






一.re库的主要功能函数

1.re.search()用法


2.re.match()的用法
>>> match=re.match(r'[1-9]\d{5}','BIT 100081') >>> if match: print(match.group(0)) >>> match.group(0) Traceback (most recent call last): File "<pyshell#12>", line 1, in <module> match.group(0) AttributeError: 'NoneType' object has no attribute 'group' >>> match=re.match(r'[1-9]\d{5}','510000 BIT 100081') >>> if match: print(match.group(0)) 510000 >>>
3.re.findall()用法
>>> match=re.findall(r'[1-9]\d{5}','BIT 100081 TSU100084') >>> match ['100081', '100084'] >>>
4.re.split()用法

>>> match=re.split(r'[1-9]\d{5}','BIT 100081 TSU100084') >>> match ['BIT ', ' TSU', ''] >>> match=re.split(r'[1-9]\d{5}','BIT 100081 TSU100084',maxsplit=1) >>> match ['BIT ', ' TSU100084'] >>>
5.re.finditer()用法
>>> for m in re.finditer(r'[1-9]\d{5}','BIT100081 TSU100084'): if m: print(m.group(0)) 100081 100084
6.re.sub()用法
>>> re.sub(r'[1-9]\d{5}',':zipcode','BIT100081 TUS100084') 'BIT:zipcode TUS:zipcode' >>>
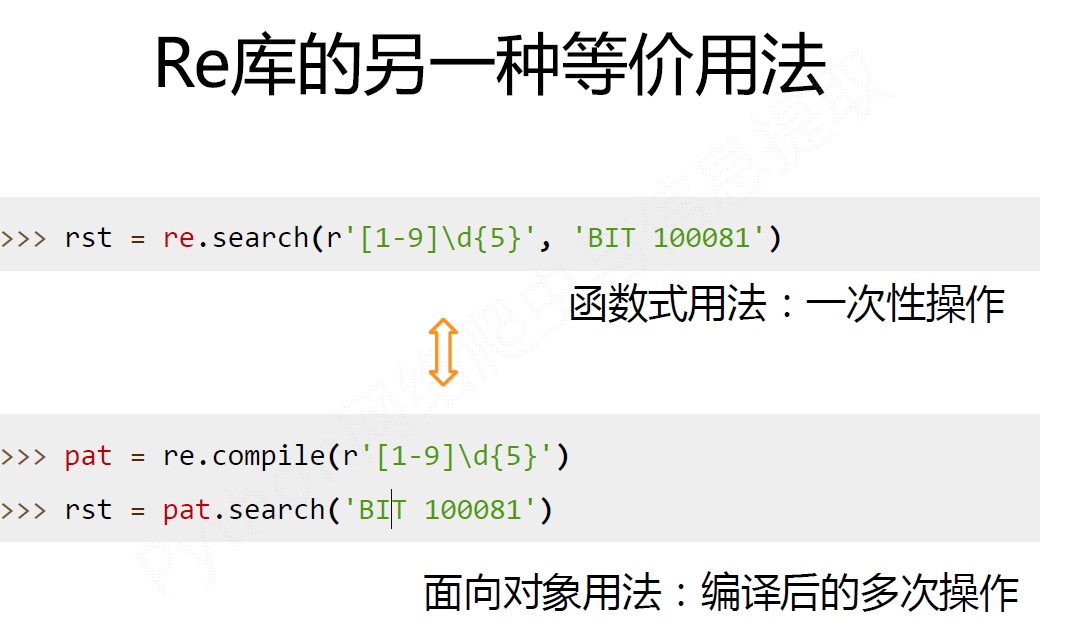
二.re库的另一种等价用法

















 566
566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









