sort可以对列表,集合,有序集合排序
ALPHA 加这个关键字可以实现按照字典排序
DESC 从大到小排 默认是从小到大
BY
GET
任务队列
需要注意的是 出队列的时候用 BRPOP 可以实现如果队列中没有数据的时候会阻塞等待 防止那种没数据还不断的查浪费资源
优先级队列
BRPOP / BLPOP之类的函数可以同时监控多个key 而且是按照从左到右的顺序返回的,我们定义队列的时候按优先级从高到低排列

当高优先级队列有数据的时候首先会返回它的数据
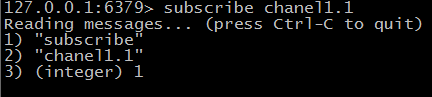
发布订阅
两个角色 发布者,订阅者 发布者对指定的频道发消息而订阅者可以收到消息
发消息:
![]() 返回值是订阅这条消息的人的个数,
返回值是订阅这条消息的人的个数,
发出去的消息不会持久化
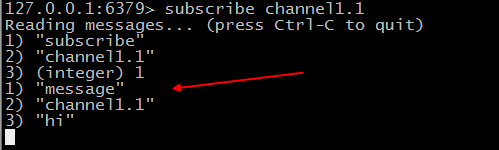
订阅者:
订阅完后再发消息

















 173万+
173万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









