






I have the following situation:
I have several hundred word files that contain company information. I would like to search these files for specific words to find specific paragraphs and copy just these paragraphs to new word files. Basically I just need to reduce the original couple hundred documents to a more readable size each.
The documents that I have are located in one directory and carry different names. In each of them I want to extract particular information that I need to define individually.
To go about this I started with the following code to first write all file names into a .csv file:
# list all transcript files and print names to .csv
import os
import csv
with open("C:\\Users\\Stef\\Desktop\\Files.csv", 'w') as f:
writer = csv.writer(f)
for path, dirs, files in os.walk("C:\\Users\\Stef\\Desktop\\Files"):
for filename in files:
writer.writerow([filename])
This works perfectly. Next I open Files.csv and edit the second column for the keywords that I need to search for in each document.
See picture below for how the .csv file looks:
The couple hundred word files I have, are structured with different layers of headings. What I wanted to do now was to search for specific headings with the keywords I manually defined in the .csv and then copy the content of the following passage to a new file. I uploaded an extract from a word file, "Presentation" is a 'Heading 1' and "North America" and "China" are 'Heading 2'.
In this case I would like for example to search for the 'Headline 2' "North America" and then copy the text that is below ("In total [...] diluted basis.) to a new word file that has the same name as the old one just an added "_clean.docx".
I started with my code as follows:
import os
import glob
import csv
import docx
os.chdir('C:\\Users\\Stef\\Desktop')
f = open('Files.csv')
csv_f = csv.reader(f)
file_name = []
matched_keyword = []
for row in csv_f:
file_name.append(row[0])
matched_keyword.append(row[1])
filelist = file_name
filelist2 = matched_keyword
for i, j in zip(filelist, filelist2):
rootdir = 'C:\\Users\\Stef\\Desktop\\Files'
doc = docx.Document(os.path.join(rootdir, i))
After this I was not able to find any working solution. I tried a few things but could not succeed at all. I would greatly appreciate further help.
I think the end should then again look something like this, however not quite sure.
output =
output.save(i +"._clean.docx")
Have considered the following questions and ideas:
解决方案
Just figured something similar for myself, so here is a complete working example for you. Might be a more pythonic way of doing it…
from docx import Document
inputFile = 'soTest.docx'
try:
doc = Document(inputFile)
except:
print(
"There was some problem with the input file.\nThings to check…\n"
"- Make sure the file is a .docx (with no macros)"
)
exit()
outFile = inputFile.split("/")[-1].split(".")[0] + "_clean.docx"
strFind = 'North America'
# paraOffset used in the event the paragraphs are not adjacent
paraOffset = 1
# document.paragraph returns a list of objects
parasFound = []
paras = doc.paragraphs
# use the list index find the paragraph immediately after the known string
# keep a list of found paras, in the event there is more than 1 match
parasFound = [paras[index+paraOffset]
for index in range(len(paras))
if (paras[index].text == strFind)]
# Add paras to new document
docOut = Document()
for para in parasFound:
docOut.add_paragraph(para.text)
docOut.save(outFile)
exit()
I've also added a image of the input file, showing that North America appears in more than 1 place. 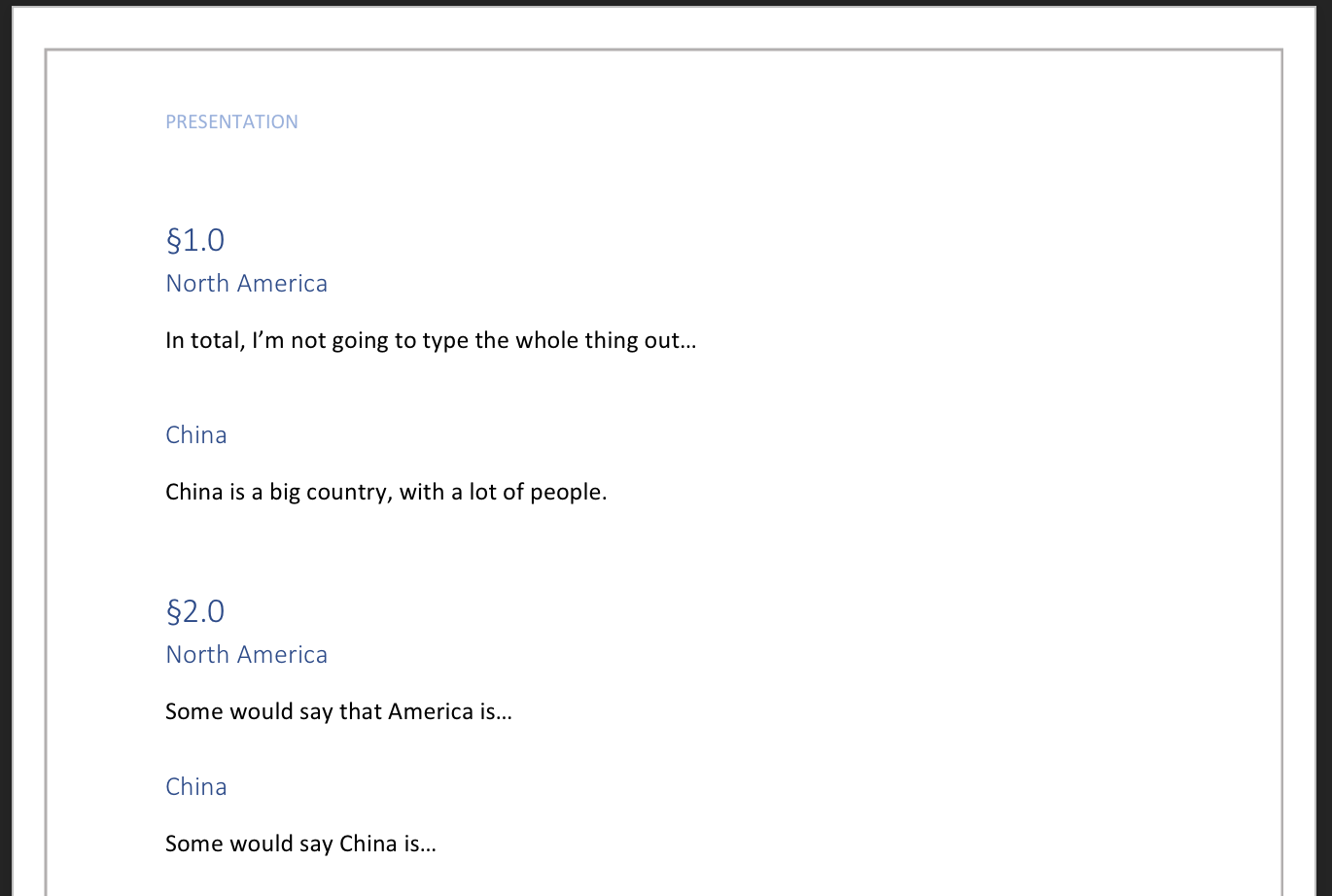


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









