






 本文深入探讨了Java集合框架中的ArrayList和HashSet的工作原理,包括ArrayList的存储机制、扩容策略及HashSet如何实现元素的唯一性。同时,通过实例展示了如何利用集合解决实际问题。
本文深入探讨了Java集合框架中的ArrayList和HashSet的工作原理,包括ArrayList的存储机制、扩容策略及HashSet如何实现元素的唯一性。同时,通过实例展示了如何利用集合解决实际问题。
作业08-集合
1.本周学习总结
以你喜欢的方式(思维导图或其他)归纳总结集合相关内容。
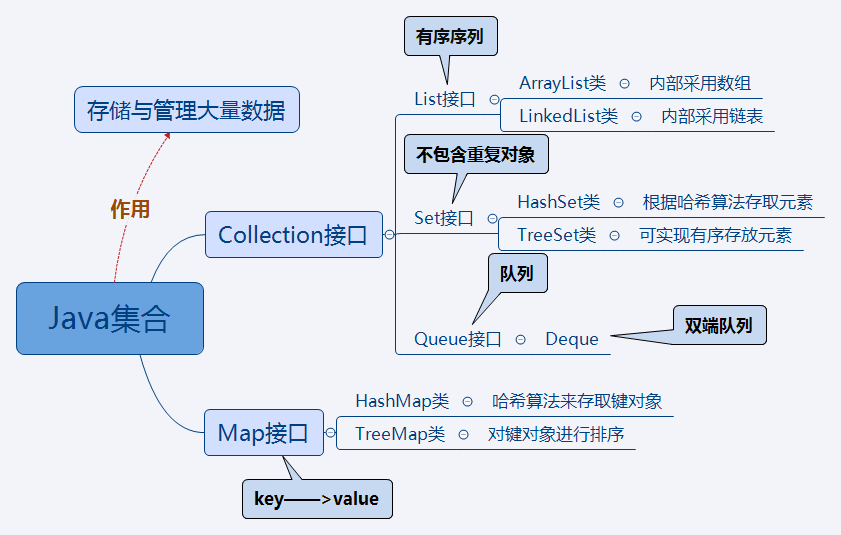
2. 书面作业
1. ArrayList代码分析
1.1 解释ArrayList的contains源代码
甩图:

ArrayList的contains方法中还有一个indexOf方法,当输入的对象是空的时候,不会直接调用equals方法。判断elementData[i]是否为空,为空返回i。如果o不为空的时候,进行比较,找到放回下标值,找不到则返回-1。
1.2 解释E remove(int index)源代码


rangeCheck(index);检查是否符合所在的范围。rangeCheck方法是判断下表有没有超过size,超过报错。
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;这一段是在不为空的时候,逐一删除元素,每删除一个,将下一个向前面移动,删除完后,置为空。返回oldValue。
1.3 结合1.1与1.2,回答ArrayList存储数据时需要考虑元素的具体类型吗?
首先,在集合中操作的肯定是对象喽,那么,简单的数据类型是不可以的,然后ArrayList中继承自Object类,所以说不管你存放进什么引用类型,都会被封装成Object添加到ArrayList。所以需要不考虑元素的具体类型。
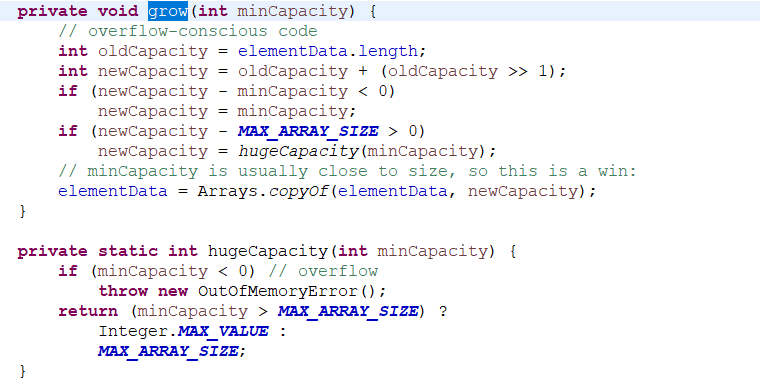
1.4 分析add源代码,回答当内部数组容量不够时,怎么办?
首先,使用ensureCapacityInternal()方法,去保证elementData数组的长度是size+1,elementData[size++] = e;在添加对象的时侯,size增加1。

DEFAULTCAPACITY_EMPTY_ELEMENTDATA是一个常量,默认的长度是10,那么这里是判断elementData数组的长度,如果是默认长度,将DEFAULT_CAPACITY和minCapacity比较,较大的值赋给minCapacity。确保数组长度是新的minCapacity的长度。modCount实现++操作,if判断的是所需长度minCapacity 是不是比elementData数组的长度大,如果是,说明存储不够,调用grow(minCapacity)方法,明显是增加容量。

int newCapacity = oldCapacity + (oldCapacity >> 1);扩容,增加至1.5倍,第一个if判断新的容量够不够存储的,够了就不要扩了,第二个if是如果不够继续扩大,然后复制给elementData数组。原来的就不要了。有个问题是如果超出了最大长度,就会报溢出错误。
1.5 分析private void rangeCheck(int index)源代码,为什么该方法应该声明为private而不声明为public?
要判断有没有超过size,用户是不需要去关心的,用户知道是有remove的方法就行了,实现将这个方法直接封装起来。
2. HashSet原理
2.1 将元素加入HashSet(散列集)中,其存储位置如何确定?需要调用那些方法?
HashSet的add()在底层调用了HashMap的put(),在HashMap的put()方法中,先判断key的存在来决定value的修改与否,这样子向HashSet中添加值的时候,相当于进行了判断key,实现了不重复添加的功能。put()方法调用putVal()方法。

2.2 将元素加入HashSet中的时间复杂度是多少?是O(n)吗?(n为HashSet中已有元素个数)
是o(1),因为添加进去的元素只需要和key进行比较一次就可以,有就不会加入,没有就加入进去。
2.3 选做:尝试分析HashSet源代码后,重新解释2.1
3. ArrayListIntegerStack
题集jmu-Java-05-集合之ArrayListIntegerStack
3.1 比较自己写的ArrayListIntegerStack与自己在题集jmu-Java-04-面向对象2-进阶-多态、接口与内部类中的题目自定义接口ArrayIntegerStack,有什么不同?(不要出现大段代码)
- 存储方式不同,ArrayListIntegerStack是使用动态数组实现存储的,而ArrayIntegerStack是使用普通数组来实现存储的。
- ArrayIntegerStack中我用到了top,但是在ArrayListIntegerStack可以不需要top用
arrList.size()也能实现。拿出栈方法来说:

3.2 结合该题简单描述接口的好处,需以3.1为例详细说明,不可泛泛而谈。
在eclipse里写两个.java文件,一个是IntegerStack.java,这是一个接口,里面就定义了一堆的方法,在另一个.Java的文件里面在写了class ArrayIntegerStack implements IntegerStack后,点下可以自动生成添加未实现的方法,很快又便利。现在我想加一个方法,在IntegerStack.java文件里面添加就OK了。感觉速度上比不用接口快好多。
4. Stack and Queue
4.1 编写函数判断一个给定字符串是否是回文,一定要使用栈(请利用Java集合中已有的类),但不能使用java的Stack类(具体原因自己搜索)与数组。请粘贴你的代码,类名为Main你的学号。
package week9;
import java.util.LinkedList;
import java.util.Scanner;
public class Main201621123028{
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
LinkedList<Character> stack1 = new LinkedList<Character>();
LinkedList<Character> stack2 = new LinkedList<Character>();
String stack =sc.next();
for(int i=0;i<stack.length();i++){
stack1.addFirst(stack.charAt(i));
stack2.addLast(stack.charAt(i));
}
boolean flag = true;
while(!stack1.isEmpty()){
if(stack1.peek().compareTo(stack2.peek())==0){
stack1.remove(stack1.peek());
stack2.remove(stack2.peek());
}
else
flag=false;
break;
}
if (flag) {
System.out.println("这是回文!");
} else {
System.out.println("这不是回文!");
}
}
}我是用了LinkedList实现。
4.2 题集jmu-Java-05-集合之银行业务队列简单模拟(只粘贴关键代码)。请务必使用Queue接口,并说明你使用了Queue接口的哪一个实现类?
Queue接口的LinkedList实现类。
for(i=0;i<N;i++)
{
int temp;
temp=sc.nextInt();
if(temp%2!=0){
Q1.add(temp);
}
else
{
Q2.add(temp);
}
}
5. 统计文字中的单词数量并按单词的字母顺序排序后输出
题集jmu-Java-05-集合之5-2 统计文字中的单词数量并按单词的字母顺序排序后输出 (作业中不要出现大段代码)
5.1 实验总结
首先都是按行读取文章,if来判断有没有输入“!!!!!”来判断文章是否结束,接着add进去,TreeSet是可以实现排序的,因为添加进去的不会重复,所以words.size()就是文章不同单词的个数。最后根据单词是否超过10个来实现不同的输出情况就好了。
6. 选做:统计文字中的单词数量并按出现次数排序
题集jmu-Java-05-集合之5-3
6.1 伪代码
1.读入单词
2.放入set
3.获取set的size
4.进行排序
5.输出结果
6.2 实验总结
统计文字中的单词数量并按出现次数排序(不要出现大段代码)
按键排序方法相对简单点,本身比较规则就是按键排序的,但是这里会用到按值排序,不能直接排,需要进行如下一个转换:

然后用到java.util.Collections的一个静态方法实现排序:

7. 选做 面向对象设计大作业-改进
7.1 使用集合类改进大作业或者简述你的面向对象设计大作业中,哪里使用到了集合类。
7.2 进一步完善图形界面(仅需出现改进的后的图形界面截图)
3.码云及PTA
题目集:jmu-Java-05-集合
3.1. 码云代码提交记录
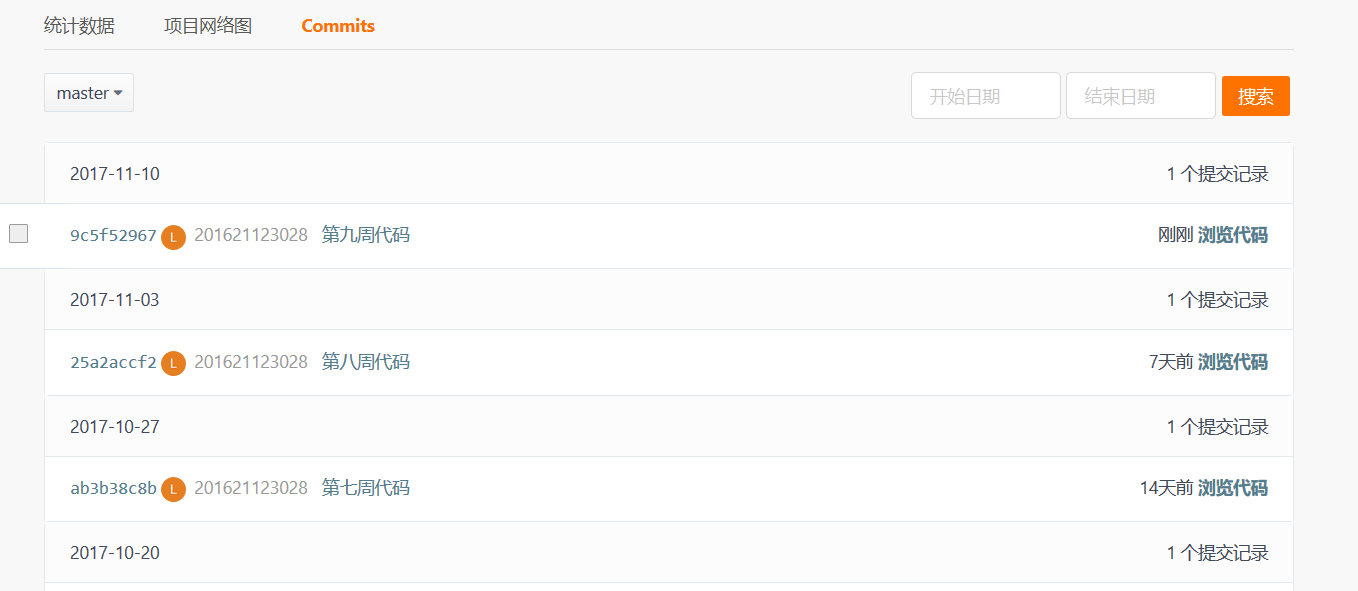
- 在码云的项目中,依次选择“统计-Commits历史-设置时间段”, 然后搜索并截图
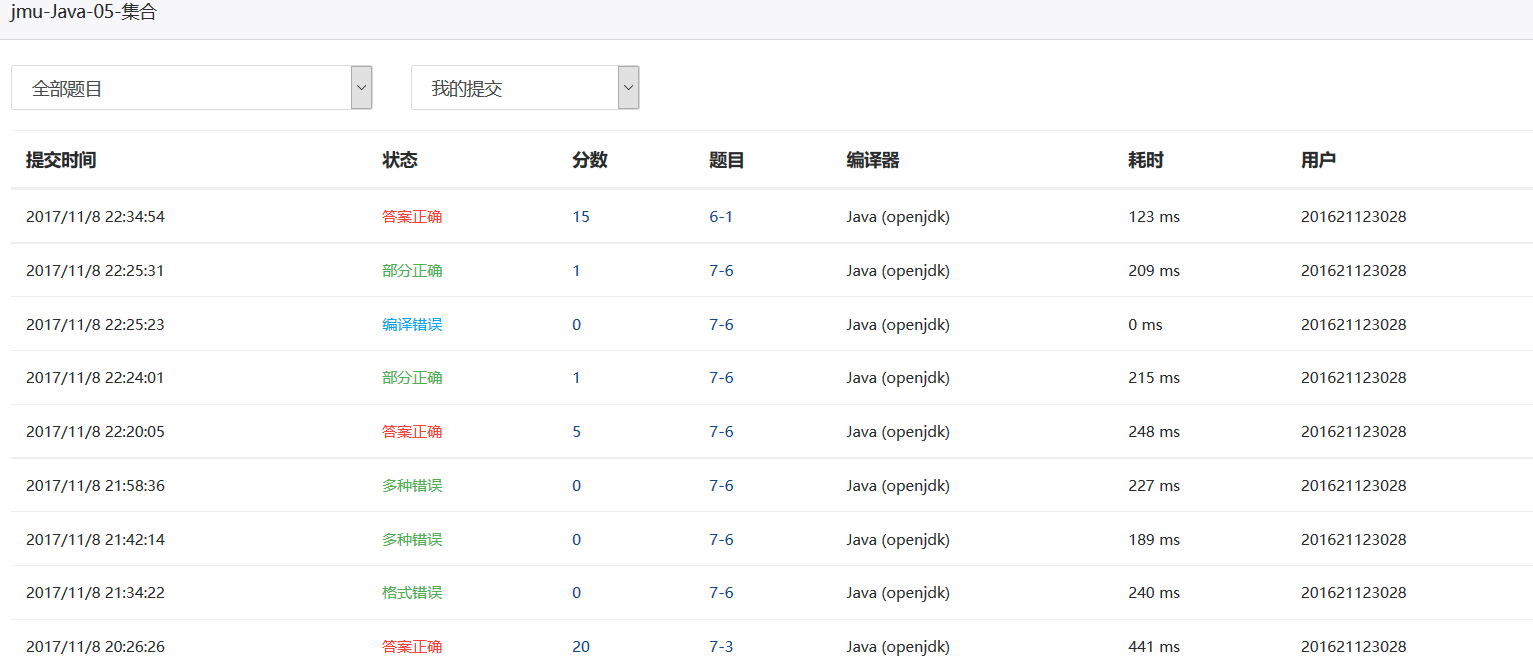
3.2 截图PTA题集完成情况图
需要有两张图(1. 排名图。2.PTA提交列表图)

3.3 统计本周完成的代码量
需要将每周的代码统计情况融合到一张表中。
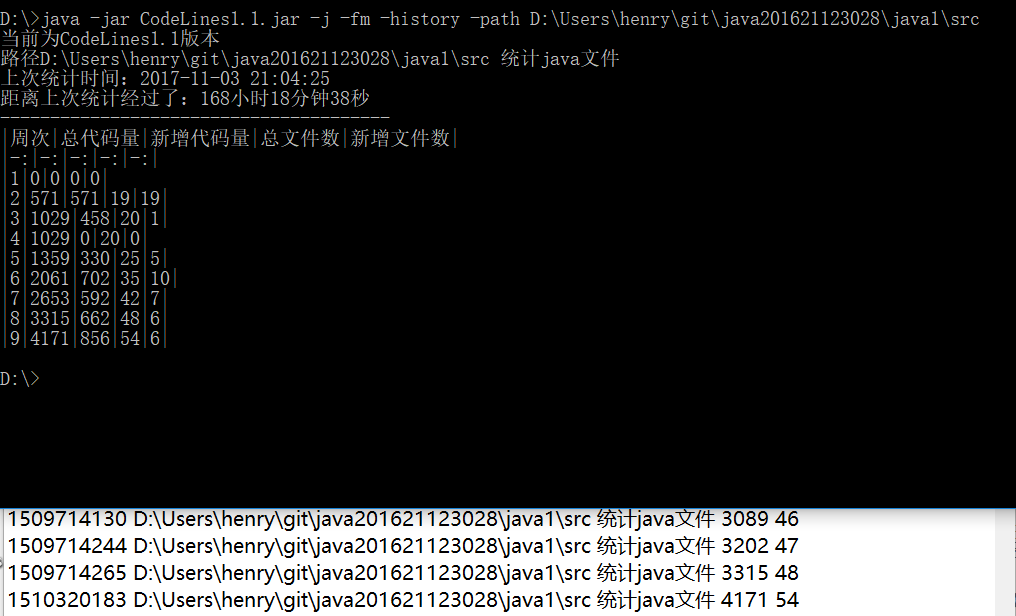
| 周次 | 总代码量 | 新增代码量 | 总文件数 | 新增文件数 |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 |
| 2 | 571 | 571 | 19 | 19 |
| 3 | 1029 | 458 | 20 | 1 |
| 4 | 1029 | 0 | 20 | 0 |
| 5 | 1359 | 330 | 25 | 5 |
| 6 | 2061 | 702 | 35 | 10 |
| 7 | 2653 | 592 | 42 | 7 |
| 8 | 3315 | 662 | 48 | 6 |
| 9 | 4171 | 856 | 54 | 6 |
选做:4. 使用Java解决实际问题
尝试为代码统计项目 增加图形界面。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









