



 本文对比了Zookeeper、memcached及Redis实现的分布式锁的特点及适用场景。Zookeeper锁安全性高,适用于对可靠性要求极高的场景;memcached锁并发效率好,适合高并发场景;Redis锁结合两者优势。
本文对比了Zookeeper、memcached及Redis实现的分布式锁的特点及适用场景。Zookeeper锁安全性高,适用于对可靠性要求极高的场景;memcached锁并发效率好,适合高并发场景;Redis锁结合两者优势。
在进行大型网站技术架构设计以及业务实现的过程中,多少都会遇到需要使用分布式锁的情况。那么问题也就接踵而至。分布式锁zk和memcached以及redis三者都能实现,同样是分布式锁,三者的区别何在?各自适用什么场景?
一、Zookeeper
实现原理:基于zookeeper瞬时有序节点实现的分布式锁,其主要逻辑如下(该图来自于IBM网站)。大致思想即为:每个客户端对某个功能加锁时,在zookeeper上的与该功能对应的指定节点的目录下,生成一个唯一的瞬时有序节点。判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
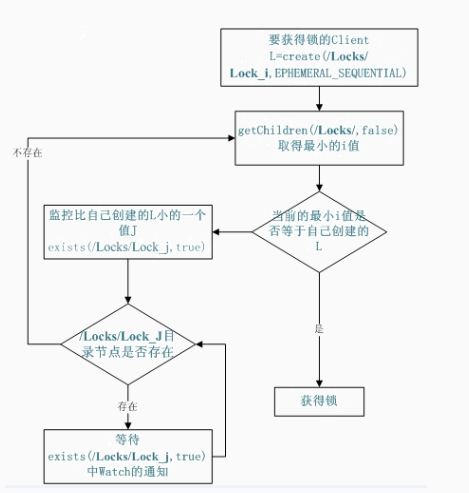
优点:锁安全性高,zk可持久化,且能实时监听获取锁的客户端状态。一旦客户端宕机,则瞬时节点随之消失,zk因而能第一时间释放锁。这也省去了用分布式缓存实现锁的过程中需要加入超时时间判断的这一逻辑;
缺点:性能开销比较高。因为其需要动态产生、销毁瞬时节点来实现锁功能。所以不太适合直接提供给高并发的场景使用
实现:可以直接采用zookeeper第三方库curator即可方便地实现分布式锁
适用场景:对可靠性要求非常高,且并发程度不高的场景下使用。如核心数据的定时全量/增量同步等
二、memcached分布式锁
实现原理:memcached带有add函数,利用add函数的特性即可实现分布式锁。add和set的区别在于:如果多线程并发set,则每个set都会成功,但最后存储的值以最后的set的线程为准。而add的话则相反,add会添加第一个到达的值,并返回true,后续的添加则都会返回false。利用该点即可很轻松地实现分布式锁
优点:并发高效
缺点:1、memcached采用列入LRU置换策略,所以如果内存不够,可能导致缓存中的锁信息丢失;
2、memcached无法持久化,一旦重启,将导致信息丢失。
使用场景:高并发场景。需要1)加上超时时间避免死锁;2)提供足够支撑锁服务的内存空间;3)稳定的集群化管理。
三、redis分布式锁
redis分布式锁即可以结合zk分布式锁锁高度安全和memcached并发场景下效率很好的优点,其实现方式和memcached类似,采用setnx即可实现。需要注意的是,这里的redis也需要设置超时时间。以避免死锁。可以利用jedis客户端实现


















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









