 Cloudera集群管理实战
Cloudera集群管理实战







 本文详细介绍Cloudera Manager在企业级Hadoop集群管理中的应用,包括创建主机模板、角色组,新节点加入及节点移除等关键操作,助力高效集群运维。
本文详细介绍Cloudera Manager在企业级Hadoop集群管理中的应用,包括创建主机模板、角色组,新节点加入及节点移除等关键操作,助力高效集群运维。
Cloudera Certified Associate Administrator案例之Install篇
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.创建主机模板(为了给主机套用,说白了就是给新加入集群的节点提前分配好角色)
问题描述:
公司新购了一批机器,准备扩充DataNode节点。你决定用CM的host template功能来为新机器配置DataNode通用的服务。新节点需要作为HDFS和YARN的工作节点,因此模板的设计如下:
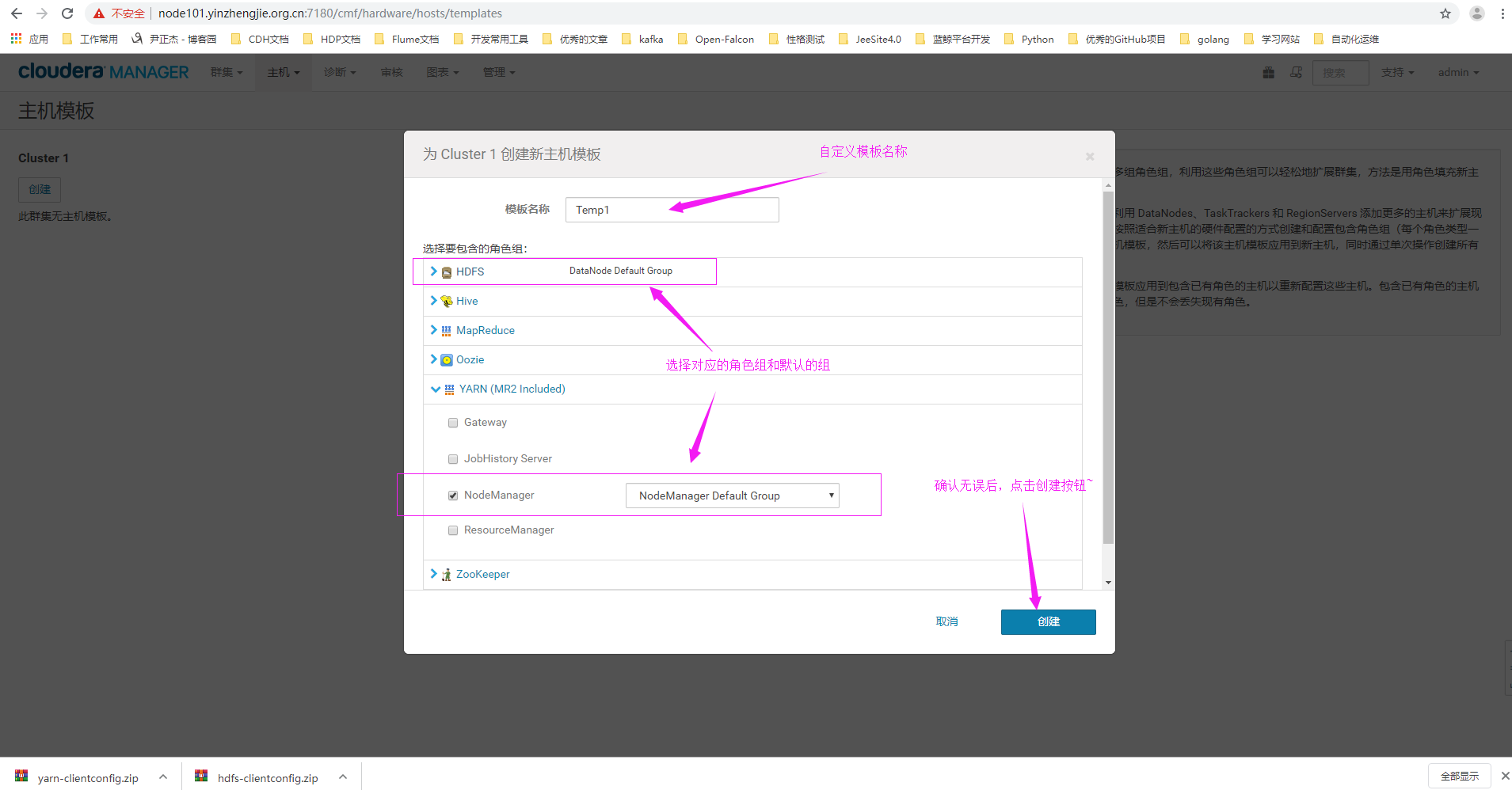
名称:Temp1
HDFS roles:Datanode
YARN roles:NodeManager
要求需要套用HDFS和YARN的Default Group的配置
解决方案:
在企业级实战中,集群扩容时常见且重要的操作,如果手工一台一台操作,不仅效率地下,而且容易出错。
CM提供了多种机制来简化扩容操作,其中host template就是其中重要的一种,通过该特性,可以大大简化工作节点的配置(对于管理节点,工具节点,边缘节点,如果有多台配置完全一样,也可以使用该特性来扩容),如Datanode,Nodemanager,Kafka Broker等。
1>.点击主机,选择"主机模板"
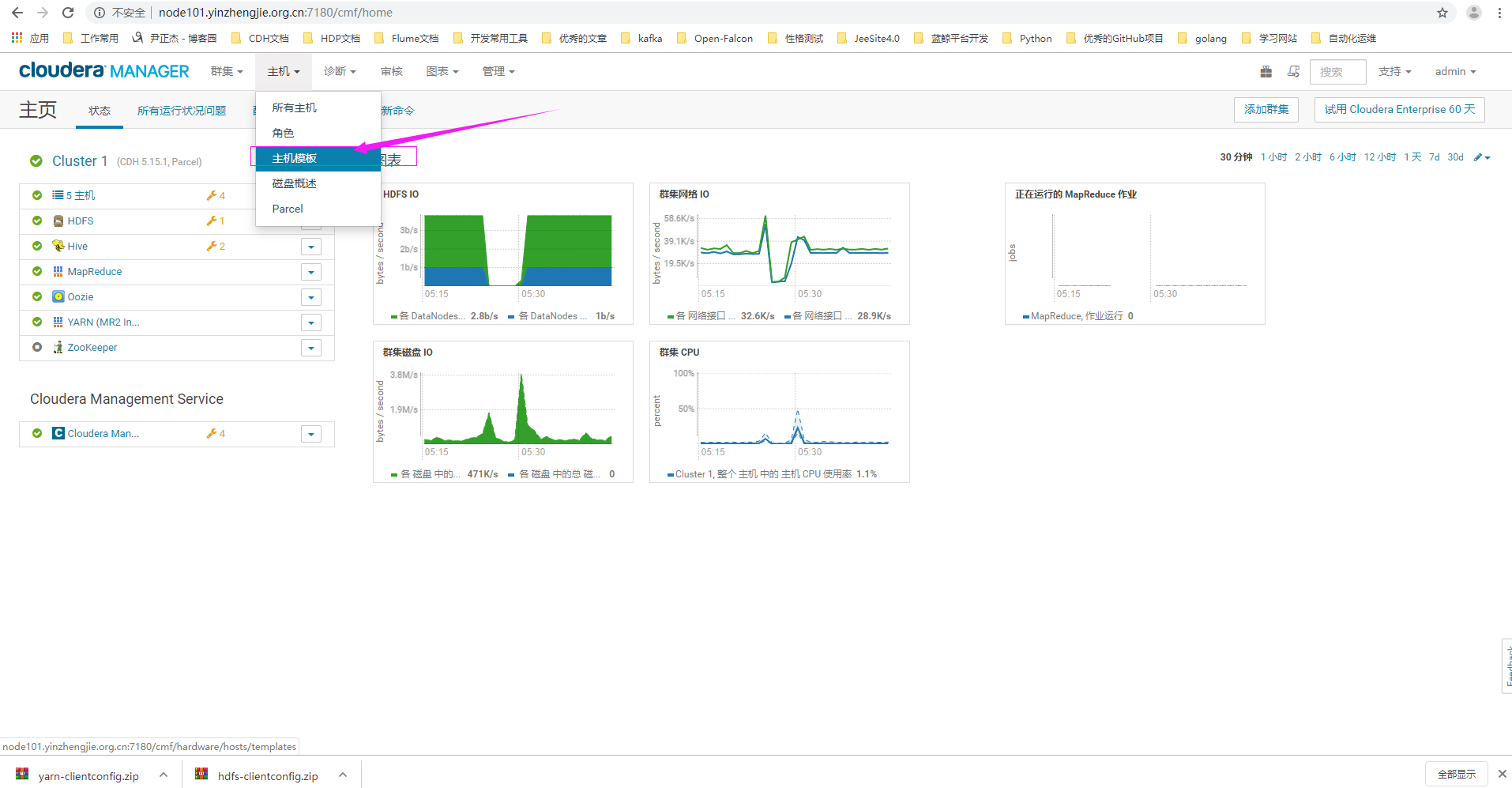
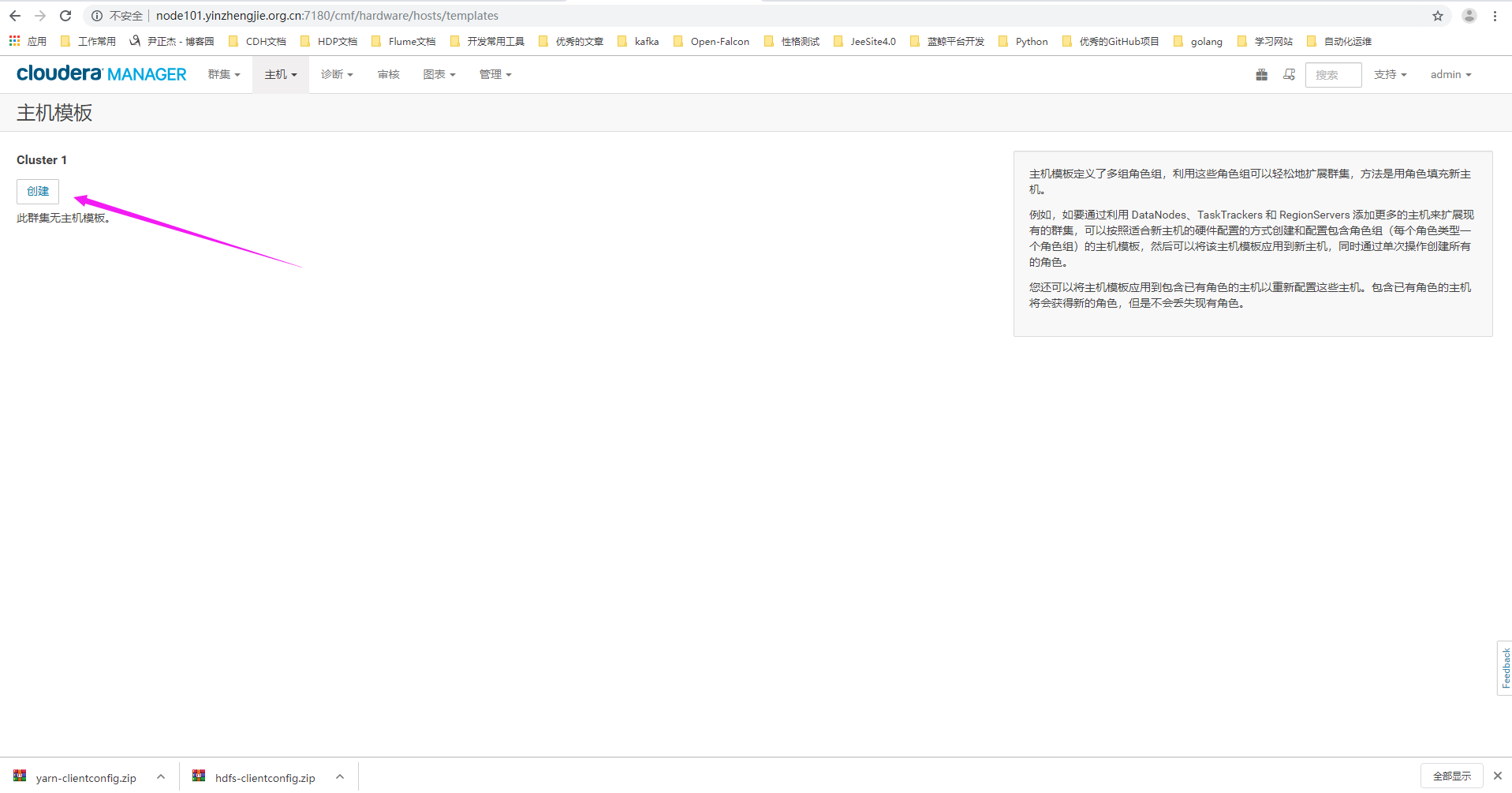
2>.点击创建
3>.自定义模板名称并选择对应的角色和组
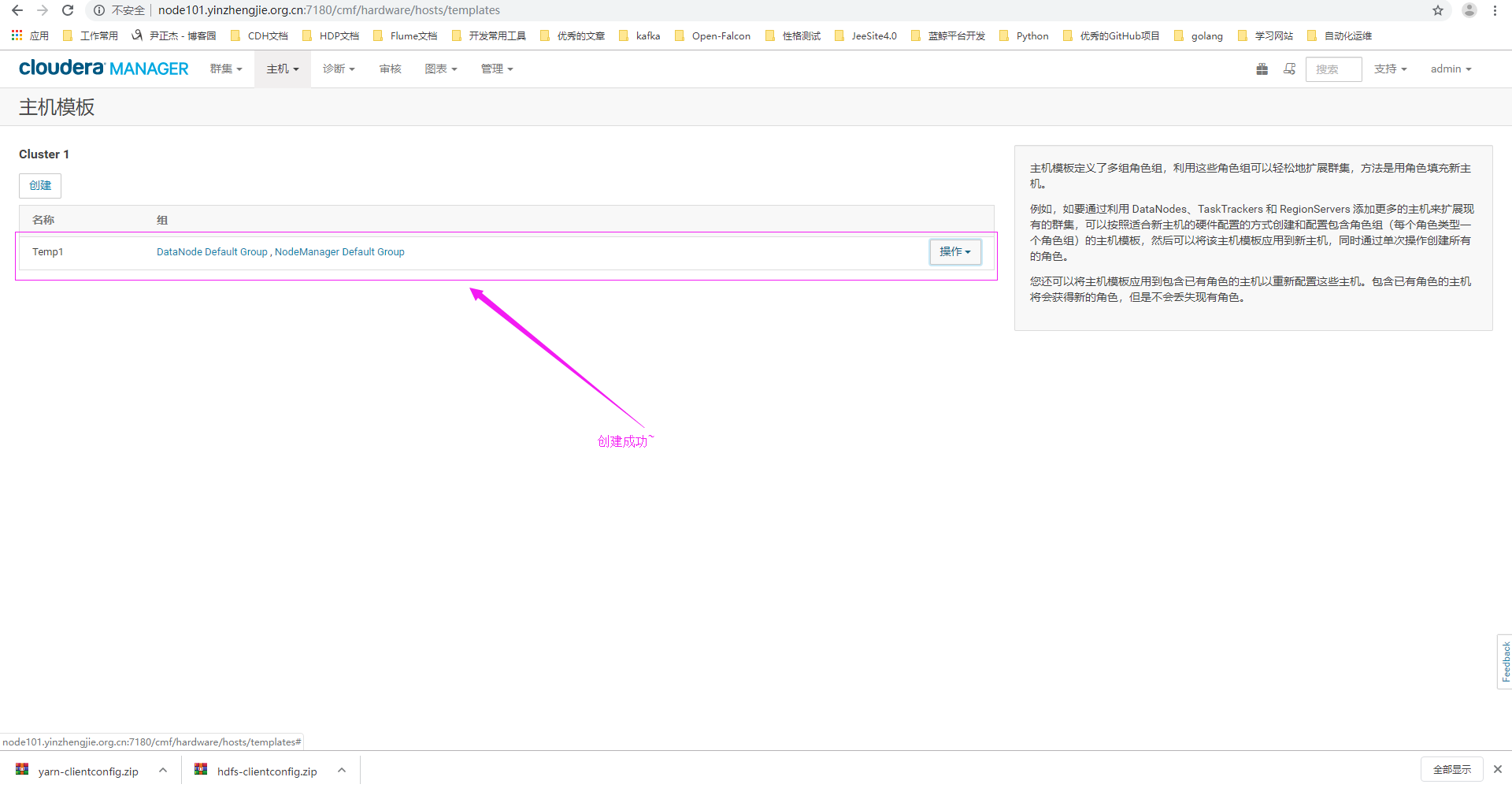
4>.创建成功
二.创建角色组
问题描述:
公司新购了一批机器,准备扩充DataNode节点。然而,新机器的硬件配置和旧机器有一些差异。你决定为旧机器创建一个角色组,设置合适的配置。新机器继续使用默认的组(Default Group)的配置,就如前面我们配置的模板一样。新角色组的需求为:
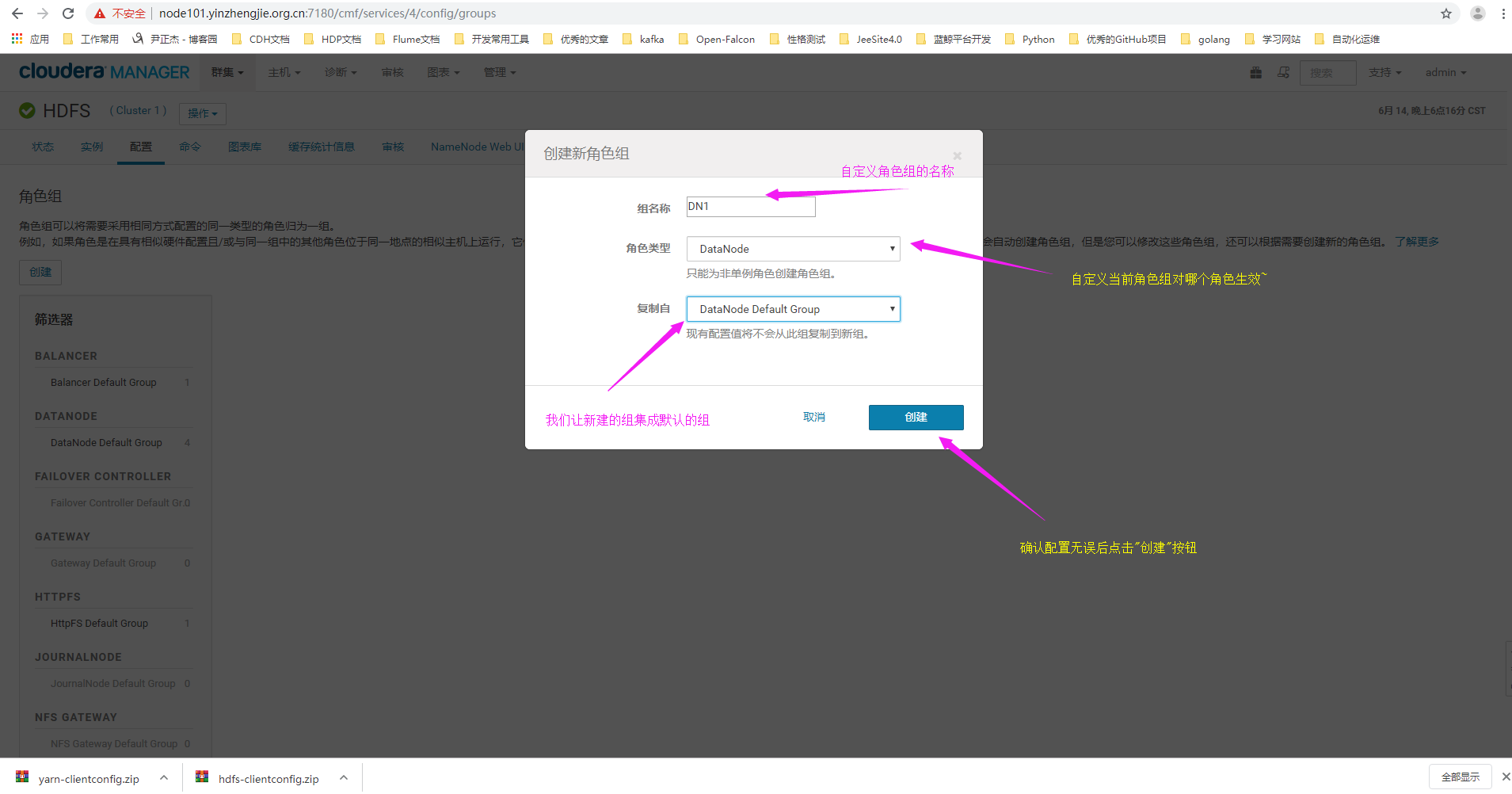
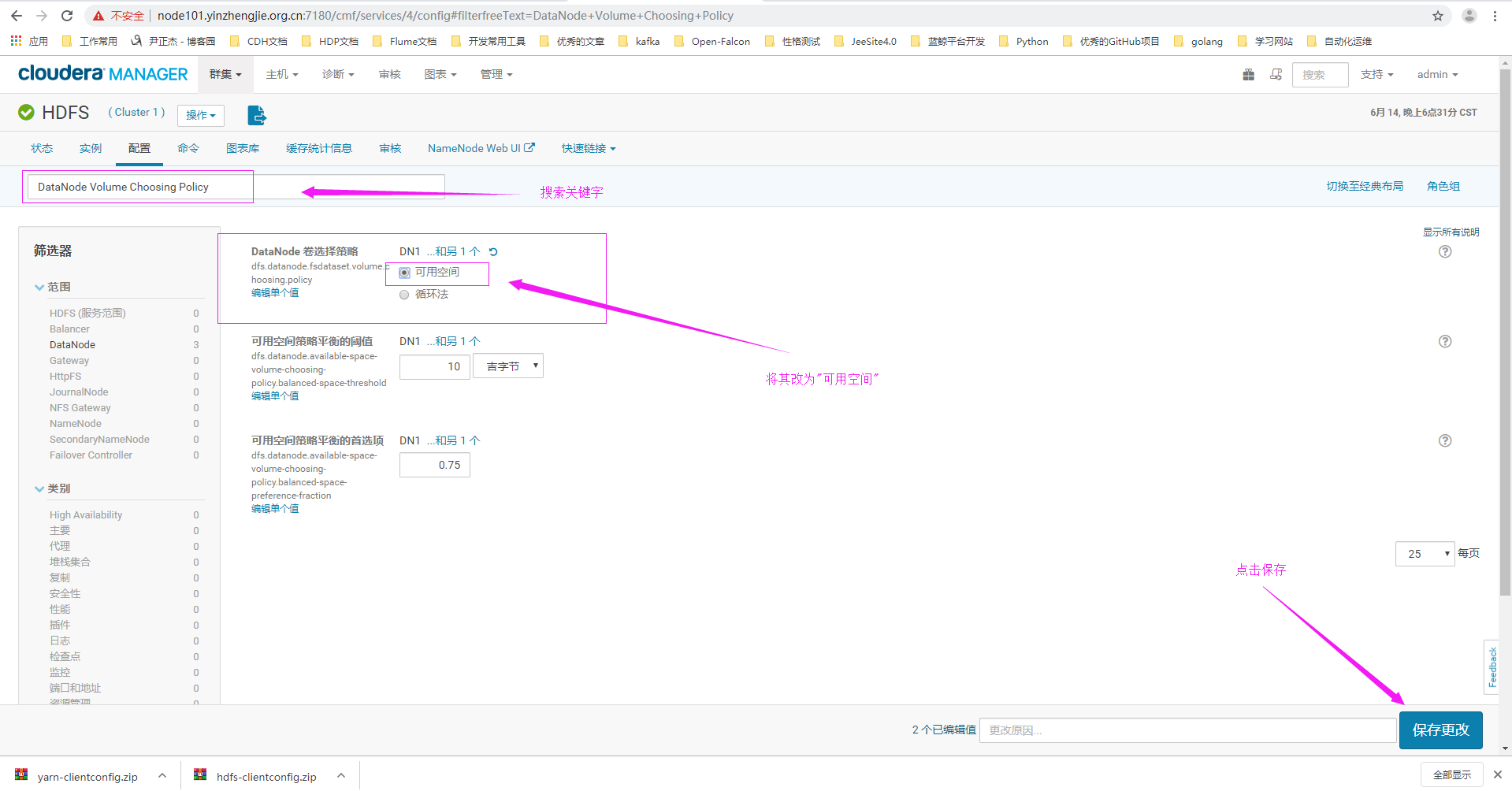
命名为DN1,先继承默认的角色组的配置,并使用旧机器套用DN1的配置。然后要变更一些参数,DN1的Default Group的DataNode Volume Choosing Policy参数都必须设置为Avaliable Space。
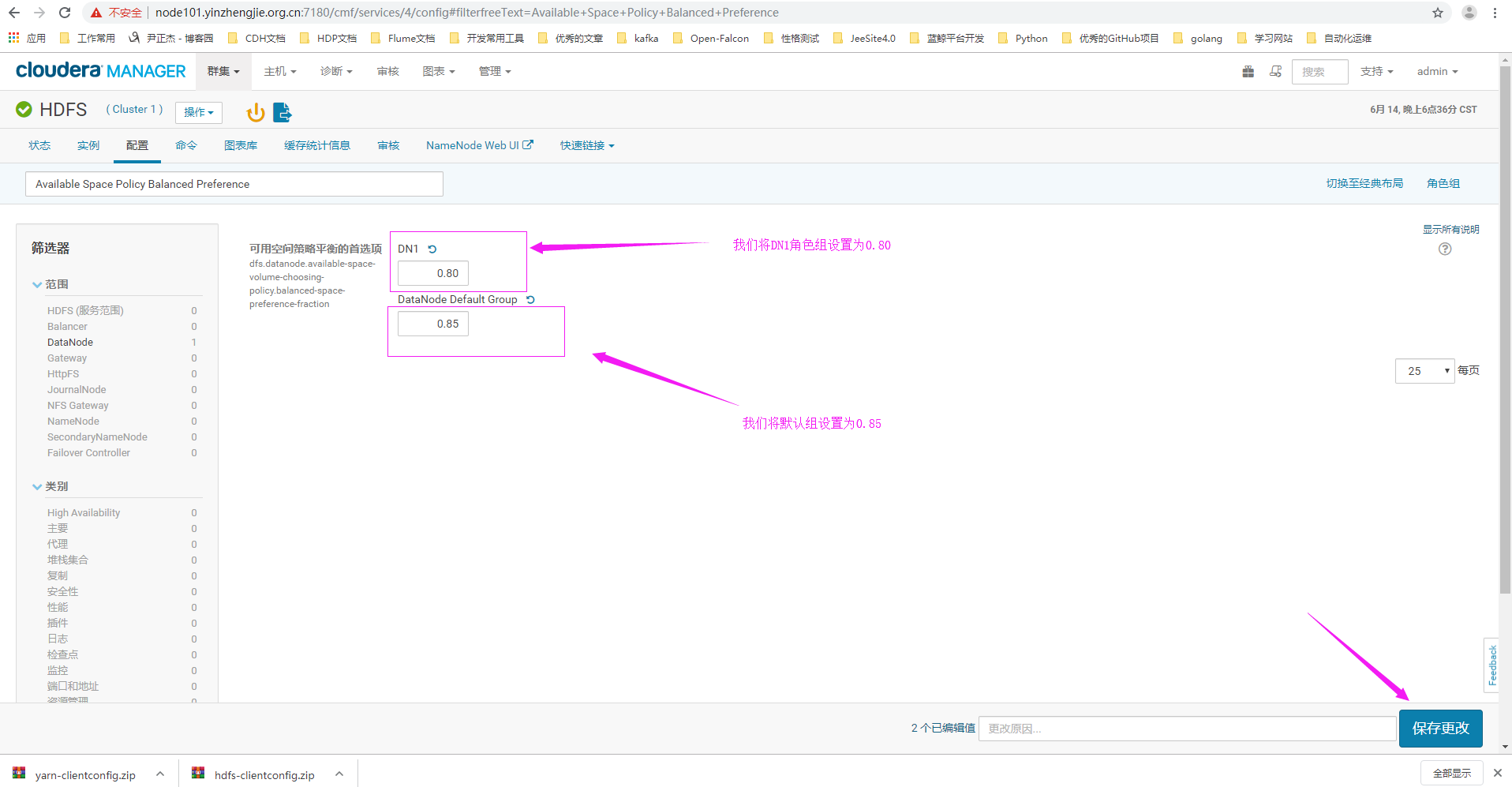
Default Group的Available Space Policy Balanced Preference参数需要设置为0.85,DN1的Available Space Policy Balanced Preference参数设置为0.8。
解决方案:
异构集群是Hadoop运维中比较棘手的一个问题,因此我们推荐大家在新建集群时尽量使用相同的硬件(工作节点)以避免各种麻烦。但现实中由于企业规划不佳,采购限制等诸多原因,很可能出现异构的情况,因此我们需要具备一定的应对能力。
1>.使用正确的用户名密码登录CM界面,点击hdfs服务
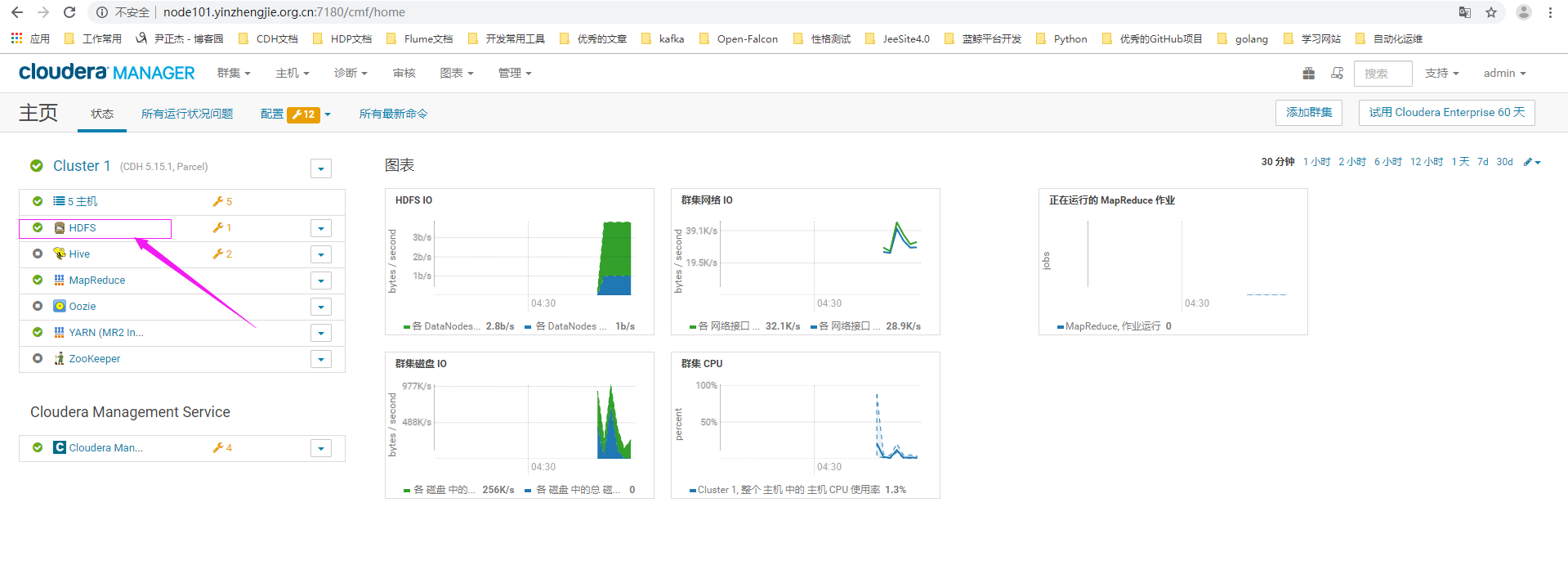
2>.进入HDFS服务管理界面后,点击"配置",再点击"角色组"
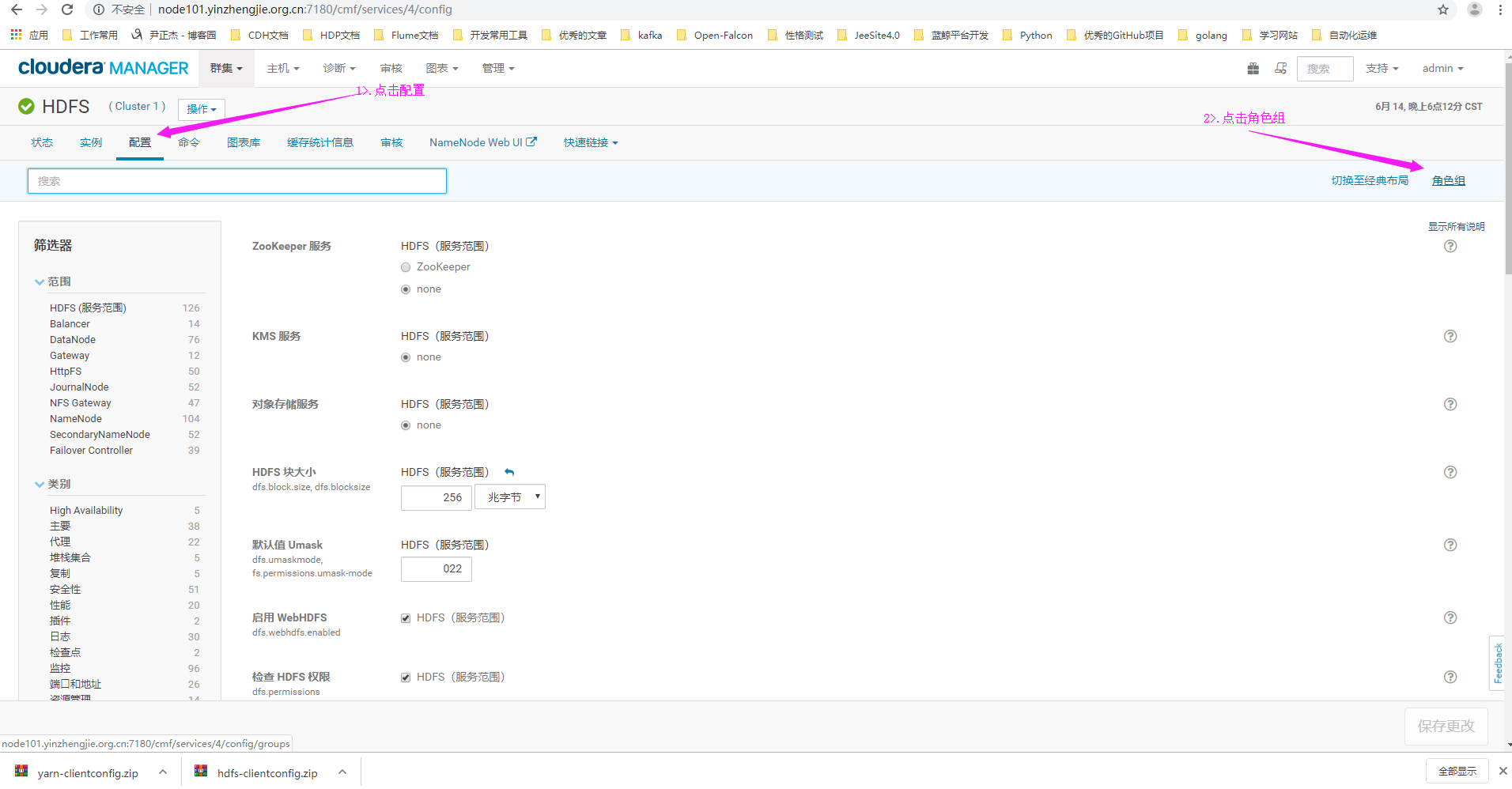
3>.点击"创建"按钮来创建一个自定义的角色组
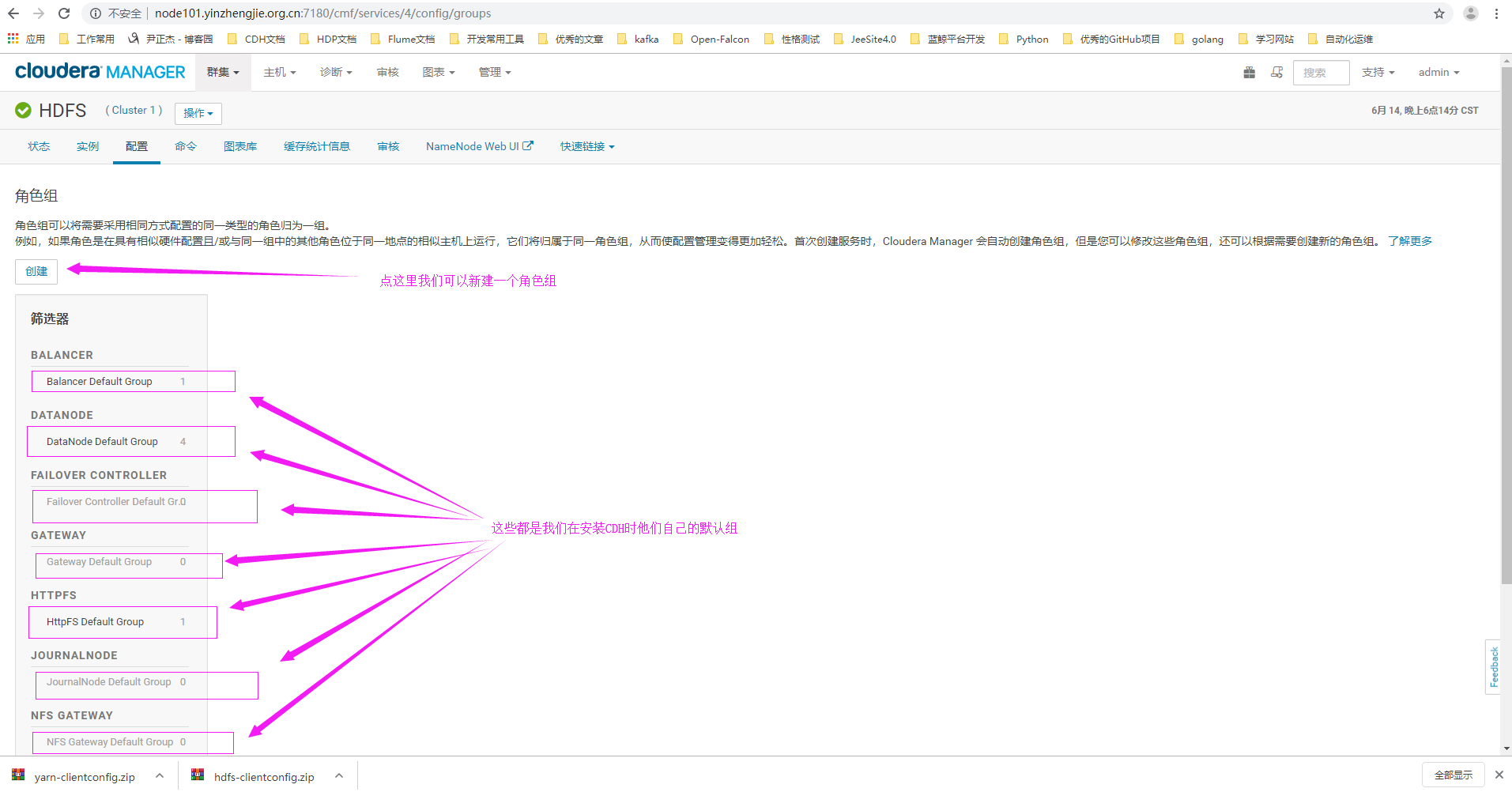
4>.编辑角色组信息
5>.查看Datanode默认组的节点信息
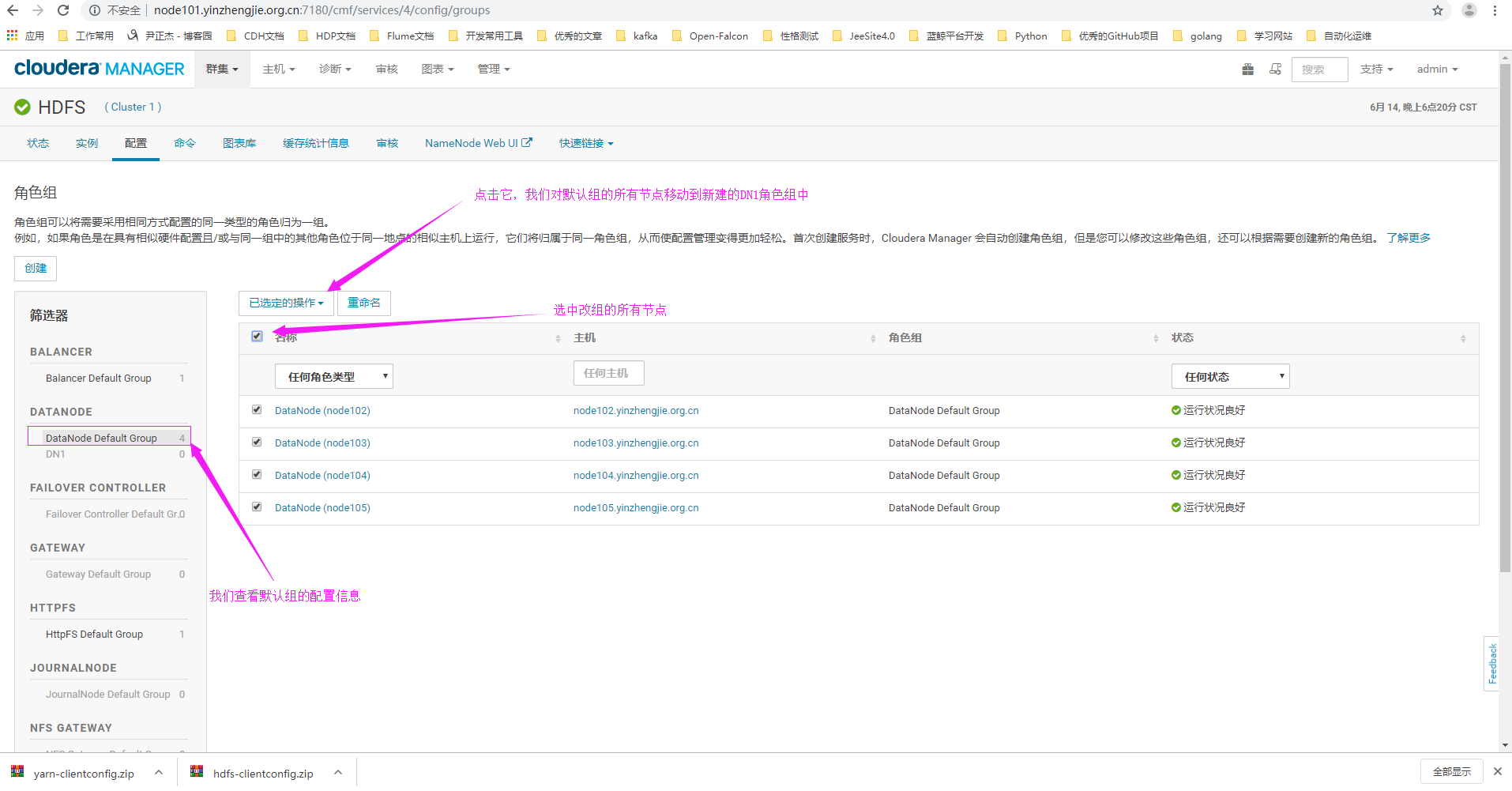
6>.如下图所示,点击“移至另一个角色组”
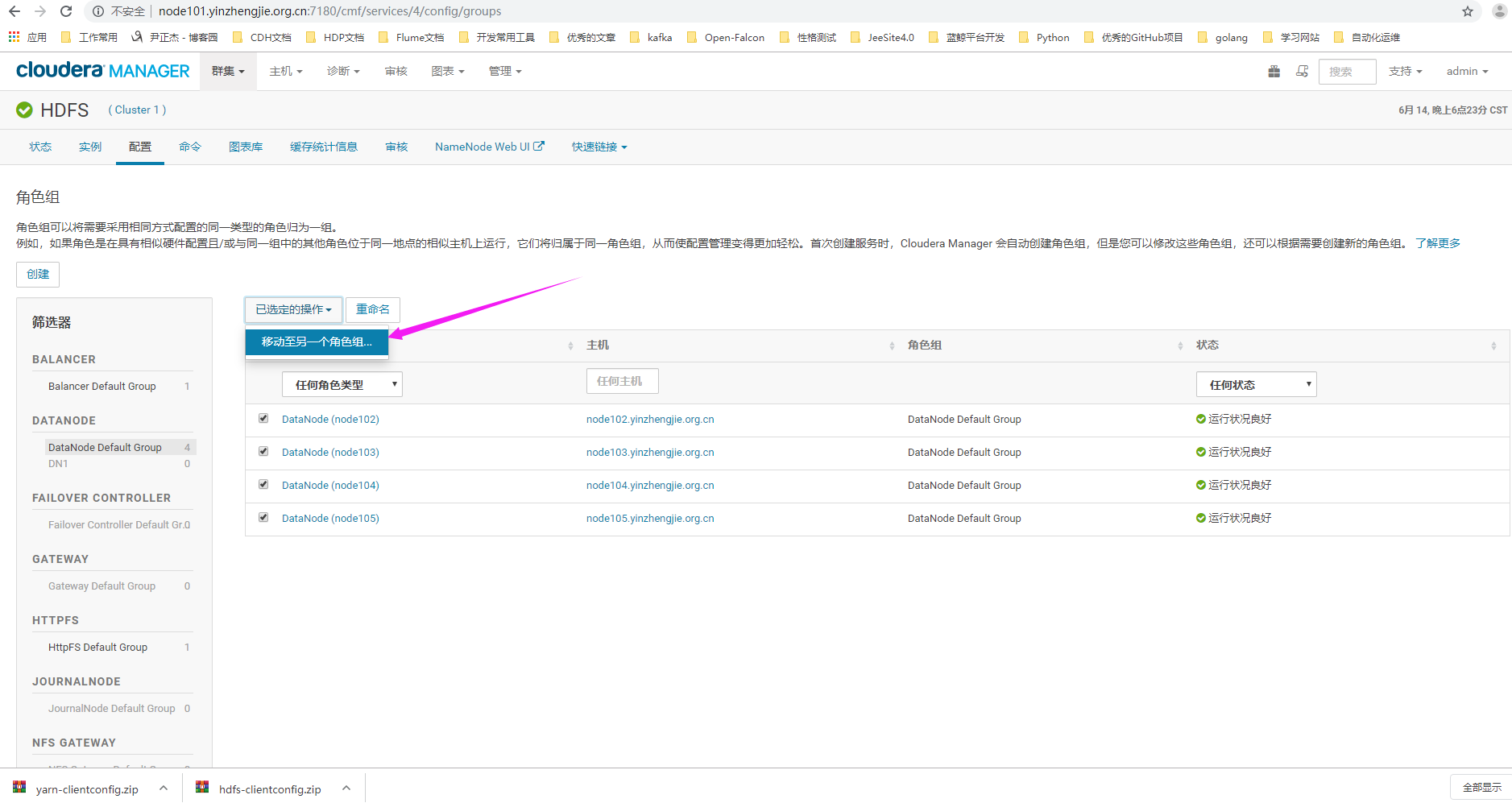
7>.点击"移动"
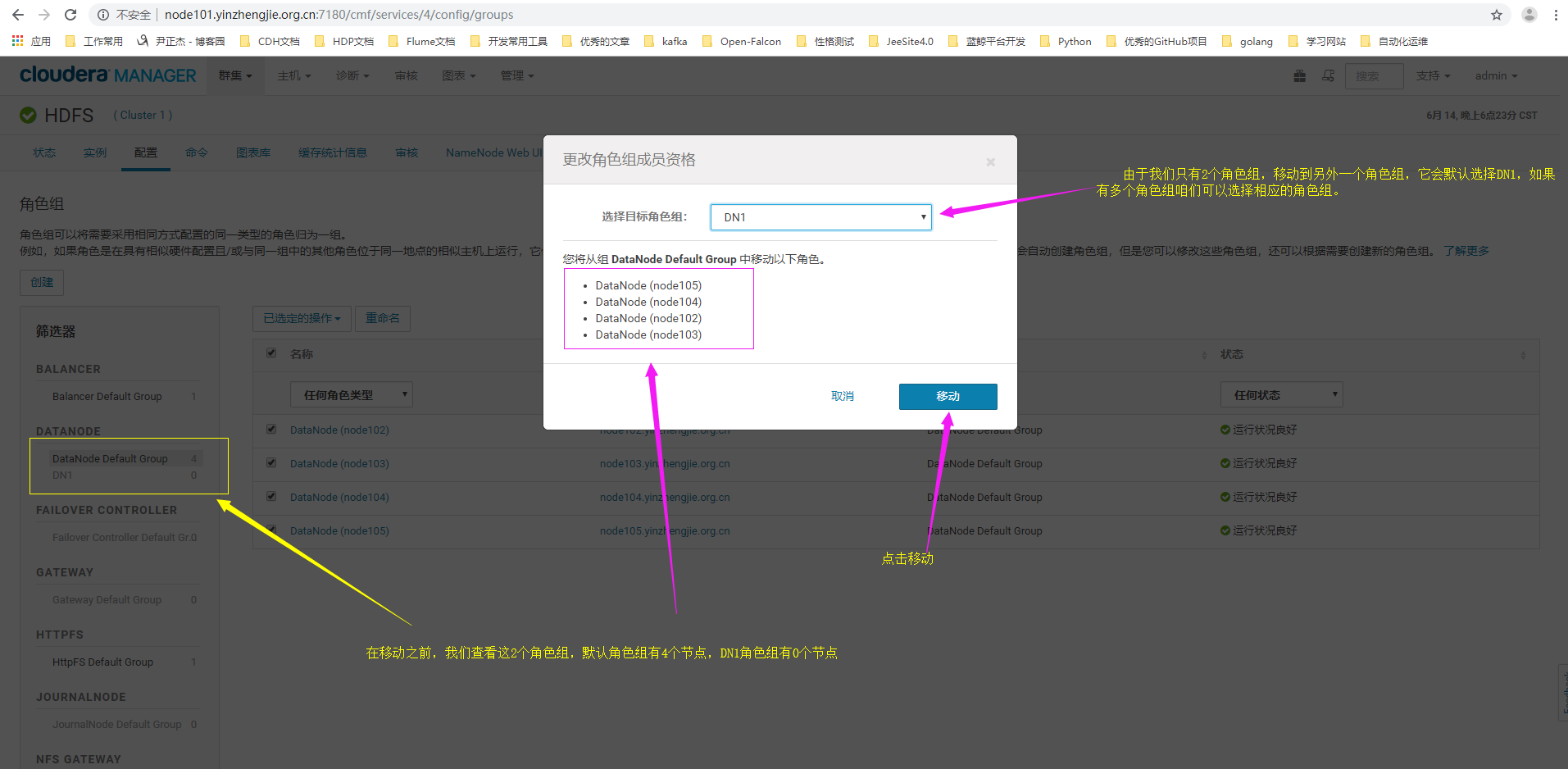
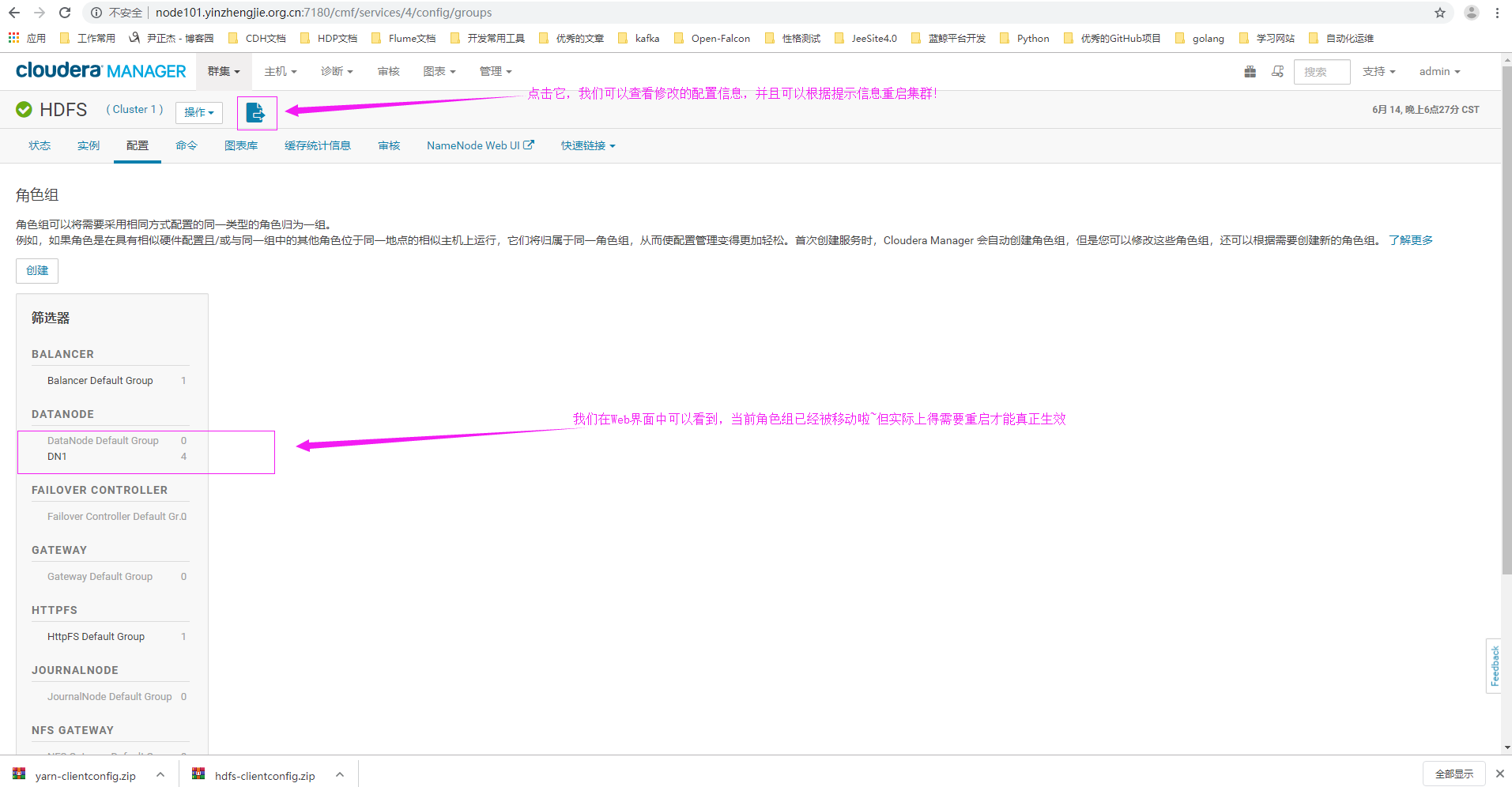
8>.默认角色组已经移动到咱们刚刚新建的dn1角色组,但需要重启才能生效,我们不着急重启,继续看下一步操作。
9>.搜索关键字"DataNode Volume Choosing Policy"
10>.搜索关键字“Available Space Policy Balanced Preference”
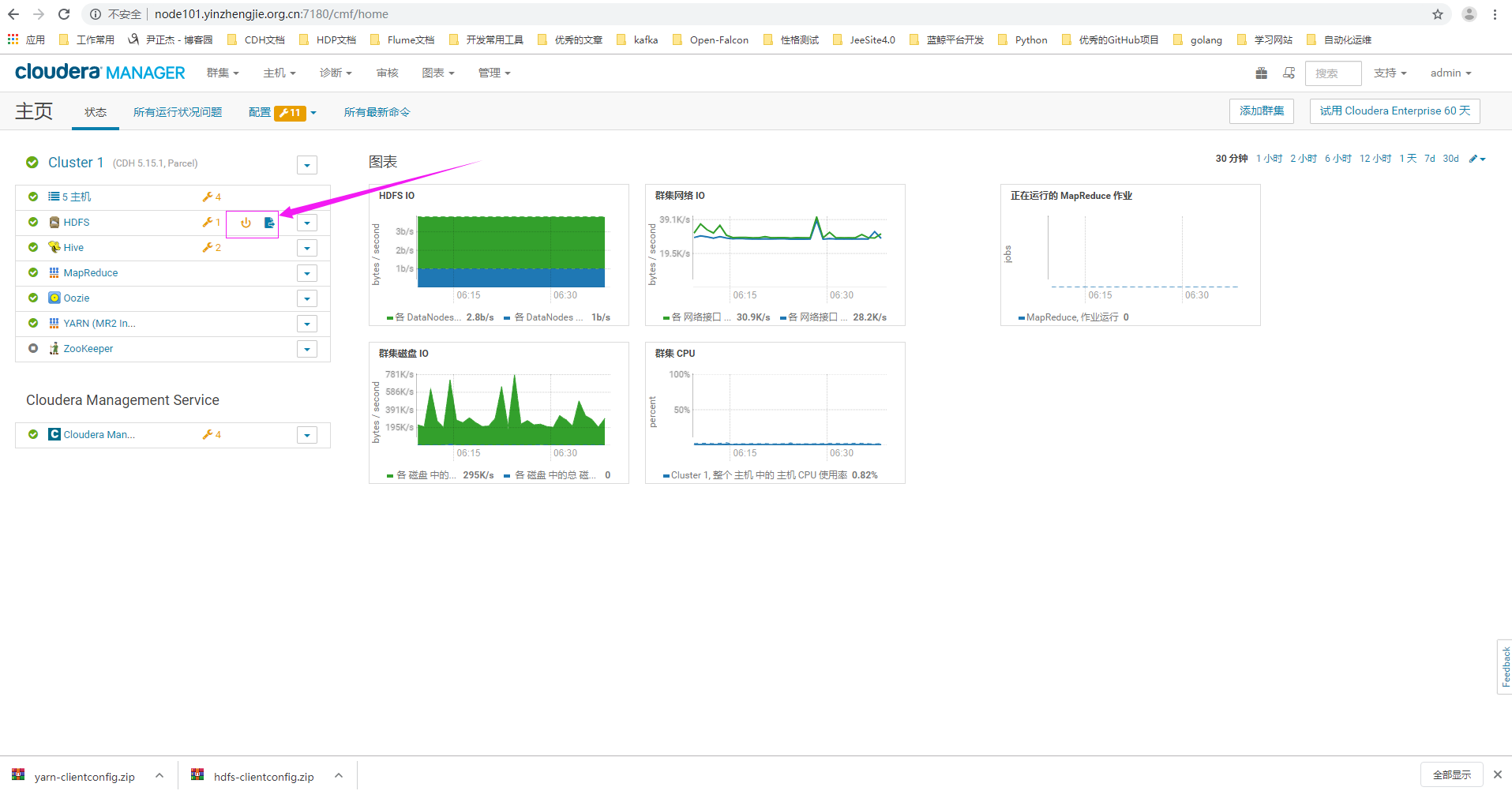
11>.做完上述操作后,我们需要重启HDFS集群,使得配置生效
三.将新节点加入集群
问题描述: 正式地将新节点加入集群。我们需要将node107.yinzhengjie.org.cn这个节点加入CM的托管,并套用Temp1这个主机模板从而加入集群。 解决方案: 在实践中集群扩容,损坏硬件更换时都设计到这个操作,因此也要熟练掌握。 我们假设将要加入集群的主机已经配置好环境并启动Cloudera Manager Agent进程,详情请参考:https://www.cnblogs.com/yinzhengjie/articles/11019525.html
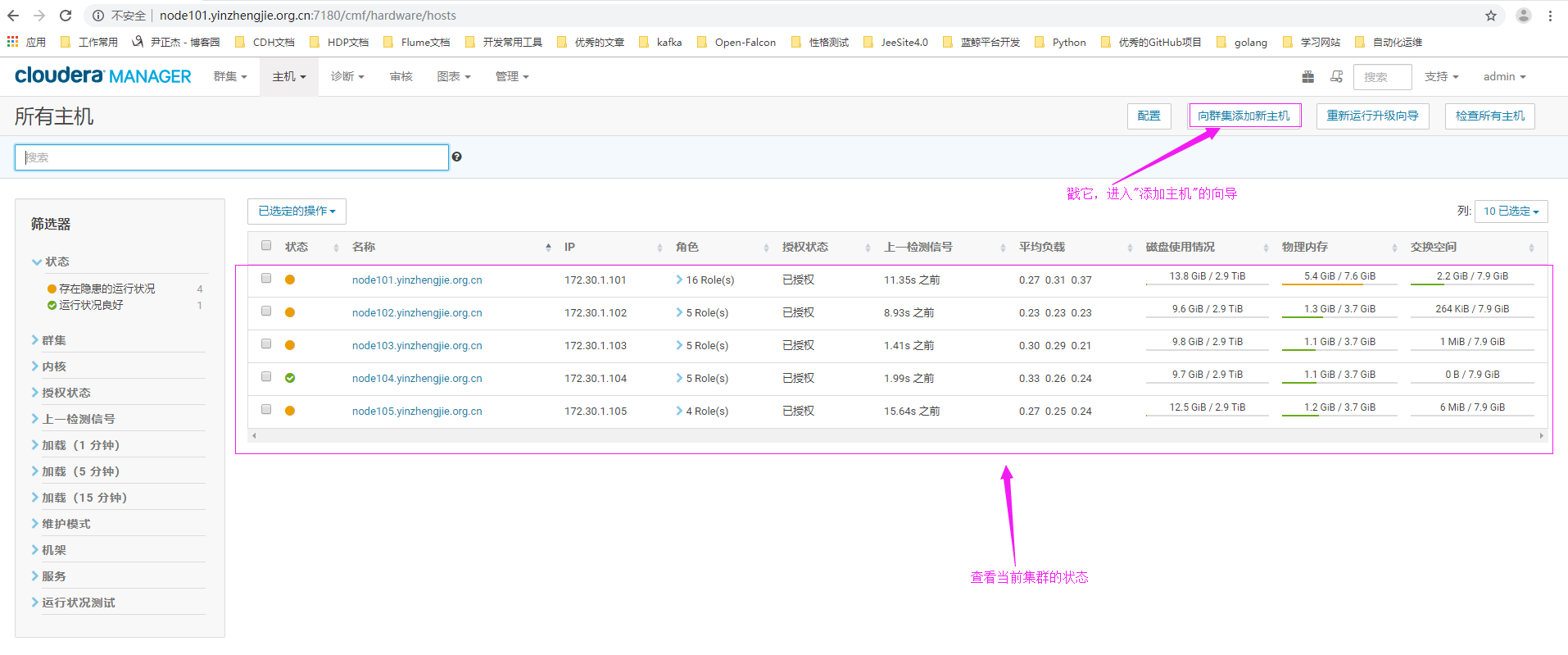
1>.点击“所有主机”
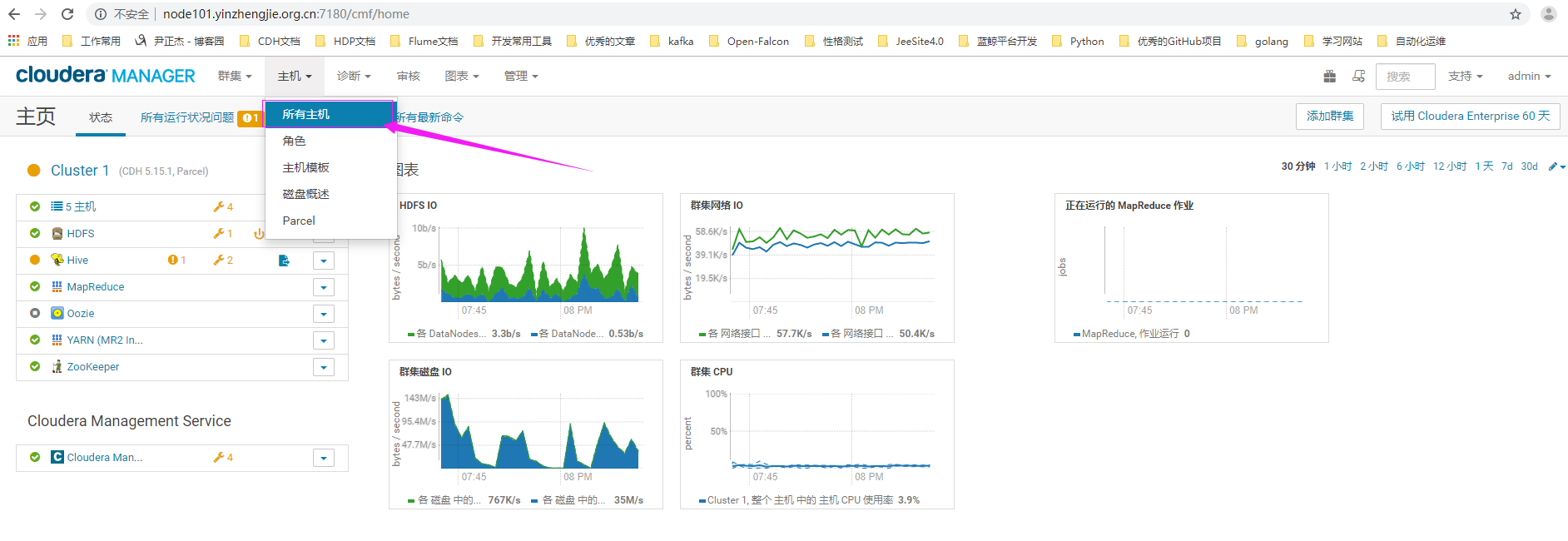
2>.点击"向集群添加新主机"
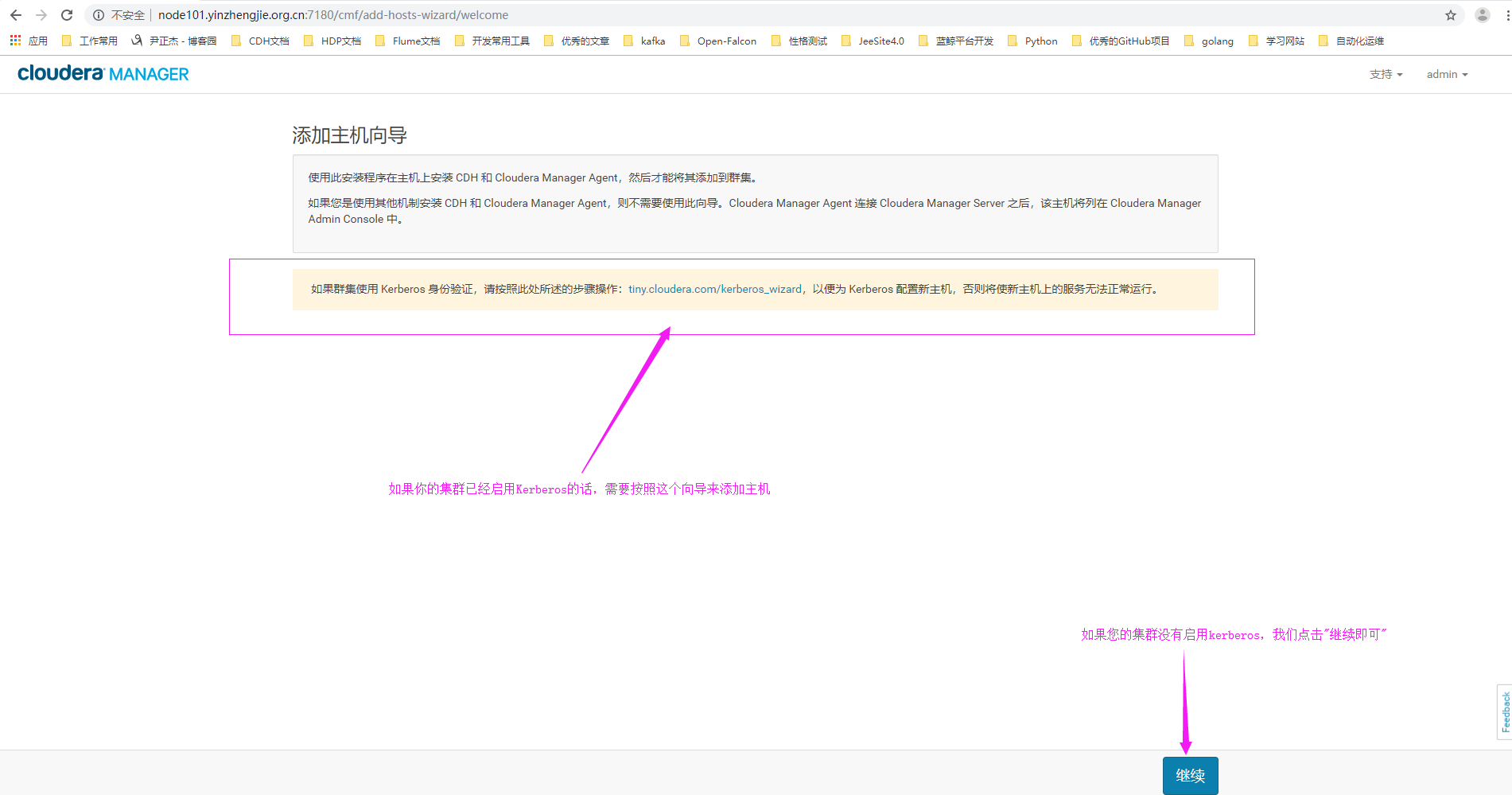
3>.进入"添加主机向导"
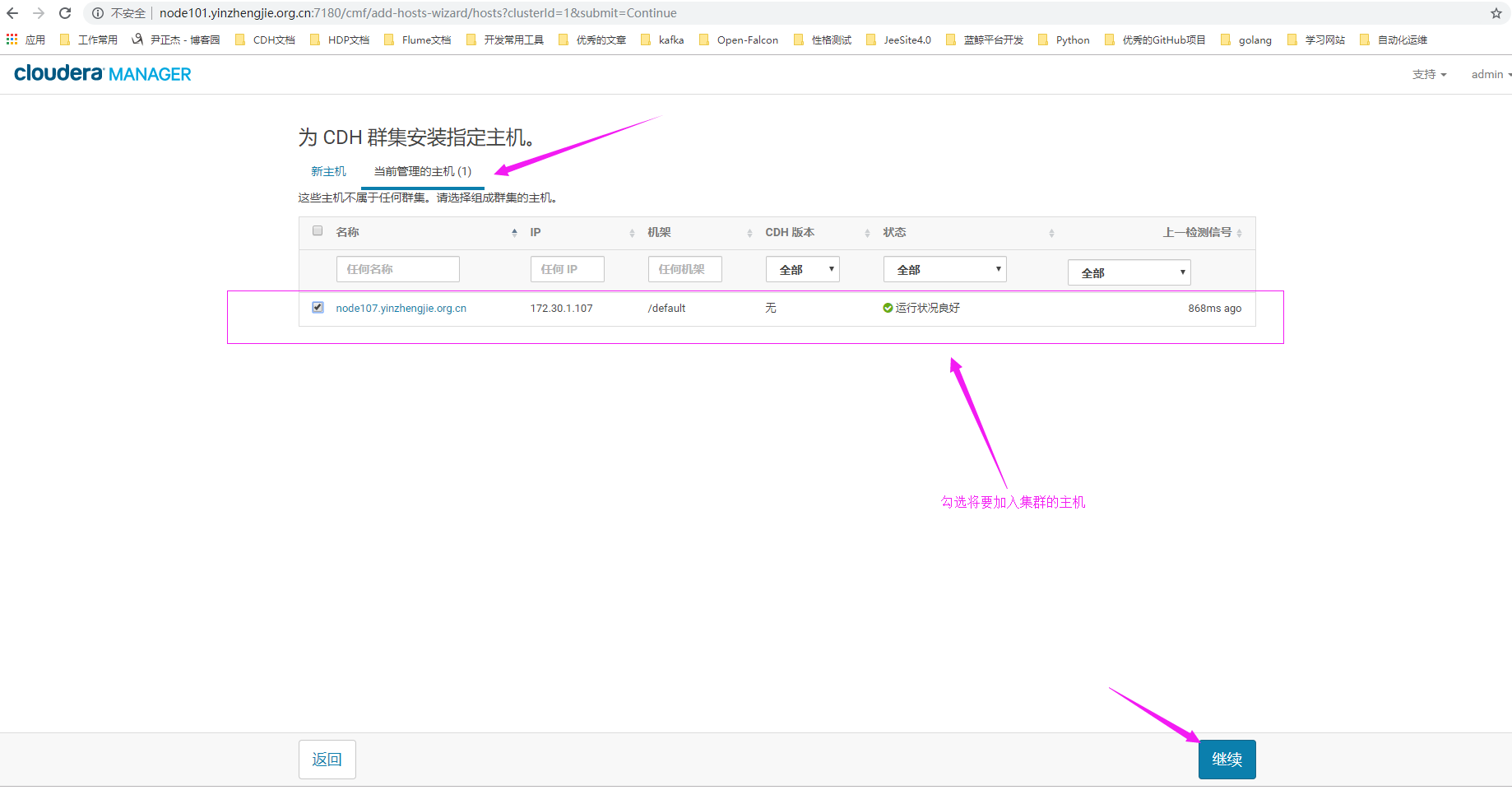
4>.为CDH集群安装指定主机
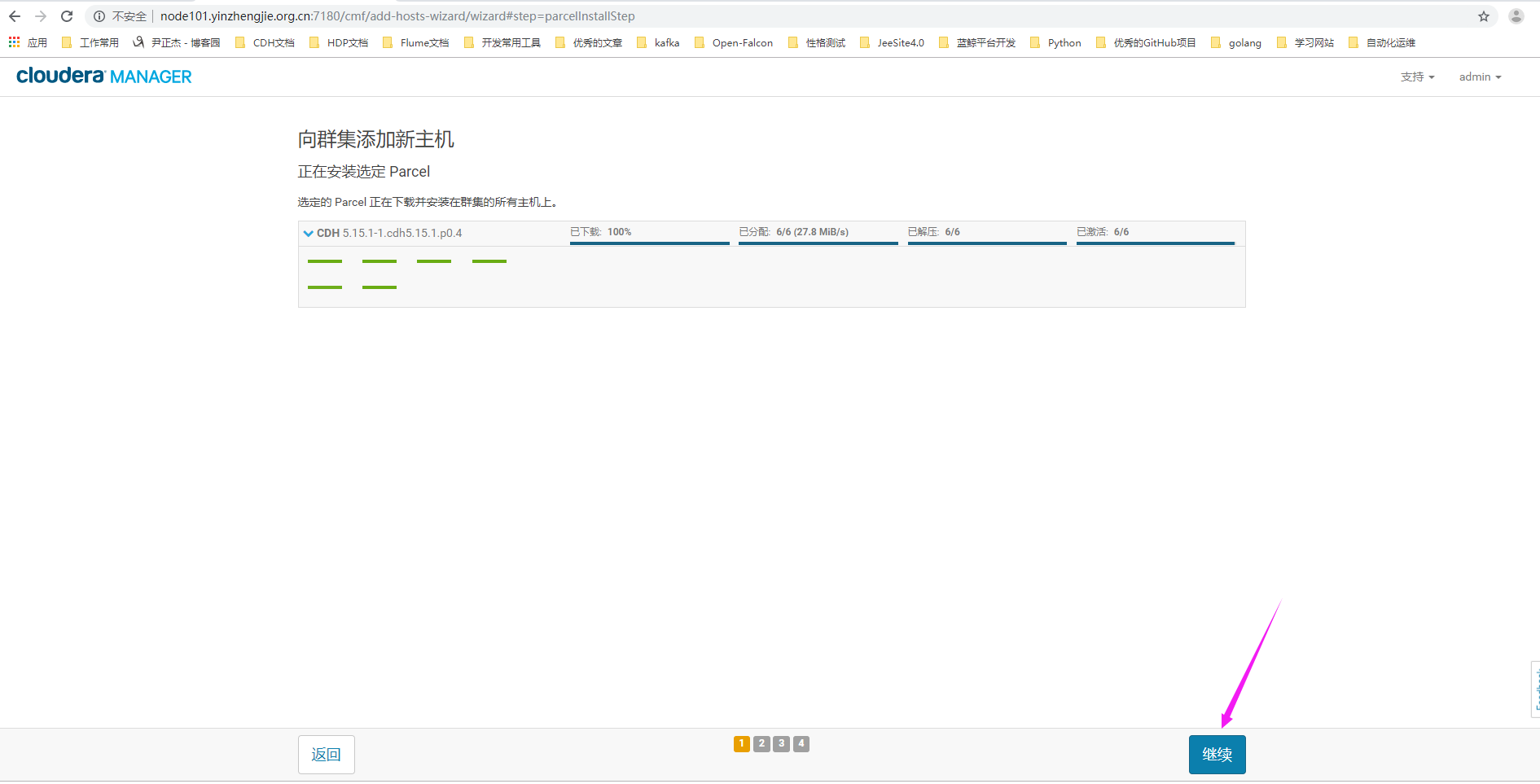
5>.等待主机激活完毕后,点击"继续"
6>.点击继续
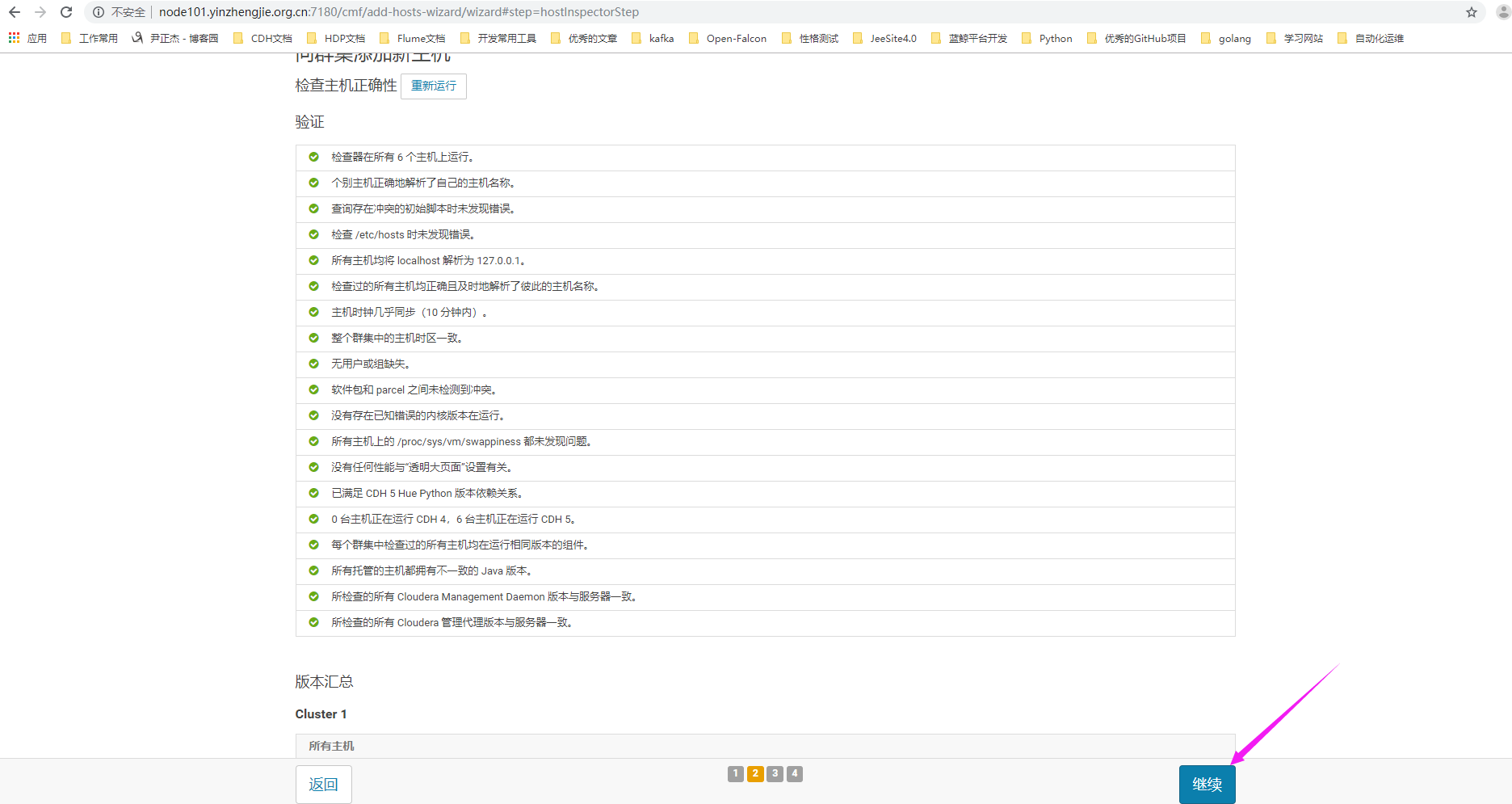
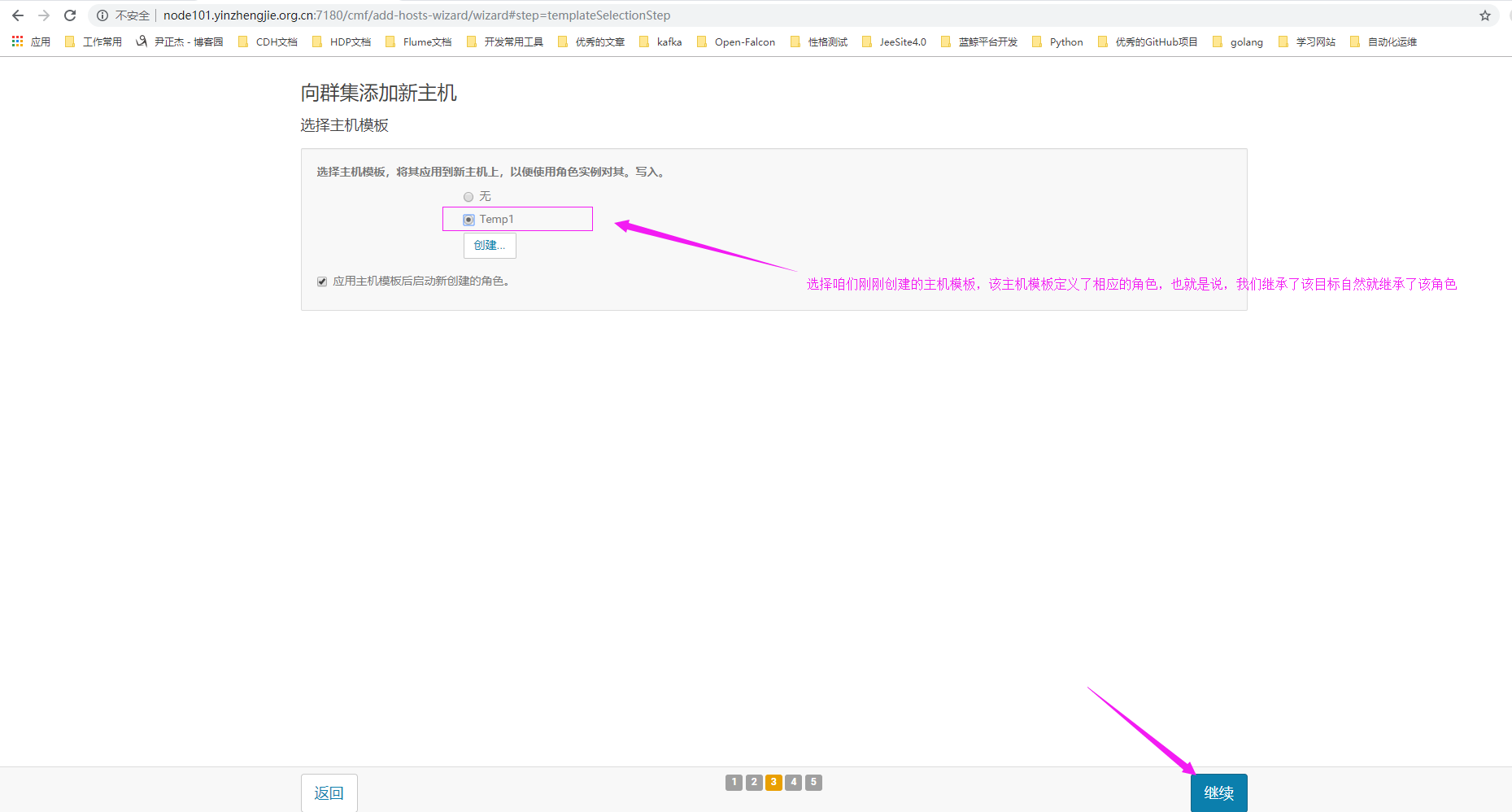
7>. 选择咱们之前创建的主机模板(您选中的模板有对应的角色,而新加入的节点将来就会继承该主机模板的角色)
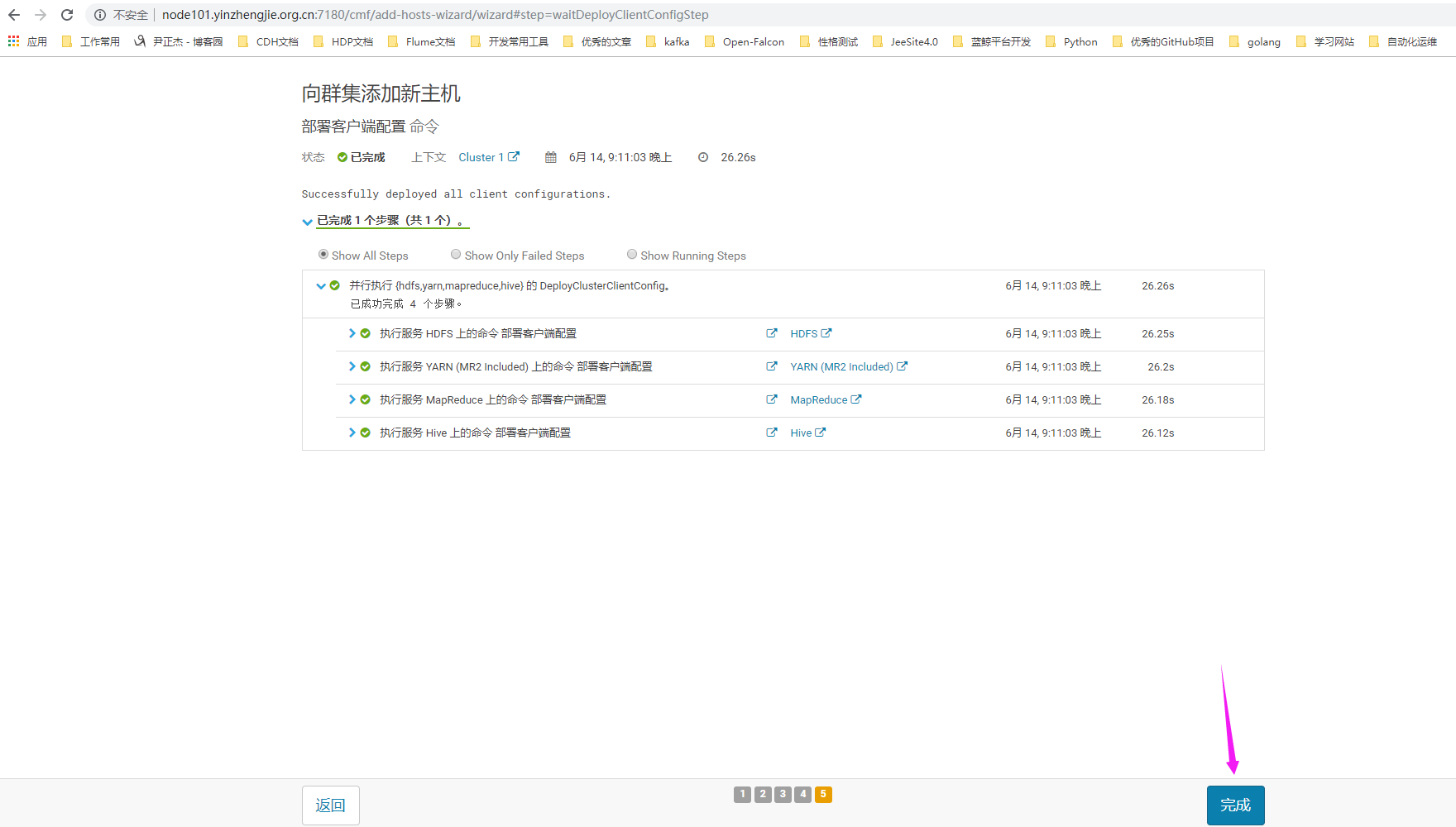
8>.等待集群重启完毕
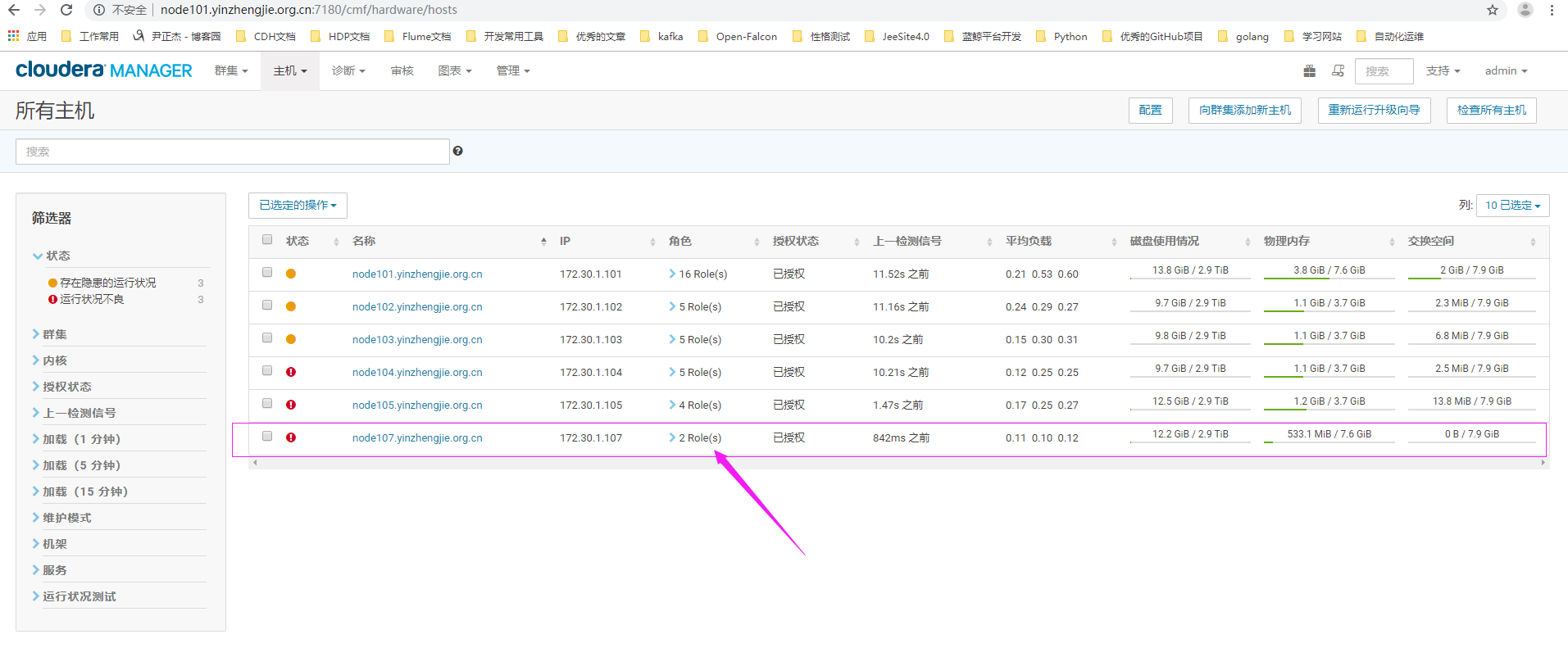
9>.主机扩展成功(需要注意的是,如果在第7步骤没有选择对应的主机模板也没事,只要agent成功加入集群后,我们选中相应的节点并点击下图的"已选定操作",选择"应用主机模板"选项就有对应的你之前创建的模板供你选择,选择主机模板后别忘记顺便勾选"应用主机模板后部署客户端配置并启动新创建的角色。"属性)
四.移除CDH集群的节点
1>.点击"主机",选择"所有主机"
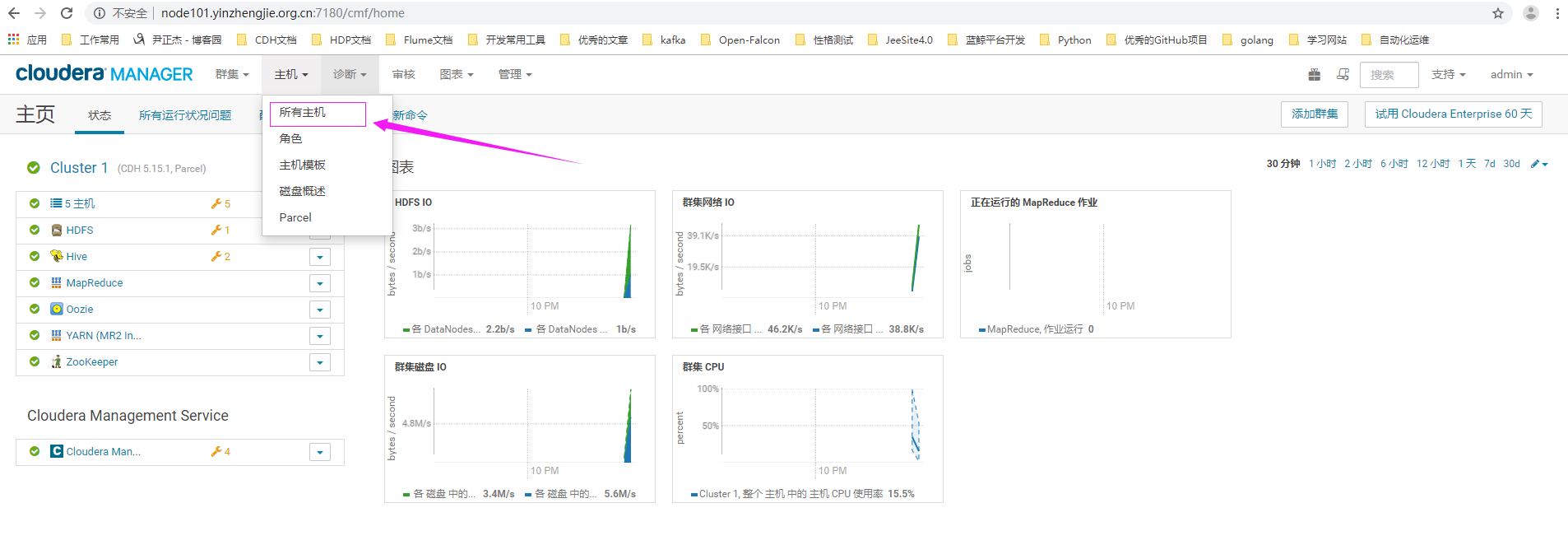
2>.勾选需要下线的主机
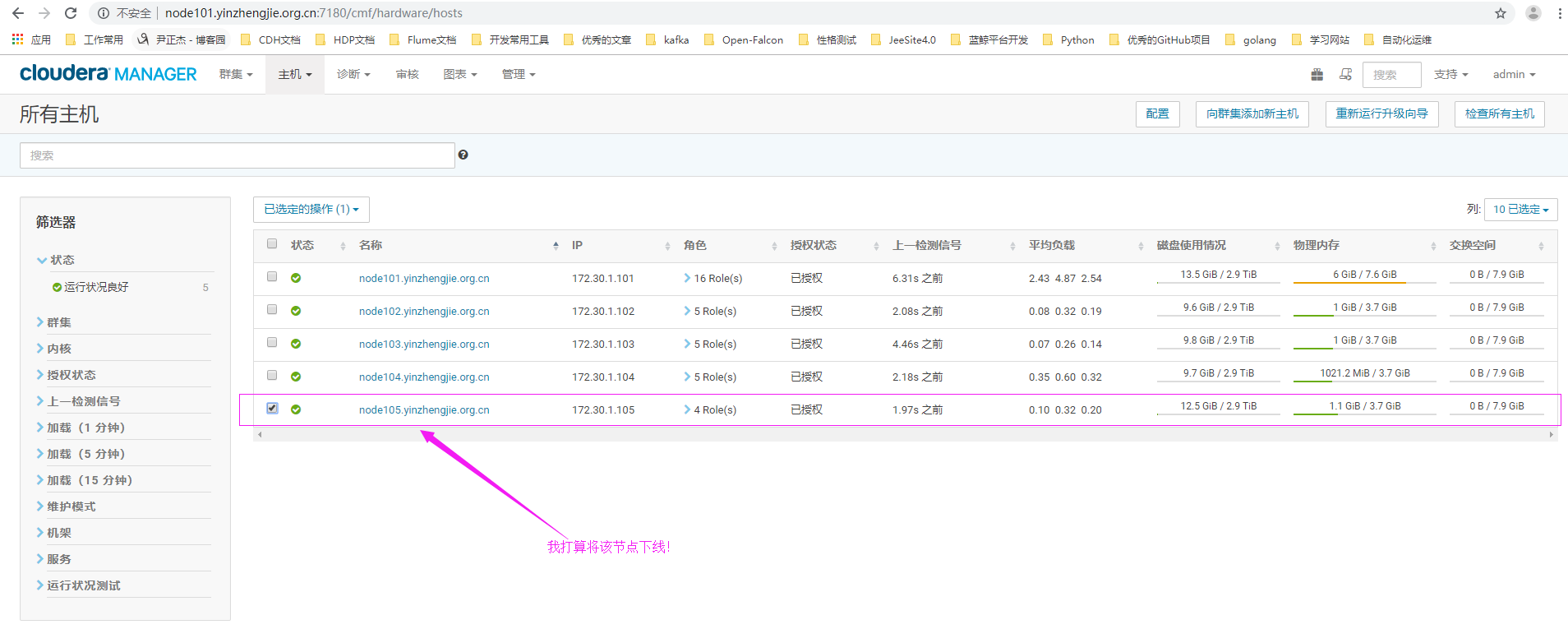
3>.我们点击"已选定的操作"(英文为"Actions for Selected "),选择"Begin Maintenance"(表示进入维护模式,进入维护模式会听到该主机的服务)
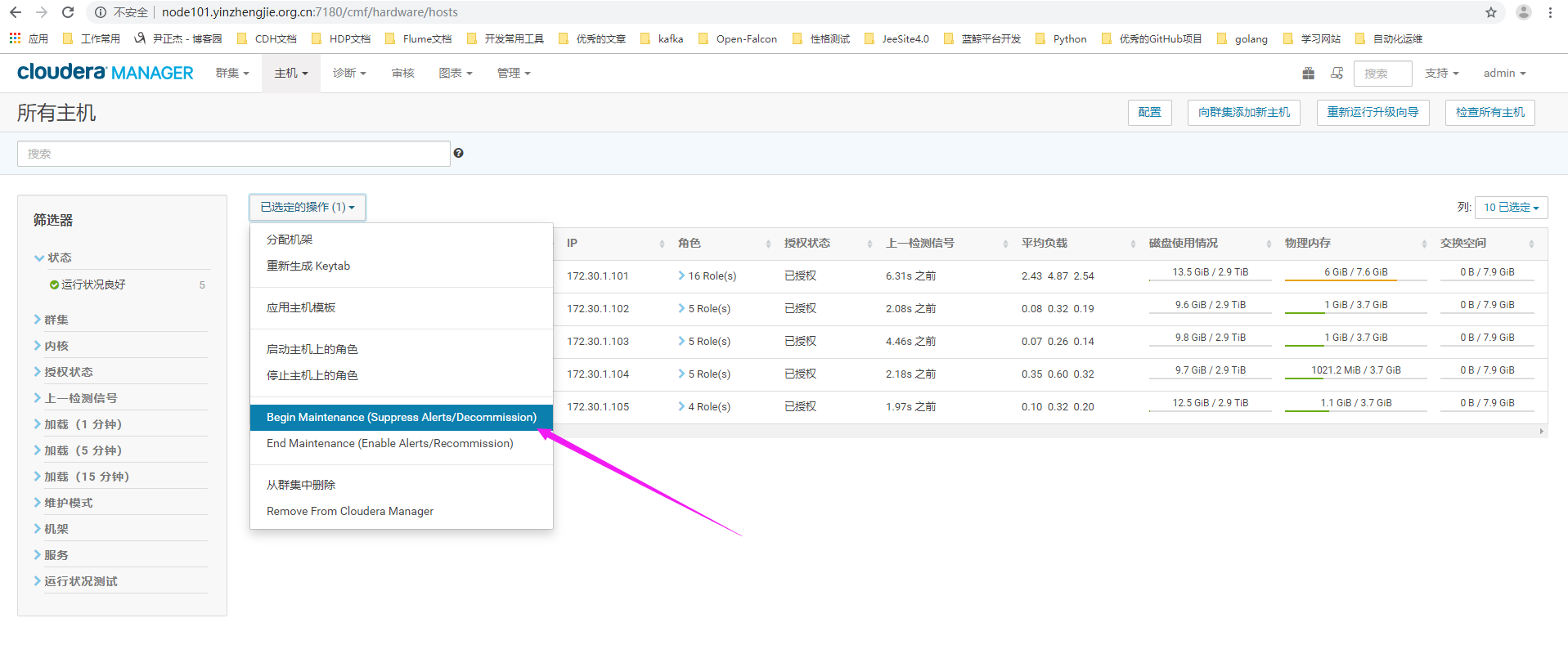
4>.点击"Begin Maintenance"
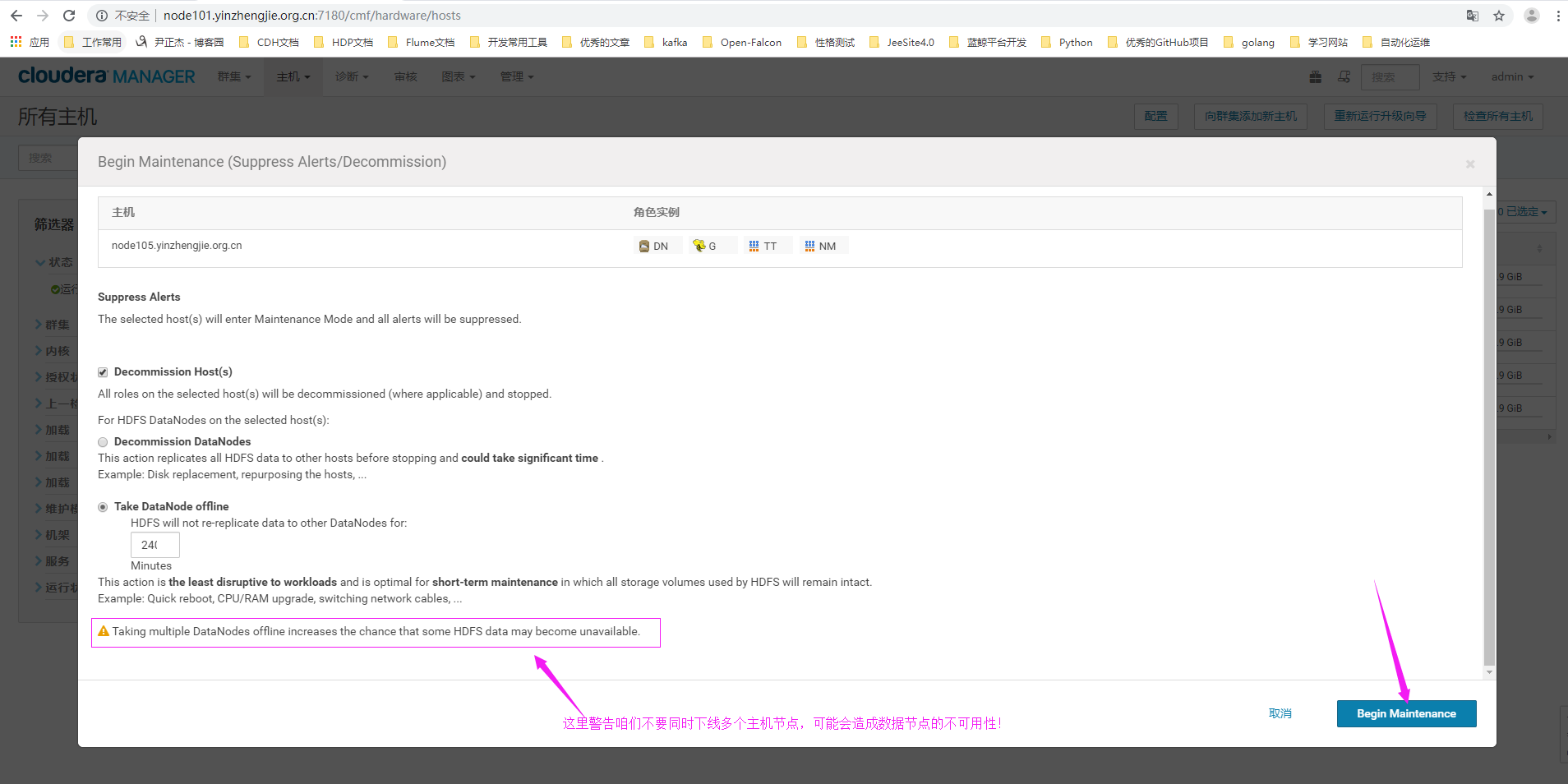
5>.主机进行授权命令
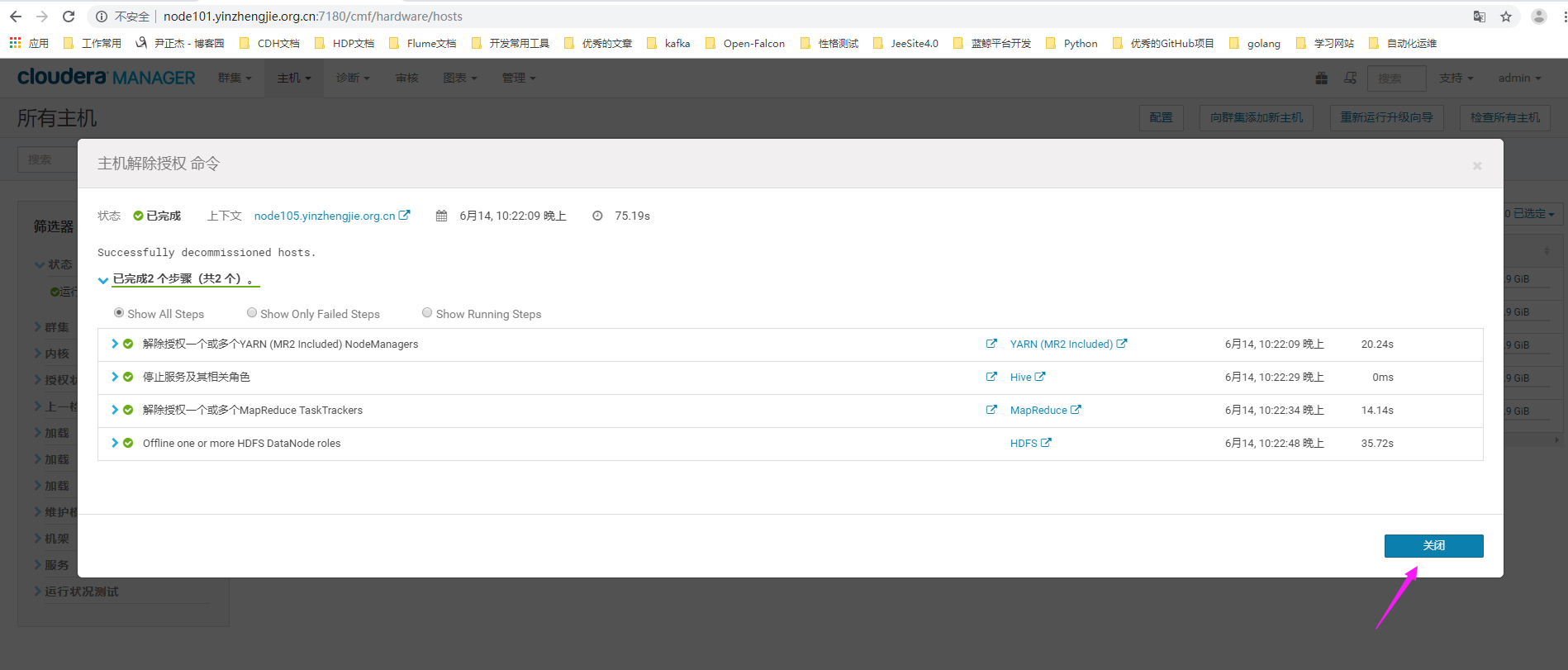
6>.主机进入维护模式,我们需要手动停掉agent进程
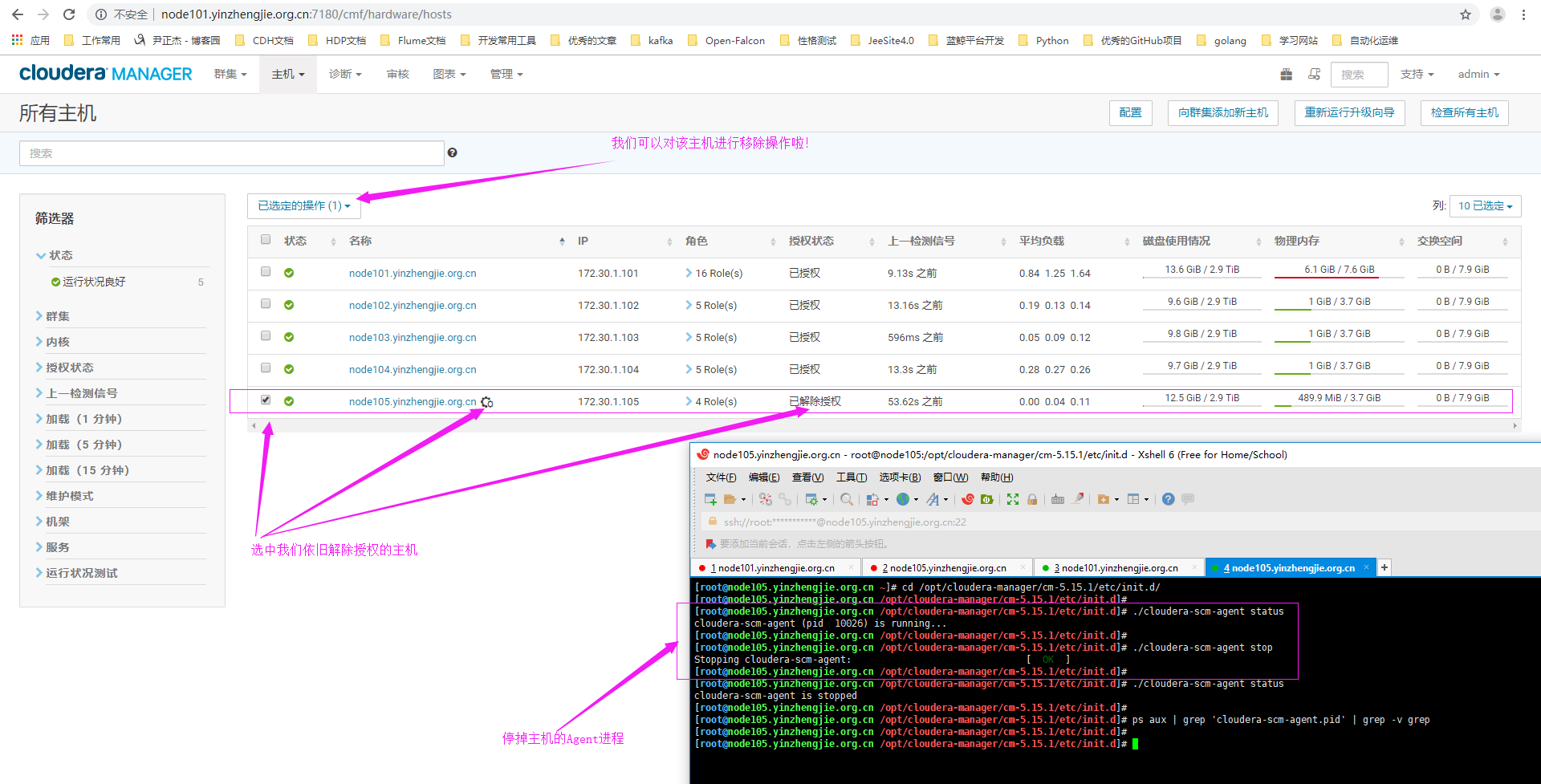
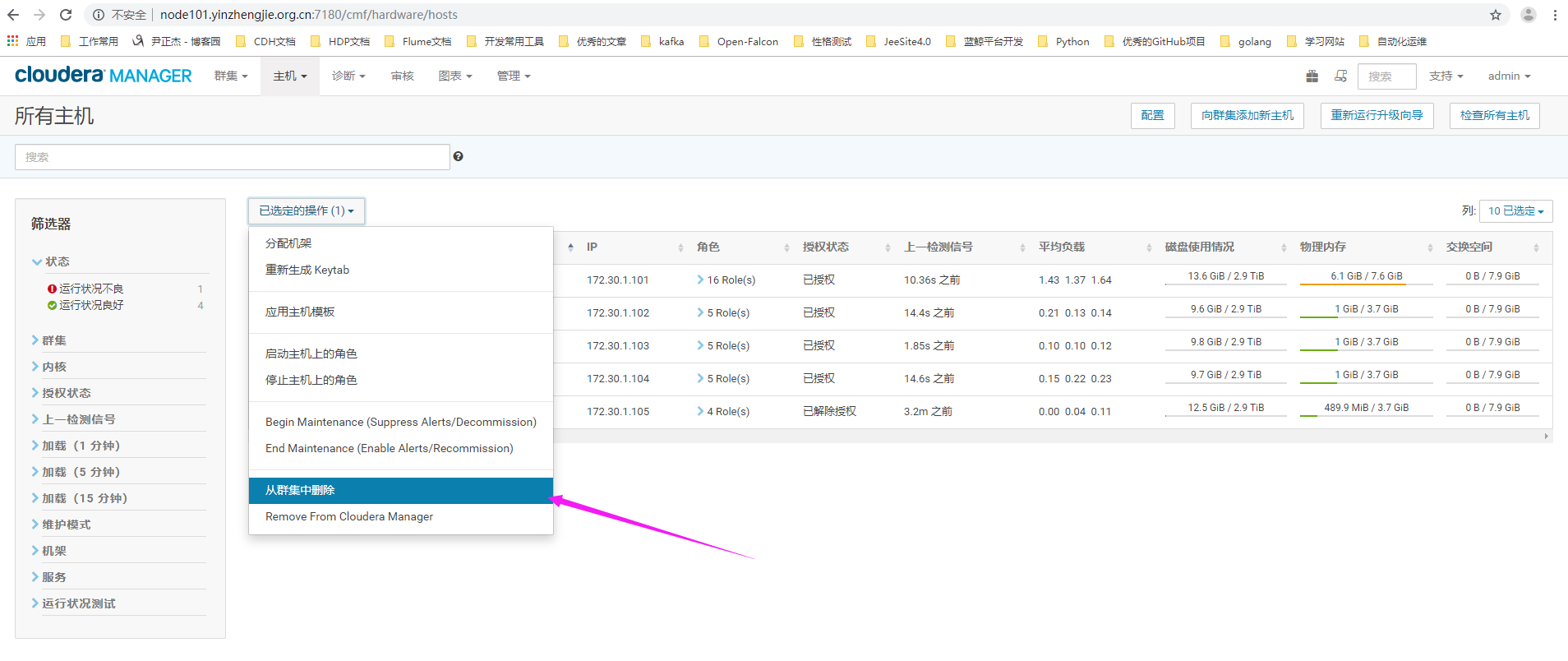
7>.选择从集群中删除
8>.点击确认
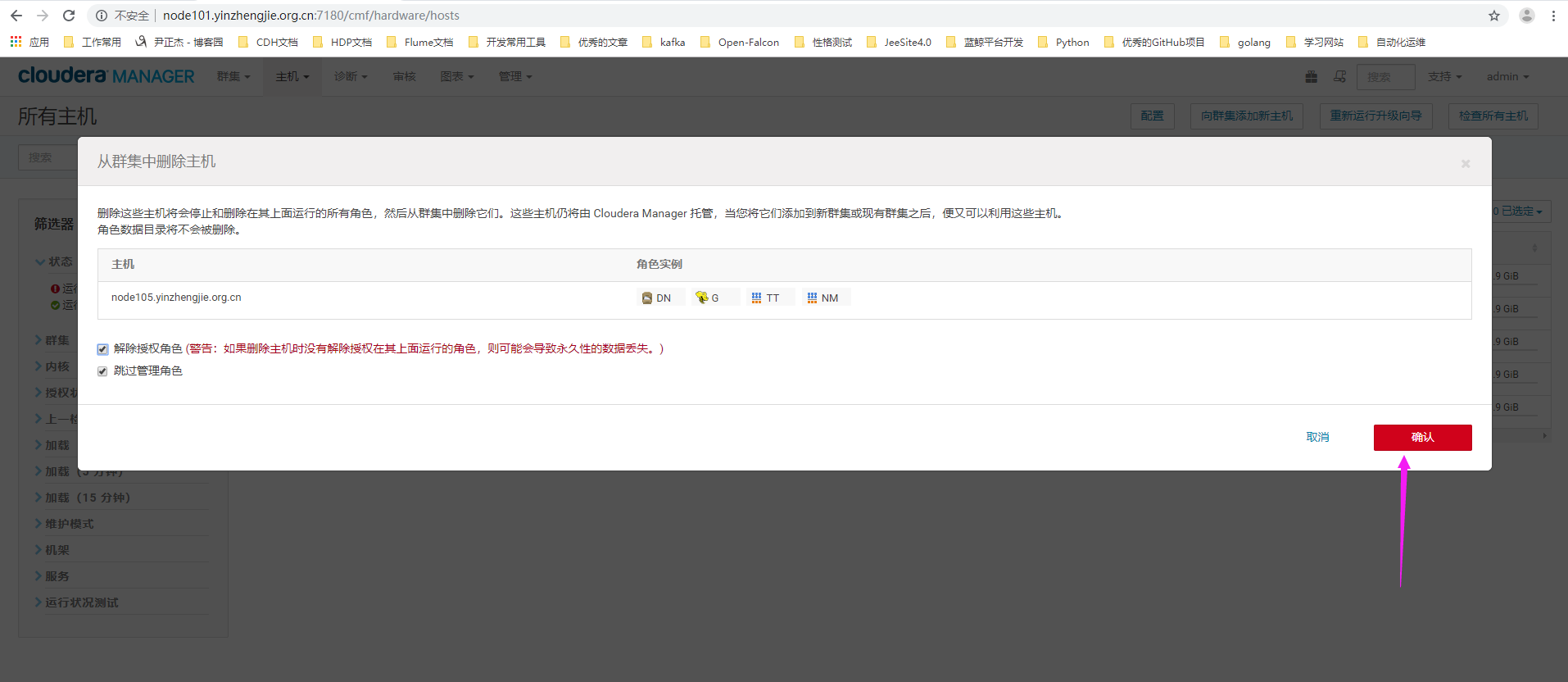
9>.删除主机上的角色(等待时间较长)
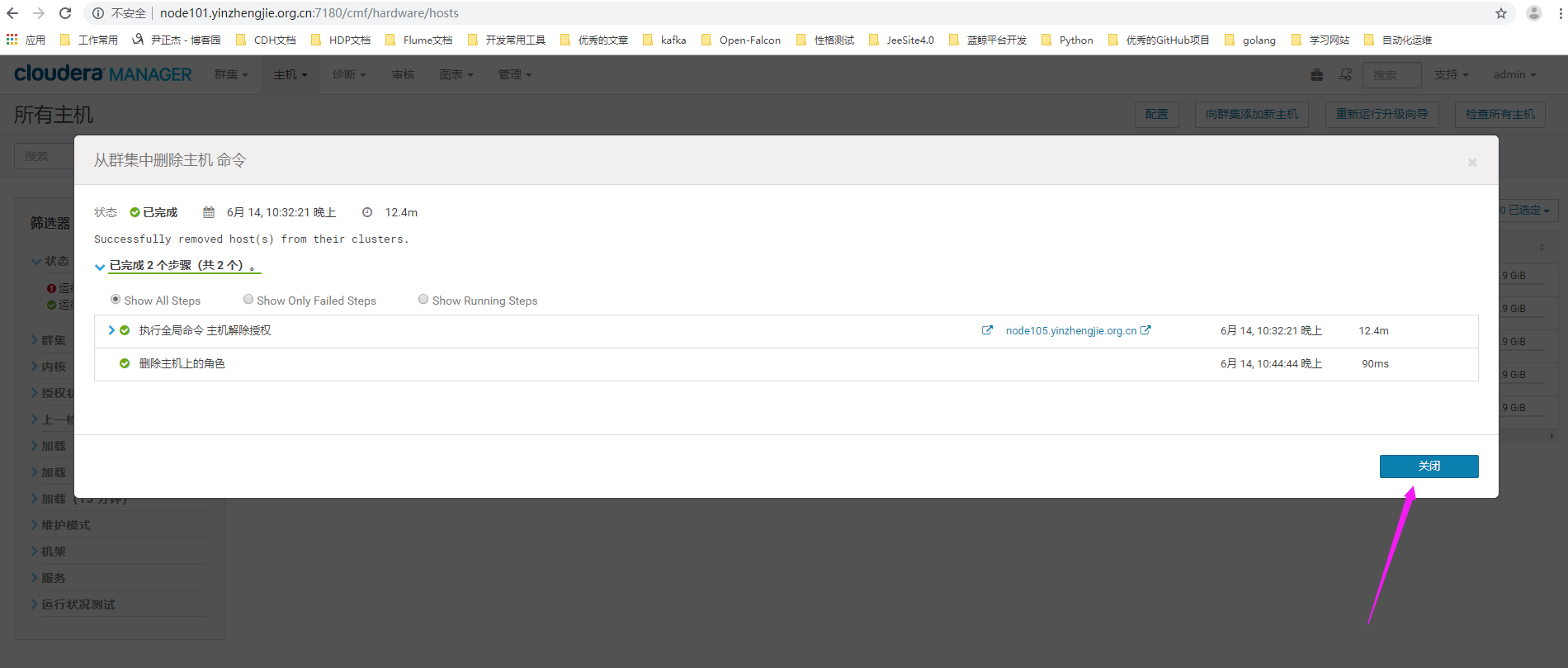
10>.角色移除成功
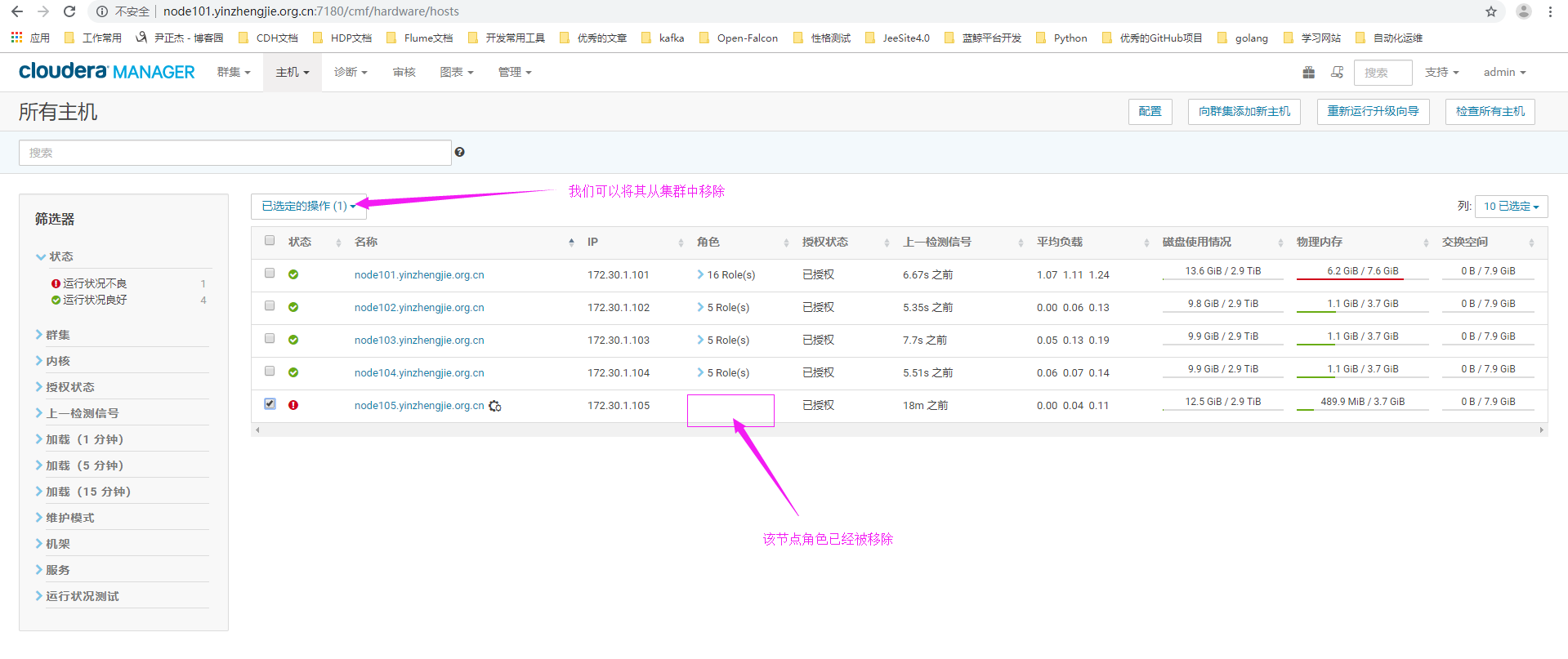
11>.点击"Remove From Cloudera Manager"
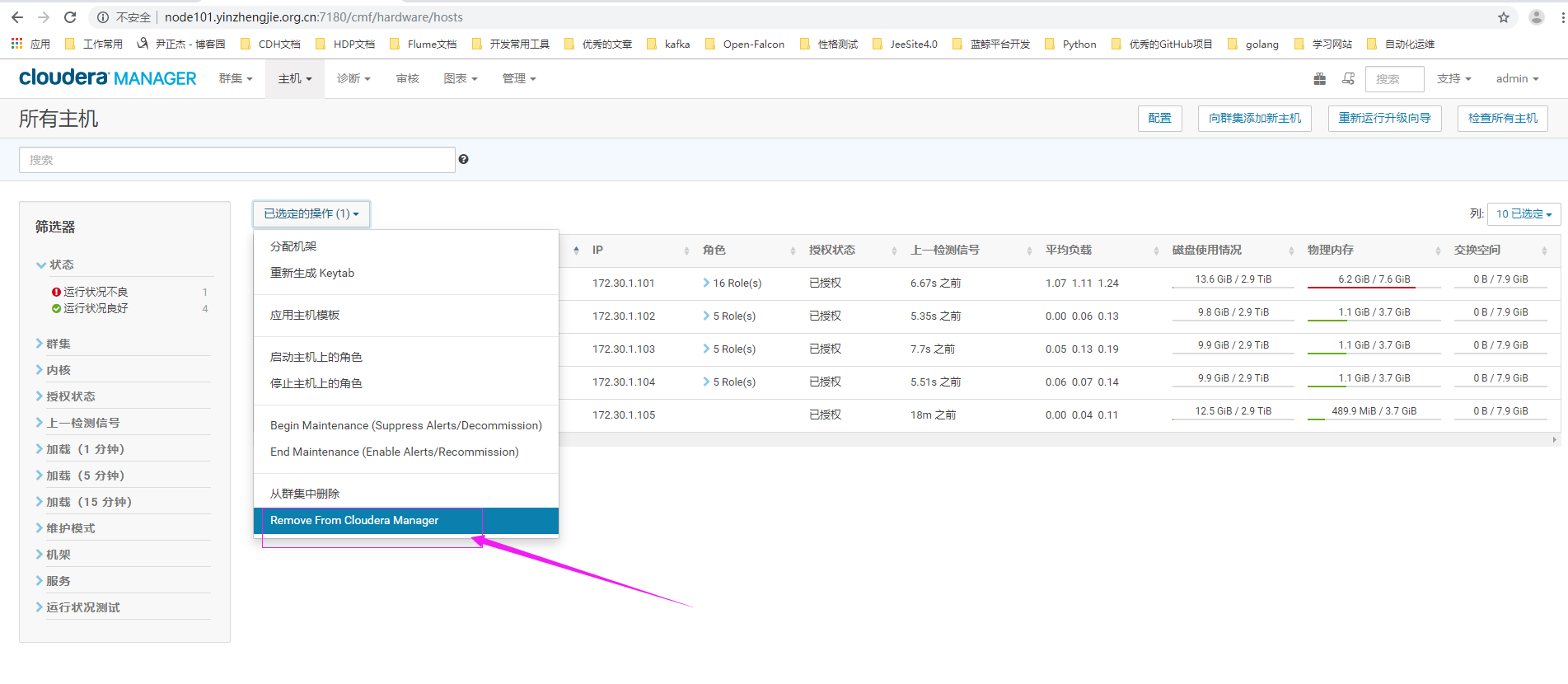
12>.点击"确认"
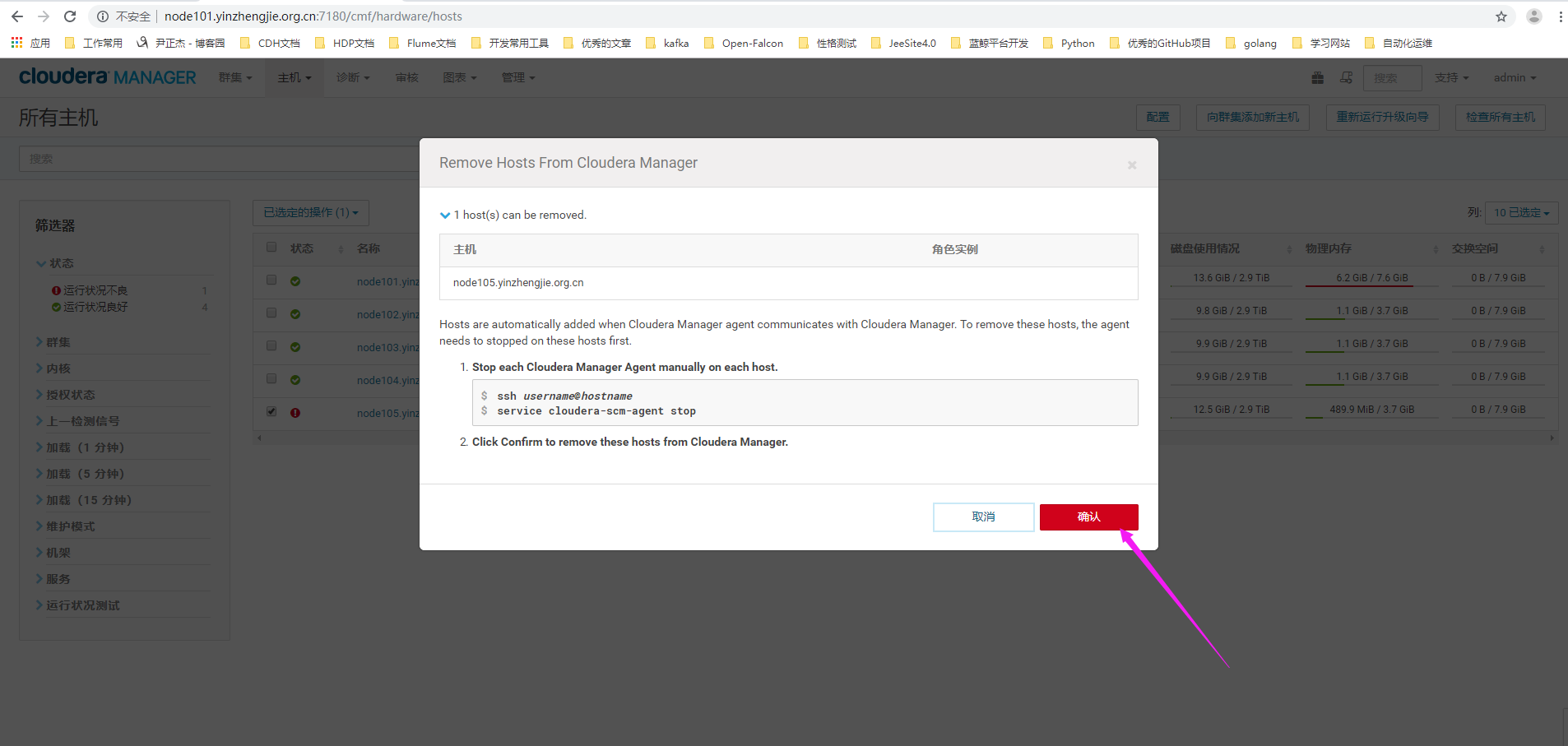
13>.节点移除成功
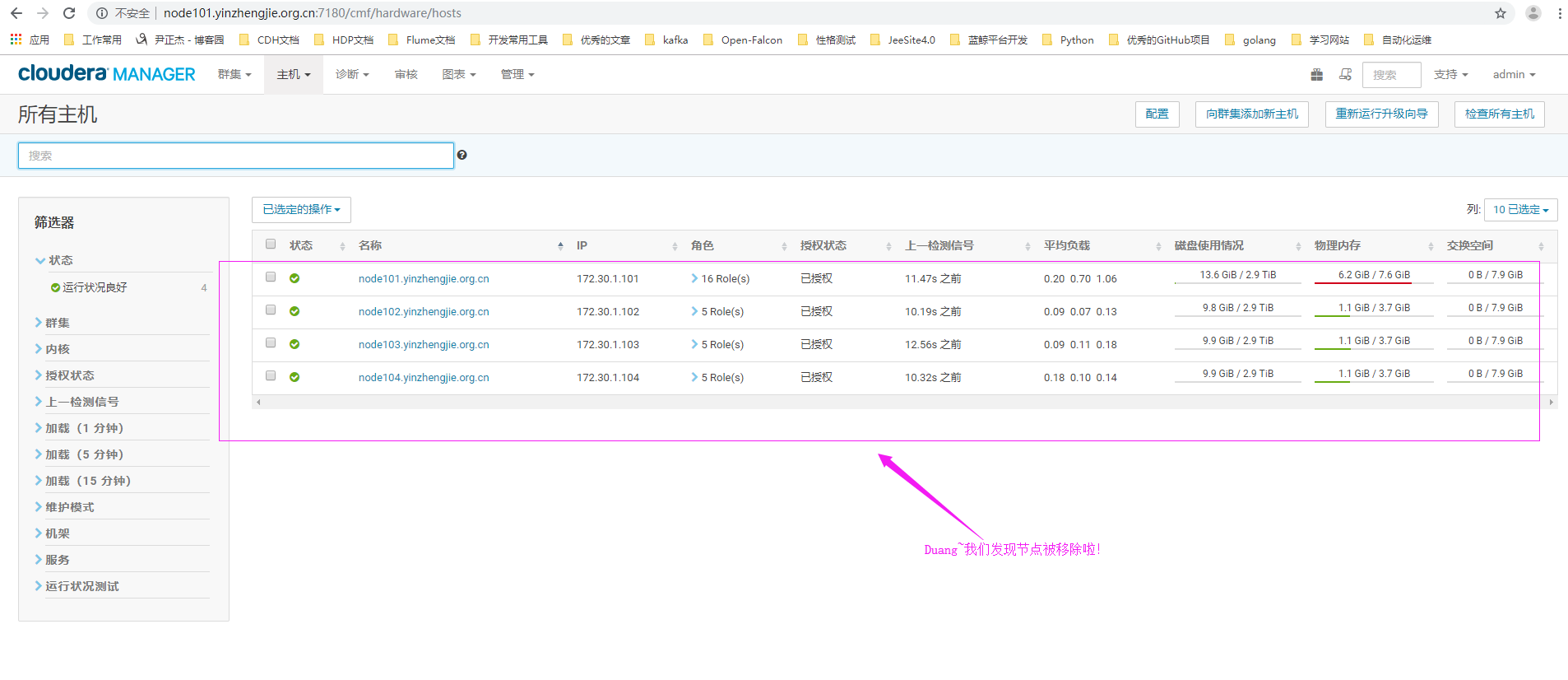
14>.对于 CM Manager 来说,它会把主机元数据全部存放在数据库里,对应的表为"${DATABASE}.HOSTS"(如果你不想从Cloudera Manager WebUI来删除,那咱们就可以考虑直接去数据库干掉他!但是相对来说比较危险,万一你不小心删除错主机就比较尴尬啦~)


mysql> SELECT * FROM HOSTS\G *************************** 1. row *************************** HOST_ID: 2 OPTIMISTIC_LOCK_VERSION: 14 HOST_IDENTIFIER: 5411b2de-f7e8-45de-bde3-6d8aedfed4d5 NAME: node101.yinzhengjie.org.cn IP_ADDRESS: 172.30.1.101 RACK_ID: /default STATUS: NA CONFIG_CONTAINER_ID: 1 MAINTENANCE_COUNT: 0 DECOMMISSION_COUNT: 0 CLUSTER_ID: 1 NUM_CORES: 4 TOTAL_PHYS_MEM_BYTES: 8182054912 PUBLIC_NAME: NULL PUBLIC_IP_ADDRESS: NULL CLOUD_PROVIDER: NULL *************************** 2. row *************************** HOST_ID: 3 OPTIMISTIC_LOCK_VERSION: 13 HOST_IDENTIFIER: 0a4853a0-7adc-4dae-a1da-3a12636f3574 NAME: node103.yinzhengjie.org.cn IP_ADDRESS: 172.30.1.103 RACK_ID: /default STATUS: NA CONFIG_CONTAINER_ID: 1 MAINTENANCE_COUNT: 0 DECOMMISSION_COUNT: 0 CLUSTER_ID: 1 NUM_CORES: 4 TOTAL_PHYS_MEM_BYTES: 3954196480 PUBLIC_NAME: NULL PUBLIC_IP_ADDRESS: NULL CLOUD_PROVIDER: NULL *************************** 3. row *************************** HOST_ID: 4 OPTIMISTIC_LOCK_VERSION: 13 HOST_IDENTIFIER: b613ff6e-6890-447a-a161-7f5324a14143 NAME: node102.yinzhengjie.org.cn IP_ADDRESS: 172.30.1.102 RACK_ID: /default STATUS: NA CONFIG_CONTAINER_ID: 1 MAINTENANCE_COUNT: 0 DECOMMISSION_COUNT: 0 CLUSTER_ID: 1 NUM_CORES: 4 TOTAL_PHYS_MEM_BYTES: 3954196480 PUBLIC_NAME: NULL PUBLIC_IP_ADDRESS: NULL CLOUD_PROVIDER: NULL *************************** 4. row *************************** HOST_ID: 5 OPTIMISTIC_LOCK_VERSION: 13 HOST_IDENTIFIER: f58247ff-4d3f-40d3-8f49-8f91f45d4407 NAME: node104.yinzhengjie.org.cn IP_ADDRESS: 172.30.1.104 RACK_ID: /default STATUS: NA CONFIG_CONTAINER_ID: 1 MAINTENANCE_COUNT: 0 DECOMMISSION_COUNT: 0 CLUSTER_ID: 1 NUM_CORES: 4 TOTAL_PHYS_MEM_BYTES: 3954196480 PUBLIC_NAME: NULL PUBLIC_IP_ADDRESS: NULL CLOUD_PROVIDER: NULL 4 rows in set (0.00 sec) mysql>
五.

















 5854
5854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









