







一、DDL(Data Definition Language)
1.Hive数据抽象的结构
描述Hive表数据的结构:create alter drop.....
打开Hive官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
Hive构建在Hadoop之上
Hive的数据存放在HDFS之上
Hive的元数据可以存放在RDBMS之上
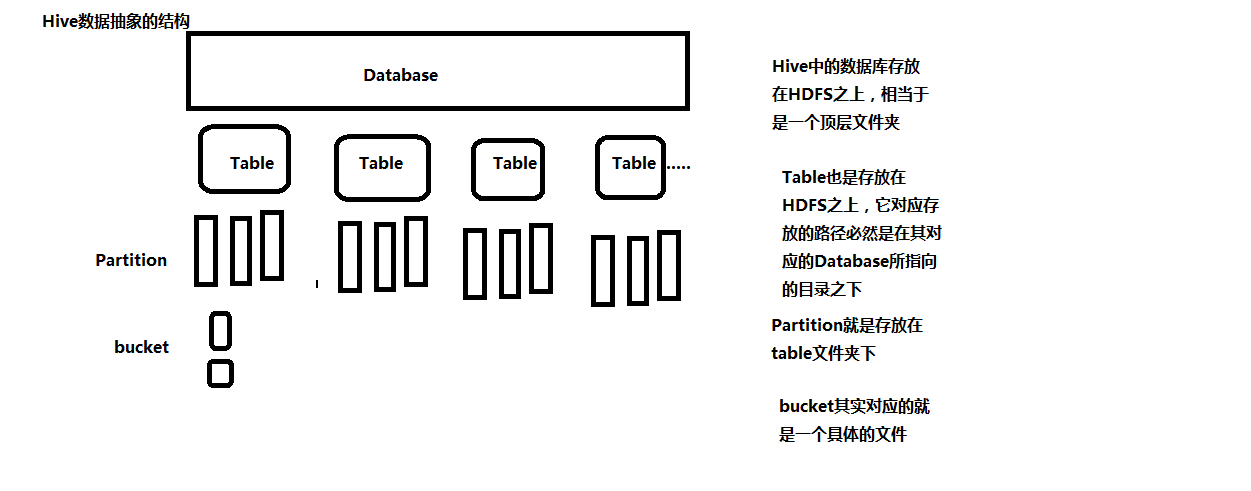
2.Database
Hive中包含了多个数据库,默认的数据库为default,特殊没有名字,无论你是否创建数据库,默认都会存在,对应于HDFS目录是/user/hive/warehouse,可以通过hive.metastore.warehouse.dir参数进行配置(hive-site.xml中配置)
hive> show databases;
OK
default
Time taken: 0.461 seconds, Fetched: 1 row(s)
hive>
####Database语法:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
IF NOT EXISTS:加上这句话代表判断数据库是否存在,不存在就会创建,存在就不会创建(生产中一定要添加IF NOT EXISTS)。 如:create database if not exists dbname;
COMMENT:数据库的描述
LOCATION:创建数据库的地址,不加默认在/user/hive/warehouse/路径下
WITH DBPROPERTIES:数据库的属性
####例子:
hive>
> create database hive;
OK
Time taken: 2.073 seconds
hive> show databases;
OK
default
hive
Time taken: 0.124 seconds, Fetched: 2 row(s)
hive>
####查看存储在hdfs的什么路径上
[hadoop@hadoop05 ~]$ hadoop fs -ls /user/hive/warehouse
18/06/14 20:43:25 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2018-06-14 20:38 /user/hive/warehouse/hive.db
drwxr-xr-x - hadoop supergroup 0 2018-06-13 23:03 /user/hive/warehouse/xx
/user/hive/warehouse/<databasename>.db
注意:生产上:IF NOT EXISTS 选项都建议加上。
####创建一个数据库指定路径,往库中插入一张表
hive> create database hive2 LOCATION '/gordon_01';
OK
Time taken: 0.435 seconds
[hadoop@hadoop05 ~]$ hadoop fs -ls /
18/06/14 20:45:50 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 3 items
drwxr-xr-x - hadoop supergroup 0 2018-06-14 20:45 /gordon_01
drwx-wx-wx - hadoop supergroup 0 2018-06-13 22:44 /tmp
drwxr-xr-x - hadoop supergroup 0 2018-06-13 23:03 /user
> use hive2;
OK
Time taken: 3.164 seconds
hive> create table b(id int);
OK
Time taken: 2.25 seconds
hive>
[hadoop@hadoop05 ~]$ hadoop fs -ls /gordon_01
18/06/14 20:53:32 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2018-06-14 20:53 /gordon_01/b
####测试创建一个数据库并给数据库添加加一个备注,增加一些描述的信息,信息是key value
create database hive2_gordon comment 'this is gordon 03 test database ' with dbproperties('create'='gordon','date'='2018-08-08');
####查看刚刚每个创建的数据库的信息
hive> show databases;
OK
default
hive
hive2
hive2_gordon
Time taken: 0.48 seconds, Fetched: 4 row(s)
hive> desc database hive2_gordon;
OK
hive2_gordon this is gordon 03 test database hdfs://192.168.199.105:9000/user/hive/warehouse/hive2_gordon.db hadoop USER
Time taken: 0.176 seconds, Fetched: 1 row(s)
hive> desc database default;
OK
default Default Hive database hdfs://192.168.199.105:9000/user/hive/warehouse public ROLE
Time taken: 0.101 seconds, Fetched: 1 row(s)
####刚刚创建的hive2_ruozedata的属性没有显示出来,一条命令可以查看
hive> desc database extended hive2_gordon;
OK
hive2_gordon this is gordon 03 test database hdfs://192.168.199.105:9000/user/hive/warehouse/hive2_gordon.db hadoop USER {date=2018-08-08, create=gordon}
Time taken: 0.094 seconds, Fetched: 1 row(s)
####通过MySQL查看信息
mysql> use gordon ;
mysql> show tables;
mysql> select * from dbs\G;
*************************** 1. row ***************************
DB_ID: 1
DESC: Default Hive database
DB_LOCATION_URI: hdfs://192.168.199.105:9000/user/hive/warehouse
NAME: default
OWNER_NAME: public
OWNER_TYPE: ROLE
*************************** 2. row ***************************
DB_ID: 6
DESC: NULL
DB_LOCATION_URI: hdfs://192.168.199.105:9000/user/hive/warehouse/hive.db
NAME: hive
OWNER_NAME: hadoop
OWNER_TYPE: USER
*************************** 3. row ***************************
DB_ID: 7
DESC: NULL
DB_LOCATION_URI: hdfs://192.168.199.105:9000/gordon_01
NAME: hive2
OWNER_NAME: hadoop
OWNER_TYPE: USER
*************************** 4. row ***************************
DB_ID: 11
DESC: this is gordon 03 test database
DB_LOCATION_URI: hdfs://192.168.199.105:9000/user/hive/warehouse/hive2_gordon.db
NAME: hive2_gordon
OWNER_NAME: hadoop
OWNER_TYPE: USER
4 rows in set (0.03 sec)
ERROR:
No query specified
####一定要看官网:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
RESTRICT:默认是restrict,如果该数据库还有表存在则报错;
CASCADE:级联删除数据库(当数据库还有表时,级联删除表后在删除数据库)
把刚刚创建的hive2表直接删除,会有报错,因为Hive2里面有一张B表,所以无法删除
####先删除b表再删除数据库Hive2,查看是否有Hive2数据库存在
hive> drop database hive2;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database hive2 is not empty. One or more tables exist.)
hive> use hive2;
OK
Time taken: 0.171 seconds
hive> show tables;
OK
b
Time taken: 1.828 seconds, Fetched: 1 row(s)
hive> drop table b;
OK
Time taken: 0.862 seconds
hive> show tables;
OK
Time taken: 0.085 seconds
####删除级联数据库
drop database hive CASCADE;
常见操作:create alter drop show desc use
####Alter Database
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...); -- (Note: SCHEMA added in Hive 0.14.0)
ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role; -- (Note: Hive 0.13.0 and later; SCHEMA added in Hive 0.14.0)
ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path; -- (Note: Hive 2.2.1, 2.4.0 and later)
Use Database
USE database_name;
USE DEFAULT;
Show Databases
SHOW (DATABASES|SCHEMAS) [LIKE 'identifier_with_wildcards'
“ | ”:可以选择其中一种
“[ ]”:可选项
LIKE ‘identifier_with_wildcards’:模糊查询数据库
####Describe Database
DESCRIBE DATABASE [EXTENDED] db_name;
DESCRIBE DATABASE db_name:查看数据库的描述信息和文件目录位置路径信息;
EXTENDED:加上数据库键值对的属性信息。
二、Hive的基本数据类型&分隔符
官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types
看着官网多,要 疯!!!!!!!!!!!!!!
1.常用基本数据类型
生产中常用数据类型: int bigint float double decimal (数值类型选择一个其他都用string) string (函数也可以用)
生产中不建议使用数据类型:date/timestamp boolean(不建议使用)-> 都用string类型存
时间可以用UDF函数比。
####分隔符
行: \n
列: \001 ^A ==>
1 zhangsan 30
1$$$zhangsan$$$30
map/struct/array
一般情况下,在创建表的时候就直接指定了分隔符:\t
2.Table
####例子:
hive> use hive2_gordon;
OK
Time taken: 1.503 seconds
hive> CREATE TABLE gordon_person
> (id int comment 'this is id', name string comment 'this id name' )
> comment 'this is gordon_person'
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t' ;
OK
Time taken: 4.471 seconds
hive>
> desc gordon_person;
OK
id int this is id
name string this id name
Time taken: 1.458 seconds, Fetched: 2 row(s)
hive> desc formatted gordon_person;
OK
# col_name data_type comment
id int this is id
name string this id name
# Detailed Table Information
Database: hive2_gordon
Owner: hadoop
CreateTime: Thu Jun 14 21:27:27 CST 2018
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://192.168.199.105:9000/user/hive/warehouse/hive2_gordon.db/gordon_person
Table Type: MANAGED_TABLE
Table Parameters:
comment this is gordon_person
transient_lastDdlTime 1528982847
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim \t
serialization.format \t
Time taken: 0.635 seconds, Fetched: 29 row(s)
对于存放数据库的路径我们可以修改(一般不做修改)hive-site.xml
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
####例子:
create table gordon_emp
(empno int, ename string, job string, mgr int, hiredate string, salary double, comm double, deptno int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t' ;
####加载数据到表
LOAD DATA LOCAL INPATH '/home/hadoop/data/emp.txt' OVERWRITE INTO TABLE gordon_emp;
LOCAL: 从本地文件系统加载数据到hive表
非LOCAL:从HDFS文件系统加载数据到hive表
OVERWRITE: 加载数据到表的时候数据的处理方式,覆盖
非OVERWRITE:追加
hive> select * from gordon_emp;
OK
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
8888 HIVE PROGRAM 7839 1988-1-23 10300.0 NULL NULL
Time taken: 3.296 seconds, Fetched: 15 row(s)
####从另外表复制数据【CTAS】
hive> CREATE table gordon_emp2 as select * from gordon_emp; --跑mapreduce
Query ID = hadoop_20180614211111_2ccb7b43-6e66-4de4-8bb7-52aa4a7669f2
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Job running in-process (local Hadoop)
2018-06-14 21:41:22,958 Stage-1 map = 0%, reduce = 0%
2018-06-14 21:41:24,044 Stage-1 map = 100%, reduce = 0%
Ended Job = job_local1375787547_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://192.168.199.105:9000/user/hive/warehouse/hive2_gordon.db/.hive-staging_hive_2018-06-14_21-41-14_000_4839247582555161403-1/-ext-10001
Moving data to: hdfs://192.168.199.105:9000/user/hive/warehouse/hive2_gordon.db/gordon_emp2
Table hive2_gordon.gordon_emp2 stats: [numFiles=1, numRows=15, totalSize=708, rawDataSize=693]
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 2100 HDFS Write: 1489 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
Time taken: 11.628 seconds
hive>
####从另外表复制结构
CREATE table gordon_emp3 like gordon_emp;
####从修改表名字;
ALTER TABLE gordon_emp3 RENAME TO gordon_emp3_new;
####常用操作:create alter drop show desc
Show create table aa;
####Hive中的表又分为内部表和外部表 ,Hive 中的每张表对应于HDFS上的一个文件夹,HDFS目录为:/user/hadoop/hive/warehouse/[databasename.db]/table
3.创建表默认使用的是MANAGED_TABLE:内部表
gordon_emp2
drop:hdfs+meta
####删除表gordon_emp2
hive> drop table gordon_emp2;
hive> show tables;
OK
gordon_emp
gordon_emp3_new
gordon_person
####hdfs上数据信息没有
[hadoop@hadoop05 data]$ hadoop fs -text hdfs://192.168.199.105:9000/user/hive/warehouse/hive2_gordon.db/gordon_emp2
18/06/14 21:51:48 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
text: `hdfs://192.168.199.105:9000/user/hive/warehouse/hive2_gordon.db/gordon_emp2': No such file or directory
####元数据信息也查不到这张表
use gordon;
select * from tbls \G;
查询不到gordon_emp2
内部表总结:只要drop表,就会把hdfs + 元数据的数据全部都删除
4.EXTERNAL:外部表
create EXTERNAL table gordon_emp_external
(empno int, ename string, job string, mgr int, hiredate string, salary double, comm double, deptno int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LOCATION "/gordon/external/emp" ;
drop: drop meta
hive> select * from gordon_emp_external;
OK
Time taken: 0.963 seconds
hive> desc formatted fordon_emp_external;
FAILED: SemanticException [Error 10001]: Table not found fordon_emp_external
hive> desc formatted gordon_emp_external;
OK
# col_name data_type comment
empno int
ename string
job string
mgr int
hiredate string
salary double
comm double
deptno int
# Detailed Table Information
Database: hive2_gordon
Owner: hadoop
CreateTime: Thu Jun 14 22:30:06 CST 2018
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://192.168.199.105:9000/gordon/external/emp
Table Type: EXTERNAL_TABLE
Table Parameters:
EXTERNAL TRUE
transient_lastDdlTime 1528986606
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim \t
serialization.format \t
Time taken: 0.429 seconds, Fetched: 35 row(s)
[hadoop@hadoop05 data]$ hadoop fs -ls hdfs://192.168.199.105:9000/gordon/external/emp
18/06/14 22:32:25 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@hadoop05 data]$ hadoop fs -put emp.txt /gordon/external/emp
18/06/14 22:34:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@hadoop05 data]$ hadoop fs -ls hdfs://192.168.199.105:9000/gordon/external/emp
18/06/14 22:34:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 1 hadoop supergroup 700 2018-06-14 22:34 hdfs://192.168.199.105:9000/gordon/external/emp/emp.txt
[hadoop@hadoop05 data]$
查看到有数据了,以上的这些操作是在工作中非常常见的,只要把数据移动到目录上去立刻就查的出来。
hive> select * from gordon_emp_external;
OK
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
8888 HIVE PROGRAM 7839 1988-1-23 10300.0 NULL NULL
Time taken: 1.094 seconds, Fetched: 15 row(s)
hive>
####查看 MySQL表的类型信息
mysql> select * from tbls\G;
*************************** 6. row ***************************
TBL_ID: 21
CREATE_TIME: 1528986606
DB_ID: 11
LAST_ACCESS_TIME: 0
OWNER: hadoop
RETENTION: 0
SD_ID: 21
TBL_NAME: gordon_emp_external
TBL_TYPE: EXTERNAL_TABLE
VIEW_EXPANDED_TEXT: NULL
VIEW_ORIGINAL_TEXT: NULL
####删除外部表 gordon_emp_external
hive> drop table gordon_emp_external;
查看hdfs上是有数据的
查看MySQL元数据没数据
外部表总结:只要drop表,就会把元数据的数据删除,但是HDFS上的数据是保留的。
两个表的总结:
Hive上有两种类型的表,一种是Managed Table(默认的),另一种是External Table(加上EXTERNAL关键字)。内部表数据由Hive自身管理,外部表数据由HDFS管理;
它俩的主要区别在于:当我们drop表时,Managed Table会同时删去data(存储在HDFS上)和meta data(存储在MySQL),而External Table只会删meta data。内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定; 对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
生产中99%都用到的是外部表,因为可以有一份备份,如果删除表用LOAD DATA LOCAL INPATH 在传一份就可以了。
生产中1%用到的内部表的情况,外面的数据传过来,你这里可建立外部表,如果表删没了再导一份。
hdfs://hadoop000:8020/ddddd
s3a://xxx/yyyy
s3n
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later)
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
constraint_specification:
: [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE ]
[, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE
[hadoop@hadoop05 data]$ jps -m
2210 SecondaryNameNode
1987 NameNode
2507 NodeManager
6075 Jps -m
2076 DataNode
2412 ResourceManager
4348 RunJar /home/hadoop/app/hive-1.1.0-cdh5.7.0/lib/hive-cli-1.1.0-cdh5.7.0.jar org.apache.hadoop.hive.cli.CliDriver
5.TEMPORARY(临时表)
Hive从0.14.0开始提供创建临时表的功能,表只对当前session有效,session退出后,表自动删除。
语法:CREATE TEMPORARY TABLE …
注意:
1. 如果创建的临时表表名已存在,那么当前session引用到该表名时实际用的是临时表,只有drop或rename临时表名才能使用原始表
2. 临时表限制:不支持分区字段和创建索引
insert时目标表必须存在
hive> INSERT OVERWRITE TABLE gordon_emp4
select * FROM gordon_emp;
FAILED: SemanticException [Error 10001]: Line 1:23 Table not found 'gordon_emp4'
hive> create table gordon_emp4 like gordon_emp;
####插入不同的列
hive> INSERT OVERWRITE TABLE gordon_emp4
select empno, deptno FROM gordon_emp;
FAILED: SemanticException [Error 10044]: Line 1:24 Cannot insert into target table because column number/types are different 'gordon_emp4': Table insclause-0 has 8 columns, but query has 2 columns.
插入的时候如果有一列,和源数据信息的列,位置搞错了,不按正常写,就会出现报错,数据错乱
所有在插入的时候需要慎重,列的数量,列的类型,以及列的顺序都写清楚。
hive>INSERT INTO TABLE gordon_emp4
SELECT empno,job, ename,mgr, hiredate, salary, comm, deptno from gordon_emp;
插入的时候如果有一列,和源数据信息的列,位置搞错了,不按正常写,就会出现报错,数据错乱
所有在插入的时候需要慎重,列的数量,列的类型,以及列的顺序都写清楚。
万一出错了,对于大数据而言,没有回滚的概念,只有重跑job
重跑:幂等 ***** 跑100结果也一样 。所有产品需要支持幂等
log
2055 ==> 20
2054 ==> 20
....
1959 ==> 19
看官网:

















 515
515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









