



 本文详细介绍了使用Python的Pandas库进行数据导入、导出、清洗、预处理、计算及分析的方法。涵盖CSV、TXT、Excel文件操作,重复、缺失、空格值处理,字段抽取、匹配、拆分、合并,记录抽取、合并,随机抽样,简单计算,数据标准化,分组,日期转换及格式化等关键步骤。
本文详细介绍了使用Python的Pandas库进行数据导入、导出、清洗、预处理、计算及分析的方法。涵盖CSV、TXT、Excel文件操作,重复、缺失、空格值处理,字段抽取、匹配、拆分、合并,记录抽取、合并,随机抽样,简单计算,数据标准化,分组,日期转换及格式化等关键步骤。
数据处理
1.数据导入、导出
数据类型有txt、excel、CSV等其他数据
导入CSV文件:read_csv(file,encoding)
from pandas import read_csv;
df = read_csv('D://PA//4.1//1.csv')
df
df = read_csv('D://PA//4.1//1.csv', encoding='UTF-8')
导入txt文件:read_table(file,names=[列名1,列名2,....],sep="",encoding,...)
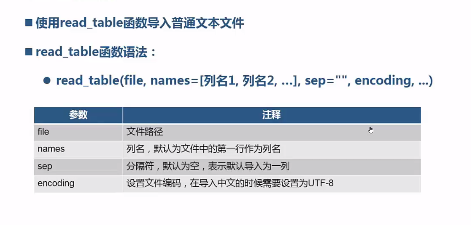
from pandas import read_table;
df = read_table('E://test/4/4.1/2.txt')
df
df = read_table('E://test/4/4.1/2.txt', names=['age', 'name'], sep=',')
df
导入Excel文件:
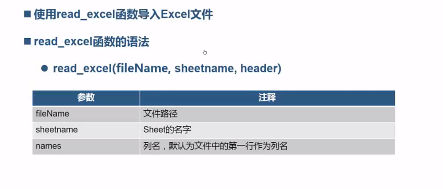
from pandas import read_excel;
df = read_excel('D://PA//4.1//3.xlsx', sheetname='data')
导出文本文件

from pandas import DataFrame;
df = DataFrame({
'age': [21, 22, 23],
'name': ['KEN', 'John', 'JIMI']
});
df.to_csv("D:\\PA\\4.2\\df.csv");
df.to_csv("D:\\PA\\4.2\\df.csv", index=False);
2.重复值、缺失值、空格值的处理
重复值处理函数语法:drop_duplicates()
from pandas import read_csv;
df = read_csv('D://PA//4.3//data.csv')
newDF = df.drop_duplicates();
newDF
缺失值处理函数语法:dropna()
from pandas import read_csv;
df = read_csv('D://PA//4.4//data.csv');
newDF = df.dropna();
空格值处理函数语法:strip()
from pandas import read_csv;
df = read_csv('D://PA//4.5//data.csv')
newName = df['name'].str.strip();
df['name'] = newName;
3.字段抽取、匹配、拆分、合并
字段抽取:slice()
from pandas import read_csv;
df = read_csv("D://PA//4.6//data.csv");
df['tel'] = df['tel'].astype(str);
#运营商
bands = df['tel'].str.slice(0, 3);
#地区
areas = df['tel'].str.slice(3, 7);
#号码段
nums = df['tel'].str.slice(7, 11);
字段匹配:不同的结构的数据框,按照一定的条件进行合并。

import pandas;
from pandas import read_csv;
items = read_csv(
"D://PA//4.12//data1.csv",
sep='|',
names=['id', 'comments', 'title']
);
prices = read_csv(
"D://PA//4.12//data2.csv",
sep='|',
names=['id', 'oldPrice', 'nowPrice']
);
itemPrices = pandas.merge(
items,
prices,
left_on='id',
right_on='id'
);
字段拆分、合并

from pandas import Series;
from pandas import DataFrame;
from pandas import read_csv;
df = read_csv("D:\\Python\\3.2\\2.csv");
newDF = df['name'].str.split(' ', 1, True);
newDF.columns = ['band', 'name'];
字段合并:+
from pandas import read_csv;
df = read_csv(
"D://PA//4.11//data.csv",
sep=" ",
names=['band', 'area', 'num']
);
df = df.astype(str);
tel = df['band'] + df['area'] + df['num']
4.记录抽取、合并
记录抽取



import pandas;
from pandas import read_csv;
df = read_csv("D://PA//4.8//data.csv", sep="|");
df[df.comments>10000]
df[df.comments.between(1000, 10000)]
df[pandas.isnull(df.title)]
df[df.title.str.contains('台电', na=False)]
df[(df.comments>=1000) & (df.comments<=10000)]
记录合并

import pandas;
from pandas import read_csv;
df1 = read_csv("D://PA//4.10//data1.csv", sep="|");
df2 = read_csv("D://PA//4.10//data2.csv", sep="|");
df3 = read_csv("D://PA//4.10//data3.csv", sep="|");
df = pandas.concat([df1, df2, df3])5.随机抽样

import numpy;
from pandas import read_csv;
df = read_csv("D://PA//4.9//data.csv");
r = numpy.random.randint(0, 10, 3);
df.loc[r, :];6.简单计算

from pandas import read_csv;
df = read_csv("D:\\Python\\3.4\\1.csv", sep="|");
result = df.price*df.num7.数据标准化、数据分组

from pandas import read_csv;
df = read_csv("D:\\PA\\4.14\\data.csv");
scale = (df.score-df.score.min())/(df.score.max()-df.score.min())
df["scale"] = scale


import pandas;
from pandas import read_csv;
df = read_csv("D:\\PA\\4.15\\data.csv", sep='|');
bins = [min(df.cost)-1, 20, 40, 60, 80, 100, max(df.cost)+1];
labels = ['20以下', '20到40', '40到60', '60到80', '80到100', '100以上'];
pandas.cut(df.cost, bins)
pandas.cut(df.cost, bins, right=False)
pandas.cut(df.cost, bins, right=False, labels=labels)8.日期转换、日期格式化、日期抽取
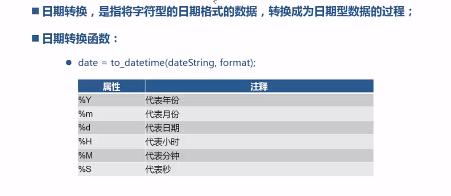
from pandas import read_csv;
from pandas import to_datetime;
df = read_csv("D:\\PA\\4.16\\data.csv", encoding='utf8')
df_dt = to_datetime(df.注册时间, format='%Y/%m/%d');
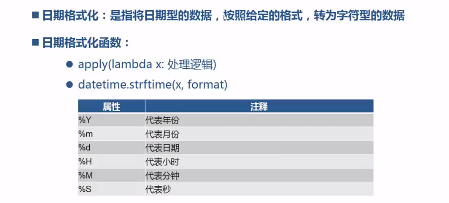
from pandas import read_csv;
from pandas import to_datetime;
from datetime import datetime;
df = read_csv("D:\\PA\\4.17\\data.csv", encoding='utf8')
df_dt = to_datetime(df.注册时间, format='%Y/%m/%d');
df_dt_str = df_dt.apply(lambda x: datetime.strftime(x, '%d-%m-%Y'));
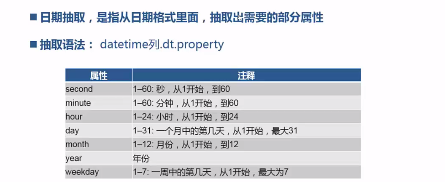
from pandas import read_csv;
from pandas import to_datetime;
df = read_csv('D:\\PA\\4.18\\data.csv', encoding='utf8')
df_dt = to_datetime(df.注册时间, format='%Y/%m/%d');
df_dt.dt.year
df_dt.dt.second;
df_dt.dt.minute;
df_dt.dt.hour;
df_dt.dt.day;
df_dt.dt.month;
df_dt.dt.weekday;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









