



 本文介绍了内存管理相关知识,包括内存分页技术、Page Walk、CPU的TLB缓存、内存大页技术等。还阐述了启动大页技术的方法,如手动分配和使用大页,以及Buffer Cache和Page Cache的区别。此外,讲解了Swap管理、内存供应控制等内容,并提及相关参数设置。
本文介绍了内存管理相关知识,包括内存分页技术、Page Walk、CPU的TLB缓存、内存大页技术等。还阐述了启动大页技术的方法,如手动分配和使用大页,以及Buffer Cache和Page Cache的区别。此外,讲解了Swap管理、内存供应控制等内容,并提及相关参数设置。

内存管理介绍
一.内存管理介绍:
1.内存分页技术 【Paging】
@内存被分为一页一页的,对于x86的系统,每一页的大小一般是4 KiB (4096 Bytes)
@每一个进程不是直接对内存进行存储的,而是每一个进程都会被分配一个虚存地址空间【virtual address space】
———对于32位的系统来说:每个进程最大可以有4 GiB的虚存空间。
【这个是过去的事情了,RedHat 4的就可以访问64GiB的内存,但是你虚存空间还是4GiB】
【大家可能会有疑问,32位系统最多能访问2^32/2^30=4 GiB的空间,怎么能处理16GiB的空间呢?原因是CPU有一个PAE【物理地址扩展】,它可以帮助我们在原来的物理寻址的基础上再增加4位,2^(32+4)/2^30=64GiB】
———对于64位的系统来说:每个进程最大可以有16 EiB的虚存空间。
@你的进程看见的都是虚拟的内存,如果物理内存小于虚存空间的时候,而你的进程又已经使用大于你的物理内存的大小的时候,进程就开始和你的硬盘交互(swap)。
@一个真的物理内存的我们称为Page Frame[页帧],一个虚拟内存我们称为Page[页]。
@不同进程可以共享同一片真实内存区域(只要内核允许)。虚拟内存到真实内存的转换是有一定的算法的。
2.Page Walk
@进程在运行时往虚拟内存里面写数据,这部分数据就在真实内存的页表【Page Table】里面存着,一个页表是4KiB。
@在下一次存储的时候,进程都会先去找到那些页表的位置,这个动作就叫Page Walk。这个动作由硬件支持,但是还是相对比较慢【相对CPU的计算而言】,一般来说它需要
10到100个CPU的时钟周期。关键看你的缓存了,如果缓存【一,二缓存】中有,就直接从缓存中拿,那当然快。

这是一个Page Walk需要做的步骤,4层结构。
从左往右分别是:全局树,上层树,中间树,页表【每个页表记录了一个内存的真实地址】。
3.CPU的TLB缓存

@由于Page Walk很耗时间,重复跑对CPU伤害很大。所以CPU有一个TLB缓存。当进程开始写的时候,会现在TLB缓存里面找有没有相应的映射关系,如果有就是命中,直接返回就不走Page Walk。如果没有映射关系,则TLB还得回答,你要找的地址现在内存中分好了有没有,如果有,则直接去存,然后建立映射关系。如果没有分好,【技术上叫这个动作为Page Fault】则现在现分一个。
@[root@instructor 442]# x86info -c 可以查看有关TLB大小的信息。
...
TLB info
Data TLB: 4KB pages, 4-way associative, 64 entries #只有64个入口,所以这部发资源竞争肯定很大。
...
@TLB里面的数据只要有上下文切换【换另一个进程来执行】的时候都会被刷新【什么都没了】。
下面的命令可以看出,就算我CPU很闲,每秒都有40几次的上下文切换:
[root@instructor 442]# vmstat
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 6389132 113208 859244 0 0 10 5 18 42 0 0 99 1
4.内存大页技术
案例:
对于16GiB的Oracle的SGA它共有1000多个进程。如果用默认的4 KiB每页的形式存储,则大概需要400万的页面来存储。而为了描述这400万个页面的分配地址空间,你所需的页表的大小也将近16 GiB (1000个进程)。这明显不划算,而且TLB最多只有1024个入口。所以,这时候我们就需要调大每一页的大小,这个就称为大页技术。
@一般来说对于x86系统,一般大页的每一页是2M,也有4M的。对于2M而言,2M=512*4K,即512倍,这样存储大数据的时候对于所需页表就少了。
@但是这样也有缺点,单位大的时候,有些大页实际上没有被占满,所以浪费也会有所增加,但是处理大数据的时候有明显的提升。
如:上面的Oracle的例子,如果是用2M大页:
16 * 1024 / 2 = 8192个页面就能存储完。对于原来的400万的页面来说,是一个明显提高。
所需的页表【Page Table】大小:大约为30MiB【也是一个大的突破】
二.启动大页技术
1.手动分配大页
@大页都是连续的,所以手动分配的时候,它会从你的内存中找到一连串连续的地址,进行分配。所以,虽然有时候内存够,但是分不出来,就是因为没有那么多连续的地址。
查看当前的大页个数:
[root@server6 ~]# grep Huge /proc/meminfo
AnonHugePages: 2048 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
分配大页:
[root@server6 ~]# sysctl vm.nr_hugepages=10
vm.nr_hugepages = 10
[root@server6 ~]# grep Huge /proc/meminfo
AnonHugePages: 2048 kB
HugePages_Total: 10
HugePages_Free: 10
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
这个情况就是内存没有太多连续的时候:
[root@server6 ~]# sysctl vm.nr_hugepages=10000
vm.nr_hugepages = 10000
[root@server6 ~]# grep Huge /proc/meminfo
AnonHugePages: 0 kB
HugePages_Total: 415
HugePages_Free: 415
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
【还有一个办法是绝对可以分小于内存大小的大页总数的,写进grub里,开机自动分】
2.使用大页:
@.大页的文件系统
mount -t hugetlbfs none /mountpoint
之后应用程序用mmap这个系统调用来使用这个/mountpoint
@大页共享内存
应用程序用shmget和shmat这两个系统调用这片共享内存【适用Oracle】
@Red Hat企业版6.2之前,所分的大页所占的内存不能被其他不用大页的进程使用。但是,6.2之后,就出了一个透明式的大页使用【简称:THP】。这个在程序调用的时候有时候直接给你一个大页,然后它会在后台自动为你拼装,而且内存不够的时候还可以对把大页劈开进行交换。进程不用管,直接调用内存就行。THP尽可能使用大页,你把大页分好就行。
@如果你不想使用THP,可以在内核里面添加一个参数:transparent_hugepages=never
3.Buffer Cache 和Page Cache的区别
Buffer Cache(Slab cache):用来缓存文件的(dentries and inodes等等)
Page Cache:完完全全是缓存文件的内容
echo n > /proc/sys/vm/drop_caches
n:[清空]
——1 block data [page cache]
——2 meta data [buffer cache]
——3 block and meta data
三.Swap管理
@在我们添加swap分区之后,如果不带优先级,每添加一个分区它的优先级都比前面的低一点。
@如果加交换分区的时候,如果几个swap分区优先级一样,那么swap分区就会被论寻使用。
内存的状态:
1.Free: 空闲
2.Inactive Clean : 数据已经写如磁盘,且从磁盘读出来后一直没有变化。
3.Inactive Dirty : 这部分没有被使用,但是有数据还没来的即存盘。
4.Active : 正在被使用。
@以前的Kernel[企业版6以前]是使用pdflush来控制这个数据集中写盘的操作。企业版6之后每一个磁盘都用per-BDI flush来控制写盘。在IO非常重的时候,你会在ps命令下看到:flush-MAJOR【主号】:MINOR【从号】。
@ 下面是针对脏页的4个可调参数:
这个是指脏页闲置多久之后开始写盘:
vm.dirty_expire_centisecs
这个是指多久内核去检测有没有脏页:
vm.dirty_writeback_centisecs
这个是(默认是10%)当内存有多少脏页的时候开始写盘:
vm.dirty_background_ratio(default 10)
这个内存中有多少脏页的时候,内核开始写盘,直到脏页到10%左右:
【ratios的值较低的时候适合交互式业务。较高的时候适合吞吐量大的业务】
vm.dirty_ratio(default 40)
@Out of Memory(OOM)
【当虚存内存准备被使用,而内存却已经不够的时候的情况】
这时候,内核就开始随机杀进程,这个非常危险。所以,我们更倾向曲,一旦发生OOM,就让整个系统挂起:vm.panic_on_oom = 1 【这个参数就是当有OOM的时候让整个系统挂起】
@内存有分很多区域,很多时候看起来你系统还有内存但是已经发生了OOM,这很有可能是由于低端内存不够造成的。低端内存像:DMA,DMA32等等。
@内存的结构:
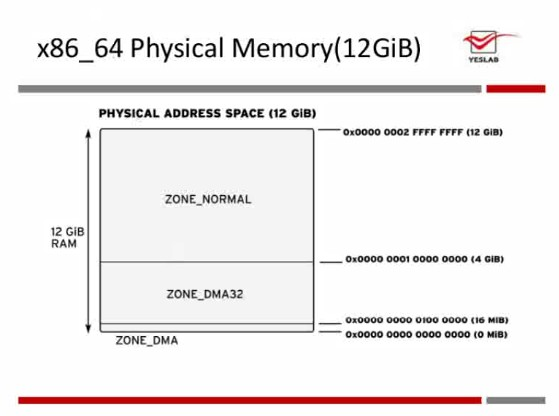
四.内存的供应控制
vm.overcommit_memory
【这个是提供虚存的策略】
0:虽然内存会自动识别给不给,但是基本是有多少给多少,就算超过自身物理内存也行。 【默认值】
1:永远允许,要多少都给。
2:不允许提供超过自身物理内存大小的内存。
【这个是可控的:swap+物理内存(vm.overcommit_ratio控制)【默认是50%】】
例:
[root@server6 ~]# sysctl -a | grep overcommit
vm.overcommit_memory = 0
vm.overcommit_ratio = 50
vm.nr_overcommit_hugepages = 0
[root@server6 ~]# sysctl -e vm.overcommit_memory=2
[root@server6 ~]# grep Com /proc/meminfo
CommitLimit: 1526000 kB
Committed_AS: 62236 kB 【这个是虚存的大小】
ipcs 可以查看相关的信号令,消息队列,共享内存的使用量。
ipcs -l 可以查看信号令,消息队列,共享内存的限制
共享内存:
kernel.shmmni:全局你可以申请多少个共享内存段
kernel.shmmax:每个共享内存段你可以申请的最大值
kernel.shmall:全局上面两个的乘积最大不能超过多少页【单位是页】
信号令:
[root@server6 ~]# sysctl -a | grep kernel.sem
kernel.sem = 250 32000 32 128
A.250:每个信号令数组中信号令的个数
B.32000:整个系统最多有多少个信号令存在
C.32:每个信号令能发出去的system call的个数
D.128:信号令数组的个数 【A*D > B是没有意义的】
消息队列:
[root@server6 ~]# sysctl -a | grep kernel.msgmnb
kernel.msgmnb = 65536
kernel.msgmnb:一个消息队列能发多少字节即消息队列的长度
kernel.msgmni:一个消息队列在系统中的个数,这个与内存相关,是个随机数
kernel.msgmax:一个消息能占多少字节

















 2187
2187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









