



 本文介绍了一种从西刺代理网站爬取IP地址的方法,并通过Python的requests库验证这些IP的有效性和速度。最终筛选出高质量的代理IP,存储于Redis数据库及文本文件中。
本文介绍了一种从西刺代理网站爬取IP地址的方法,并通过Python的requests库验证这些IP的有效性和速度。最终筛选出高质量的代理IP,存储于Redis数据库及文本文件中。
第一步,先用不用代理的方式从西刺代理抓几个可用的IP,用Python的telnetlib库对其进行验证,将可用且速度够快的IP存入Redis和一个txt文件:
import redis
import telnetlib
import urllib.request
from bs4 import BeautifulSoup
r = redis.Redis(host='127.0.0.1',port=6379)
for d in range(1,3): #采集1到2页
scrapeUrl = 'http://www.xicidaili.com/nn/%d/' %d
req = urllib.request.Request(scrapeUrl)
req.add_header('User-Agent', 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)')
response = urllib.request.urlopen(req)
html = response.read()
bsObj = BeautifulSoup(html, "html.parser")
for i in range(100):
speed = float(bsObj.select('td')[6 + i*10].div.get('title').replace('秒',''))
if speed < 0.2: #验证速度,只要速度在0.2秒之内的
ip = bsObj.select('td')[1 + i*10].get_text()
port = bsObj.select('td')[2 + i*10].get_text()
ip_address = 'http://' + ip + ':' + port
try:
telnetlib.Telnet(ip, port=port, timeout=2) #用telnet对ip进行验证
except:
print ('fail')
else:
print ('sucess:'+ ip_address)
r.sadd('ippool',ip_address) #可用的ip导入到redis
f = open('proxy_list.txt','a')
f.write(ip_address + '\n')
f.close()
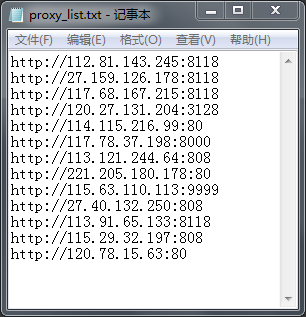
得到的可用IP如下:
http://112.81.143.245:8118
http://27.159.126.178:8118
http://117.68.167.215:8118
http://120.27.131.204:3128
http://114.115.216.99:80
http://117.78.37.198:8000
http://113.121.244.64:808
http://221.205.180.178:80
http://115.63.110.113:9999
http://27.40.132.250:808
http://113.91.65.133:8118
http://115.29.32.197:808
http://120.78.15.63:80
得到一个txt文件,proxy_list.txt:
尝试之后发现,就算经过验证,筛选出来的IP可能还是无法使用。
用requests再验证下(用request是验证telnetlib),发现还是有的能用,有的不能用:
import requests
proxy = {'http':'120.27.131.204:3128'}
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
url = 'http://ip.chinaz.com/getip.aspx/'
response = requests.get(url, proxies=proxy, headers=header)
response.encoding = 'utf-8'
print(response.text)
这个是可用的:
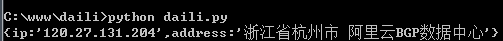
requests要更严格。
用requests方法取代第一步中的telnetlib:
import redis
import urllib.request
from bs4 import BeautifulSoup
import requests
r = redis.Redis(host='127.0.0.1',port=6379)
proxys = []
for d in range(1,3): #采集1到2页
scrapeUrl = 'http://www.xicidaili.com/nn/%d/' %d
req = urllib.request.Request(scrapeUrl)
req.add_header('User-Agent', 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)')
response = urllib.request.urlopen(req)
html = response.read()
bsObj = BeautifulSoup(html, "html.parser")
for i in range(100):
speed = float(bsObj.select('td')[6 + i*10].div.get('title').replace('秒',''))
if speed < 0.6: #验证速度,只要速度在0.6秒之内的
ip = bsObj.select('td')[1 + i*10].get_text()
port = bsObj.select('td')[2 + i*10].get_text()
proxy_host = ip + ':' + port
proxy_temp = {"http":proxy_host}
proxys.append(proxy_temp)
print(proxys)
for proxy in proxys:
try:
url = 'http://ip.chinaz.com/getip.aspx/'
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
response = requests.get(url, proxies=proxy, headers=header, timeout = 3)
code = requests.get(url, proxies=proxy, headers=header, timeout = 3).status_code
if code == 200:
print(code)
response.encoding = 'utf-8'
if "address" in response.text:
print(response.text)
r.sadd('ippool',proxy)
f = open('proxy_list.txt','a')
f.write(str(proxy) + '\n')
f.close()
except:
print("失败")
从这两页只提取出两个IP:
{'http': '114.235.83.2:8118'}
{'http': '120.27.131.204:3128'}
再次验证,都成功了:

西刺代理高匿每页的数量是100,两页共200个,但是只筛选出两个满意的。注意一下筛选的参数(都是可修改的):速度小于0.6秒;requests的timeout为3秒。筛选粒度大一些的话,应该可以找到更多让人满意的。
(后来一次爬了10页,发现越到后面越没有可用的。只有第一页可用性最高。然而,即使是筛选出来的可用ip,再次验证还是会出错。看来只有以量取胜了。)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









