



 本文介绍了MapReduce的大数据处理原理,通过图书馆管理员统计图书数量的例子,深入浅出地讲解了MapReduce的工作过程。其中包括如何将任务分配给多个节点(map阶段),以及如何汇总各个节点的结果(reduce阶段)。此外,还通过单词计数的实例详细展示了MapReduce的具体操作步骤。
本文介绍了MapReduce的大数据处理原理,通过图书馆管理员统计图书数量的例子,深入浅出地讲解了MapReduce的工作过程。其中包括如何将任务分配给多个节点(map阶段),以及如何汇总各个节点的结果(reduce阶段)。此外,还通过单词计数的实例详细展示了MapReduce的具体操作步骤。
大数据运算模型 MapReduce 原理
MapReduce 是一个大数据集合的并行运算模型,由google提出,现在流行的hadoop中也使用了MapReduce作为计算模型
MapReduce 通俗解释
图书馆要清点图书数量,有10个书架,管理员为了加快统计速度,找来了10个同学,每个同学负责统计一个书架的图书数量
张同学 统计 书架1
王同学 统计 书架2
刘同学 统计 书架3
......
过了一会儿,10个同学陆续到管理员这汇报自己的统计数字,管理员把各个数字加起来,就得到了图书总数
这个过程就可以理解为MapReduce的工作过程
MapReduce中有两个核心操作
(1)map
管理员分配哪个同学统计哪个书架,每个同学都进行相同的“统计”操作,这个过程就是map
(2)reduce
管理员把每个同学的结果进行汇总,这个过程就是reduce
MapReduce 工作过程拆解
下面通过一个经典案例(单词统计)看MapReduce是如何工作的
有一个文本文件,被分成了4份,分别放到了4台服务器中存储
Text 1: the weather is good
Text 2: today is good
Text 3: good weather is good
Text 4: today has good weather
需求:统计出每个单词的出现次数
处理过程
01
分词处理
map节点 1
输入:(text1, “the weather is good”)
输出:(the, 1), (weather, 1), (is, 1), (good, 1)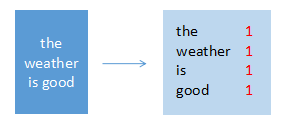
map节点 2
输入:(text2, “today is good”)
输出:(today, 1), (is, 1), (good, 1)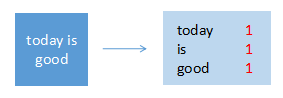
map节点 3
输入:(text3, “good weather is good”)
输出:(good, 1), (weather, 1), (is, 1), (good, 1)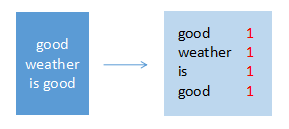
map节点 4
输入:(text3, “today has good weather”)
输出:(today, 1), (has, 1), (good, 1), (weather, 1)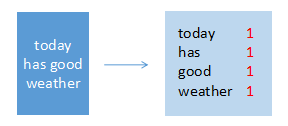
02
排序
map节点 1
map节点 2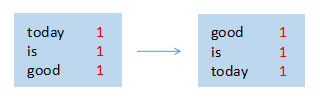
map节点 3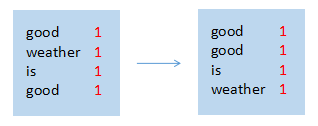
map节点 4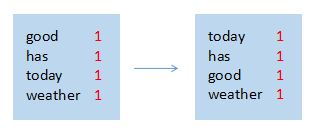
03
合并
map节点 1
map节点 2
map节点 3
map节点 4
04
汇总统计
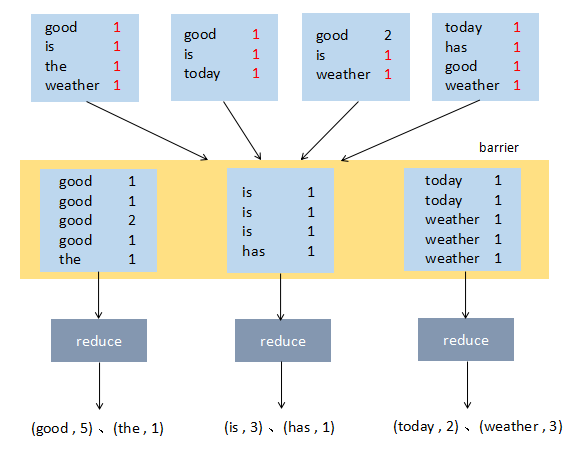
MapReduce引入了barrier概念,有的译为“同步障”,我理解为“分界线”,是进入reduce的一道分界线
barrier的作用是对合并结果进行组合
例如使用了3个reduce节点,需要对上面4个map节点的结果进行重新组合,把相同的单词放在一起,并分配给3个reduce节点
reduce节点进行统计,计算出最终结果


















 2016
2016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









