






 博客介绍了机器学习中的欠拟合和过拟合问题。欠拟合是模型未学好训练集规律,表现为训练集和验证集误差大,可增加模型复杂度解决;过拟合是模型学了噪音,泛化能力差,表现为训练集误差小、验证集误差大,需降低模型复杂度。还提醒优先用简单模型。
博客介绍了机器学习中的欠拟合和过拟合问题。欠拟合是模型未学好训练集规律,表现为训练集和验证集误差大,可增加模型复杂度解决;过拟合是模型学了噪音,泛化能力差,表现为训练集误差小、验证集误差大,需降低模型复杂度。还提醒优先用简单模型。
欠拟合(Under Fitting)
欠拟合指的是模型没有很好地学习到训练集上的规律。
欠拟合的表现形式:
- 当模型处于欠拟合状态时,其在训练集和验证集上的误差都很大;
当模型处于欠拟合状态时,根本的办法是增加模型复杂度。我们一般有以下一些办法:
- 增加模型的迭代次数;
- 更换描述能力更强的模型;
- 生成更多特征供训练使用;
- 降低正则化水平;
过拟合(Over Fitting)
过拟合指的是模型不止学习到训练集上的规律,还把噪音学习了进去,以至于模型泛化能力差。
过拟合的表现形式:
- 当模型处于过拟合状态时,其在训练集上的误差小,而在验证集上的误差会非常大。
当模型处于过拟合状态时,根本的办法是降低模型复杂度。我们则有以下一些办法:
- 增加训练样本;
- 减少特征数量;
- 提高正则化水平;
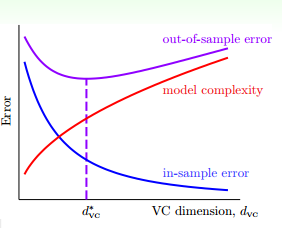
以下是示意图:
随着模型复杂度的提升,训练集误差(蓝线,in-sample error)越来越小,验证集误差(紫线,out-of-sample error)先变小后又变大。虚线处是理想的模型误差。
欠拟合问题比较容易识别,且较易解决,而我们实际碰到的往往是过拟合问题。发生过拟合问题的时候,人们往往会产生一种错觉,认为此时训练出的模型非常完美,这是因为此时训练集误差非常小,几乎为0。因此,我们最好先尝试使用简单的模型,再逐渐试着换成复杂一些的模型。千万不要一开始就用很复杂的模型,因为这样非常容易过拟合。

















 83
83

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









