






 本文介绍了一种从特定网站抓取最新文章标题、网址及发布时间的方法,对比了正则表达式(RE)与Beautiful Soup(BS4)两种技术手段,并讨论了它们各自的优缺点。
本文介绍了一种从特定网站抓取最新文章标题、网址及发布时间的方法,对比了正则表达式(RE)与Beautiful Soup(BS4)两种技术手段,并讨论了它们各自的优缺点。

来看看我们这个实例使用到的网址,大家可以先打开看看:http://blog.jobbole.com/all-posts/
我们要做的第一步就是从这个网页中获取最新文章的标题和网址。可以看到,网页上每一页显示20篇文章,而且经过我几天的观察,每天更新的文章也就三四篇,这就意味着,如果我们每次获取20篇文章的话,肯定会有大部分是重复的,然而事实上我们只需要获取每天最新发布的文章,好在,每篇文章上都写有发布日期,而且在源码中也很容易找得到,就像这样,所有发布的文章都是按照这个形式在源码中进行编写的,这段代码我们后面的分析中也会经常用到
<!-- BEGIN .post-meta -->
<div class="post-meta">
<p>
<a class="archive-title" target="_blank" href="http://blog.jobbole.com/97162/" title="这样的谷歌街景,你肯定没见过">这样的谷歌街景,你肯定没见过</a><br />
2016/01/14 · <a href="http://blog.jobbole.com/category/geeks/" title="查看 极客 中的全部文章" rel="category tag">极客</a> · <a href="http://blog.jobbole.com/97162/#comments" title="《这样的谷歌街景,你肯定没见过》上的评论">2 条评论</a>
</p>
<span class="excerpt"><p>在德国港口城市汉堡有个历史悠久的城区叫库房区,其中有一个著名的旅游景点:微缩仙境。它是世界上最大的铁路微缩模型系统,所以也被称之为「微缩火车乐园」。你可能在现场参观,但你绝对从这个特别的视角来欣赏。</p>
</span>
<p class="align-right"><span class="read-more"><a target="_blank" href="http://blog.jobbole.com/97162/">阅读全文 »</a></span></p>
</div>
<!-- END .post-meta -->那么,应该怎么从上面那段代码中获取我们想要的文章网址,标题,和发布时间呢
到现在为止,我们一共学习了两种获取网页信息的方法,BS4和RE,但是,究竟使用哪一种方法比较好
首先来说说RE,根据对网页源码的分析,很容易将RE写出来
re.compile(r'class="archive-title".*?href="(.*?)".*?title="(.*?)">.*?<br />(.*?)<a.*?',re.S)结果是这样的:
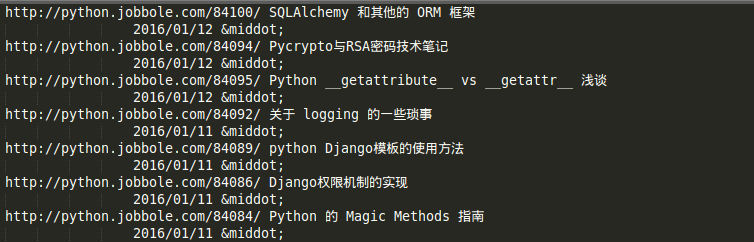
好吧,虽然格式上有一些不尽如人意但是总算将我们需要的东西获取出来了,现在来看看BS4实现的代码是怎样的
通过对网页源码的分析我们知道文章的网址和标题是在tag的属性里面的,日期是tag外面的文本
<a class="archive-title" target="_blank" href="http://blog.jobbole.com/97162/" title="这样的谷歌街景,你肯定没见过">这样的谷歌街景,你肯定没见过</a><br />
2016/01/14 ·也就是说,我们的BS4需要同时获取标签内的属性和标签外的文本,这好像在前面的学习中没有遇到过,我经过了很多次尝试也没能只使用BS4同时将这三个信息获取出来,所以选了一个择中的方法,先分别获取所有的信息再一次性输出出来
date_list = []
url_list = []
title_list = []
# get the date and add to a list
for item in soup.find_all(attrs = {"class":"post-meta"}):
date = re.findall(r'\d{4}/\d{2}/\d{2}',item.get_text())
if date:
date_list.append(date)
# get href ,title and add to list
for mess in soup.find_all(attrs = {"class":"archive-title"}):
url = mess.get('href')
url_list.append(url)
title = mess.get('title')
title_list.append(title)
# printout the message
for i in range(len(date_list)):
print date_list[i], url_list[i], title_list[i]结果如下:
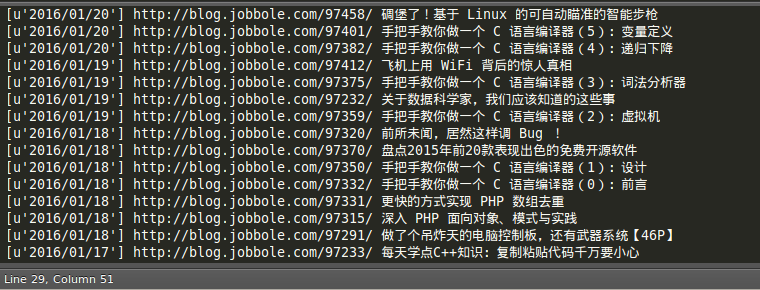
这里暂时先使用RE,由此可见BS4也不是全能的,我们再来看看怎么将时间处理到我们想要的格式,从前面的结果看我们获取的时间是这样一种格式的:
2016/01/14 ·但是这并不是我想要的结果,它带有的空格和乱七八糟的字符真的是影响我的视线,我想要的是"2016/01/14"这样的日期,所以为了实现我的想法,还需要对时间这部分进行处理

















 2170
2170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









