



淘女郎,也被很多人称作“网络模特”,就是专门给淘宝、天猫等线上商家拍摄图片的平面模特。
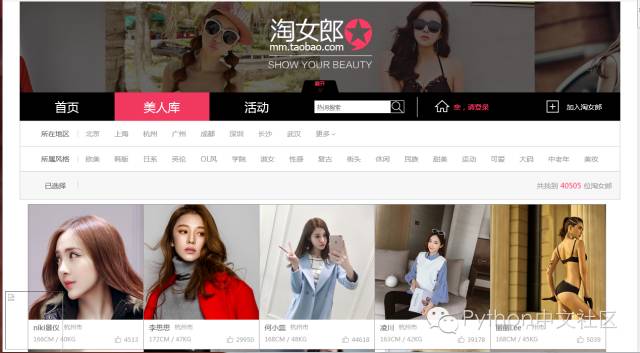
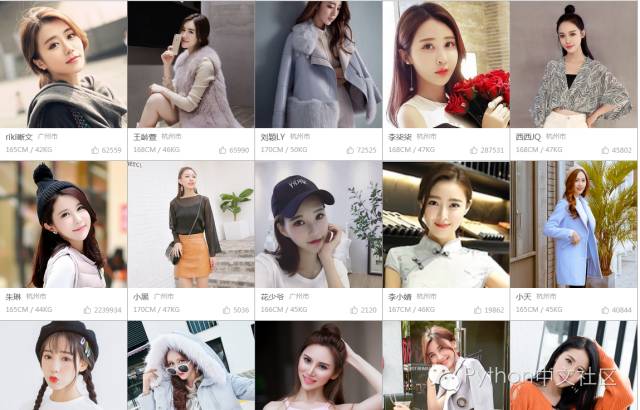
先说一下网页爬取的一般步骤:
1.查看目标网站页面的源代码,找到需要爬取的内容
2.用正则或其他如xpath/bs4的工具获取爬取内容
3.写出完整的python代码,实现爬取过程
查看网站源码,火狐浏览器右键-查看源代码即可获取:

①需要用到的模块
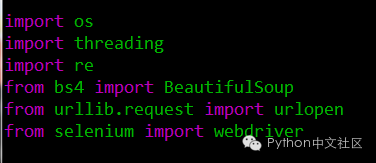
bsObj = BeautifulSoup(driver.page_source, parser)
③用正则表达式获取美女图片 imagesUrl = re.findall('\/\/gtd\.alicdn\.com\/sns_logo.*\.jpg',driver.page_source)
④解析出个人主页地址等信息 girlsUrl = bsObj.find_all("a",{"href":re.compile("\/\/.*\.htm\?(userId=)\d*")})
⑤获取所有美女的图片url girlsHURL = [('http:' + i['href']) for i in girlsUrl]
⑥判断路径文件夹是否创建,如果未创建则创建文件夹保存图片
def mkdir(path):
# 判断路径是否存在
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
print(" [*]新建了文件夹", path)
# 创建目录操作函数
os.makedirs(path)
else:
# 如果目录存在则不创建,并提示目录已存在
print(' [+]文件夹', path, '已创建')
if __name__ == '__main__':
if not os.path.exists(outputDir):
os.makedirs(outputDir)
main()Python执行文件后抓取的效果如下图所示:
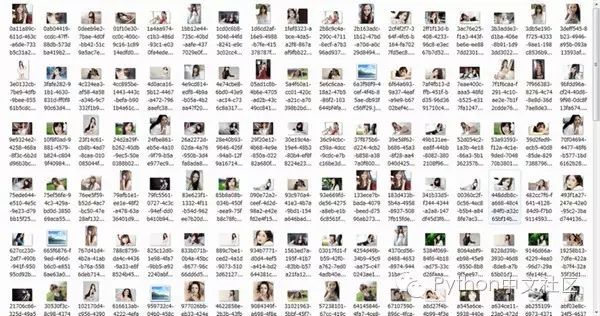
原文发布时间为:2016-11-01
本文来自云栖社区合作伙伴“
Python中文社区”,了解相关信息可以关注“
Python中文社区”微信公众号

















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









