



 本文深入探讨Hadoop参数配置,包括JobTracker和TaskTracker的详细设置,以及如何通过调整参数优化MapReduce作业性能,特别关注小文件问题的解决策略。
本文深入探讨Hadoop参数配置,包括JobTracker和TaskTracker的详细设置,以及如何通过调整参数优化MapReduce作业性能,特别关注小文件问题的解决策略。

Jobtracker配置
更改此部分中的任何参数都需要重新启动JobTracker。
| mapred.job.tracker | maprfs:/// | JobTracker地址ip:port或使用uri maprfs:///表示默认集群或maprfs:/// mapr / san_jose_cluster1连接'san_jose_cluster1'集群。 将jobhost替换为jobtracker的一个或多个ip地址。 | ||
| mapred.jobtracker.port | 9001 | JobTracker侦听的端口。通过JobTracker读取以启动RPC Server。 | ||
| mapreduce.tasktracker.outofband.heartbeat | 真正 | 任务跟踪器在任务完成时发送带外心跳以改善延迟。将此值设置为false可禁用此行为。 | ||
| webinterface.private.actions | 假 | 默认情况下,无法从作业跟踪器的Web界面中删除作业。将此值设置为True可启用此行为。
| ||
| maprfs.openfid2.prefetch.bytes | 0 | 专家:reduce任务预取的shuffle字节数 | ||
| mapr.localoutput.dir | 产量 | 随机播放卷上的地图输出文件的路径。 | ||
| mapr.localspill.dir | 洒 | 随机播放卷上本地溢出文件的路径。 | ||
| mapreduce.jobtracker.node.labels.file | 指定要应用于集群中节点的标签的文件。 | |||
| mapreduce.jobtracker.node.labels.monitor.interval | 120000 | 指定以毫秒为单位的时间间隔。每次经过此间隔时,将轮询节点标签文件以进行更改。 | ||
| mapred.queue <队列名称> .label | 指定<queue-name>占位符中指定的队列的标签。 | |||
| mapred.queue <队列名称> .label.policy | 指定应用于<queue-name>占位符中指定的队列的标签的策略。策略控制队列标签和作业标签之间的交互:
|
Jobtracker目录
更改本节中的任何参数时,需要重新启动JobTracker。
卷路径= mapred.system.dir /../
| mapred.system.dir | 的/ var / MAPR /簇/ mapred / JobTracker的/系统 | MapReduce存储控制文件的共享目录。 |
| mapred.job.tracker.persist.jobstatus.dir | 的/ var / MAPR /簇/ mapred /的JobTracker / jobsInfo | 作业状态信息在文件系统中保留的目录,在文件系统丢弃内存队列之后以及在jobtracker重新启动之间可用。 |
| mapreduce.jobtracker.staging.root.dir | 的/ var / MAPR /簇/ mapred /的JobTracker /分期 | 用户作业文件的暂存区域的根实际上,这应该是用户主目录所在的目录(通常是/ user) |
| mapreduce.job.split.metainfo.maxsize | 千万 | 拆分元信息文件的最大允许大小。JobTracker不会尝试读取大于配置值的拆分元信息文件。如果设置为-1则无限制。 |
| mapreduce.maprfs.use.compression | 真正 | 将此属性的值设置为False可禁用MapReduce对随机数据使用MapR-FS压缩。 |
| mapred.jobtracker.retiredjobs.cache.size | 1000 | 要保留在缓存中的已退役作业状态数。 |
| mapred.job.tracker.history.completed.location | 在/ var / MAPR /组/ mapred / JobTracker的/历史/完成 | 已完成的作业历史记录文件存储在此单个众所周知的位置。如果未指定任何内容,则文件存储在本地文件系统中的$ {hadoop.job.history.location} / done中。 |
| hadoop.job.history.location | 如果作业跟踪器是静态的,则历史文件存储在本地文件系统上的这个众所周知的位置。如果此处未设置任何值,则默认情况下,它位于$ {hadoop.log.dir} / history的本地文件系统中。历史文件将移至mapred.jobtracker.history.completed.location,该文件位于MapRFs JobTracker卷上。 | |
| mapred.jobtracker.jobhistory.lru.cache.size | 五 | 内存中加载的作业历史记录文件数。首次访问作业时会加载作业。基于LRU清除缓存。 |
JobTracker恢复
更改本节中的任何参数时,需要重新启动JobTracker。
| mapreduce.jobtracker.recovery.dir | 的/ var / MAPR /簇/ mapred / JobTracker的/回收 | 恢复目录。存储已知TaskTrackers的列表。 |
| mapreduce.jobtracker.recovery.maxtime | 120 | JobTracker应保持恢复模式的最长时间(秒)。 |
| mapreduce.jobtracker.split.metainfo.maxsize | 千万 | 此属性的值设置拆分元信息文件的最大允许大小。JobTracker不会尝试读取大于此值的拆分元信息文件。 |
| mapred.jobtracker.restart.recover | 真正 | “true”在重启时启用(作业)恢复,“false”重新启动 |
| mapreduce.jobtracker.recovery.job.initialization.maxtime | 480 | 此属性的值指定JobTracker在开始恢复之前等待初始化作业的最长时间(以秒为单位)。此属性的默认值等于mapreduce.jobtracker.recovery.maxtime属性的值。 |
启用Fair Scheduler
更改本节中的任何参数时,需要重新启动JobTracker。
| mapred.fairscheduler.allocation.file | CONF / pools.xml | |
| mapred.jobtracker.taskScheduler | org.apache.hadoop.mapred.FairScheduler | 负责任务调度的类。 |
| mapred.fairscheduler.assignmultiple | 真正 | |
| mapred.fairscheduler.eventlog.enabled | 假 | 在$ {HADOOP_LOG_DIR} / fairscheduler /中启用调度程序日志记录 |
| mapred.fairscheduler.smalljob.schedule.enable | 真正 | 将此属性的值设置为False可禁用FairScheduler中小作业的快速计划。当群集负载较小时,TaskTrackers可以为小作业保留一个临时插槽。 |
| mapred.fairscheduler.smalljob.max.maps | 10 | 小工作定义。小工作允许的最大地图数量。 |
| mapred.fairscheduler.smalljob.max.reducers | 10 | 小工作定义。小工作中允许的最大减速器数量。 |
| mapred.fairscheduler.smalljob.max.inputsize | 10737418240 | 小工作定义。允许小作业的最大输入大小(以字节为单位)。默认值为10GB。 |
| mapred.fairscheduler.smalljob.max.reducer.inputsize | 1073741824 | 小工作定义。最小估计小型工作允许的减速器输入尺寸。默认值为每个reducer 1GB。 |
| mapred.cluster.ephemeral.tasks.memory.limit.mb | 200 | 小工作定义。为ephermal插槽保留的最大内存(以MB为单位)。默认值为200mb。JobTracker和TaskTracker节点上的此值必须相同。 |
TaskTracker配置
更改本节中的任何参数时,需要重新启动TaskTracker。
| 当mapreduce.tasktracker.prefetch.maptasks大于0时,您必须禁用具有抢占和基于标签的作业放置的Fair Scheduler。 |
| mapred.tasktracker.map.tasks.maximum | -1 | 要同时运行的最大映射任务槽数。默认值-1指定映射任务槽的数量基于Warden为MapReduce保留的内存总量。在可用于MapReduce的内存中(不包括为临时插槽保留的内存),40%被分配给映射任务。该总内存量除以mapred.maptask.memory.default参数的值,以确定此节点上的映射任务槽的总数。您还可以使用以下变量指定公式:
|
| mapreduce.tasktracker.prefetch.maptasks | 1.0 | 应该在tasktracker上预先安排多少个map任务。以%映射槽给出。默认值为1.0,表示过度调度的任务数量= TT上的总地图位置数。 |
| mapreduce.tasktracker.reserved.physicalmemory.mb.low | 0.8 | 当TaskTracker终止任务以减少总内存使用时,此属性的值设置目标内存使用级别。此属性的值表示mapreduce.tasktracker.reserved.physicalmemory.mb值中金额的百分比。 |
| mapreduce.tasktracker.task.slowlaunch | 假 | 将此属性的值设置为True,以便在每次任务启动后等待运行CLDB,JobTracker和ZooKeeper等关键服务的节点。 |
| mapreduce.tasktracker.volume.healthcheck.interval | 60000 | 此属性的值定义TaskTracker检查$ {mapr.localvolumes.path} / mapred / property中定义的Mapreduce卷的频率(以毫秒为单位)。 |
| mapreduce.use.maprfs | 真正 | 使用MapR-FS进行随机播放和排序/合并。 |
| mapred.userlog.retain.hours | 24 | 此属性的值指定在作业完成后保留用户日志的最长时间(以小时为单位)。 |
| mapred.user.jobconf.limit | 5242880 | 用户jobconf的最大允许大小。默认设置为5 MB。 |
| mapred.userlog.limit.kb | 0 | 不推荐使用:每个任务的最大用户日志大小(KB)。0禁用上限。 |
| mapreduce.use.fastreduce | 假 | 专家:合并地图输出而不复制。 |
| mapred.tasktracker.reduce.tasks.maximum | -1 | 同时运行的最大reduce任务槽数。默认值-1指定reduce任务槽的数量基于Warden为MapReduce保留的内存总量。在可用于MapReduce的内存中(不计算为临时插槽保留的内存),分配60%用于减少任务。该总内存量除以mapred.reducetask.memory.default参数的值,以确定此节点上reduce任务槽的总数。您还可以使用以下变量指定公式:
|
| mapred.tasktracker.ephemeral.tasks.maximum | 1 | 保留插槽,用于小型作业调度 |
| mapred.tasktracker.ephemeral.tasks.timeout | 10000 | 允许任务占用临时插槽的最长时间(以毫秒为单位) |
| mapred.tasktracker.ephemeral.tasks.ulimit | 4294967296 | 在临时插槽上安排的所有任务的Ulimit(字节) |
| mapreduce.tasktracker.reserved.physicalmemory.mb | 最大的phyiscal内存tasktracker应该为mapreduce任务保留。 如果任务使用超过限制,则使用最大内存的任务将被终止。 仅限专家:设置此值iff tasktracker应 为mapreduce任务使用一定量的内存。在MapR中,Distro warden根据 节点上配置的服务来计算此数字。 将mapreduce.tasktracker.reserved.physicalmemory.mb设置为-1将禁用 物理内存记帐和任务管理。 | |
| mapred.tasktracker.expiry.interval | 600000 | 专家:此属性的值指定以毫秒为单位的时间间隔。在此间隔到期后没有发送任何心跳,TaskTracker被标记为丢失。 |
| mapreduce.tasktracker.heapbased.memory.management | 假 | 仅限专家:如果管理员希望通过不启动太多任务来阻止交换,请 使用此选项。任务的内存使用量基于最大Java堆大小(-Xmx)。 默认情况下,-xmx将由tasktracker根据为mapreduce任务保留的插槽和内存计算。 请参阅mapred.map.child.java.opts / mapred.reduce.child.java.opts。 |
| mapreduce.tasktracker.jvm.idle.time | 10000 | 如果jvm空闲超过mapreduce.tasktracker.jvm.idle.time(毫秒), tasktracker将终止它。 |
| mapred.max.tracker.failures | 4 | 给定作业的任务跟踪器上的任务失败次数,之后不会为该作业分配新任务。 |
| mapred.max.tracker.blacklists | 4 | 各种作业的taskTracker黑名单的数量,之后任务跟踪器可以在所有作业中列入黑名单。跟踪器将在稍后(一天之后)完成任务。重启后,跟踪器将成为健康的追踪器。 |
| mapred.task.tracker.http.address | 0.0.0.0:50060 | 此属性的值指定TaskTracker的HTTP服务器地址和端口。指定0作为使服务器在空闲端口上启动的端口。 |
| mapred.task.tracker.report.address | 127.0.0.1:0 | TaskTrackeer服务器侦听的IP地址和端口。由于它仅由任务连接,因此它使用本地接口。专家。仅在主机没有环回接口时才更改此值。 |
| mapreduce.tasktracker.group | MAPR | 专家:TaskTracker所属的组。如果通过mapreduce.tasktracker.taskcontroller值配置LinuxTaskController ,则任务控制器二进制文件$ HADOOP_HOME / bin / platform / bin / task-controller的组所有者必须与此组相同。 |
| mapred.tasktracker.task-controller.config.overwrite | 真正 | 该LinuxTaskController需要设定一个配置文件$ HADOOP_HOME/conf/taskcontroller.cfg。配置文件采用以下参数:
|
| mapred.tasktracker.indexcache.mb | 10 | 此属性的值指定TaskTracker为索引缓存分配的最大内存量。当TaskTracker将地图输出提供给reducer时,将使用索引缓存。 |
| mapred.tasktracker.instrumentation | org.apache.hadoop.mapred.TaskTrackerMetricsInst | 专家:与每个TaskTracker关联的检测类。 |
| mapred.task.tracker.task控制器 | org.apache.hadoop.mapred.LinuxTaskController | 此属性的值指定启动和管理任务执行的TaskController。 |
| mapred.tasktracker.taskmemorymanager.killtask.maxRSS | 假 | 将此属性的值设置为True可以在MapReduce任务总数超过TaskTracker的mapreduce.tasktracker.reserved.physicalmemory.mb属性中指定的限制时终止使用最大内存的任务。任务在最近发布的订单中被杀死。 |
| mapred.tasktracker.taskmemorymanager.monitoring间隔 | 3000 | 此属性的值指定TaskTracker在监视任务的内存使用情况之间等待的间隔(以毫秒为单位)。仅当通过将属性mapred.tasktracker.tasks.maxmemory设置为True 来启用任务内存管理时,才使用此属性。 |
| mapred.tasktracker.tasks.sleeptime-前,SIGKILL | 5000 | 此属性的值设置TaskTracker在发送SIGTERM之后将SIGKILL发送到进程之前等待的时间(以毫秒为单位)。 |
| mapred.temp.dir | $ {} hadoop.tmp.dir / mapred / TEMP | 临时文件的共享目录。 |
| mapreduce.cluster.map.userlog.retain大小 | -1 | 此属性的值指定要从映射任务日志中保留的字节数。默认值-1禁用此功能。 |
| mapreduce.cluster.reduce.userlog.retain大小 | -1 | 此属性的值指定要从reduce任务日志中保留的字节数。默认值-1禁用此功能。 |
| mapreduce.heartbeat.10000 | 100000 | 此属性的值指定1001到10000个节点的中型群集的心跳时间(以毫秒为单位)。在10s - 100s之间线性缩放。 |
| mapreduce.heartbeat.1000 | 10000 | 此属性的值指定101到1000个节点的中型群集的心跳时间(以毫秒为单位)。在1s - 10s之间线性缩放。 |
| mapreduce.heartbeat.100 | 1000 | 此属性的值指定11到100个节点的中型群集的心跳时间(以毫秒为单位)。在300ms - 1s之间线性缩放。 |
| mapreduce.heartbeat.10 | 300 | 此属性的值指定1到10个节点的中型群集的心跳时间(以毫秒为单位)。 |
| mapreduce.job.complete.cancel.delegation.tokens | 真正 | 将此属性的值设置为False可防止取消注册或取消委派令牌更新。 |
| mapreduce.jobtracker.inline.setup.cleanup | 假 | 将此属性的值设置为True可使JobTracker尝试自行设置和清理作业,或者在setup / cleanup任务中执行此操作。 |
工作配置
在提交作业之前,用户应在计划提交作业的节点上设置这些值。如果您使用的是Hadoop示例,则可以从命令行设置这些参数。例:
hadoop jar hadoop-examples.jar terasort -Dmapred.map.child.java.opts = “ - Xmx1000m”
提交作业时,JobClient 通过按以下顺序从以下文件中读取参数来创建job.xml:
- mapred-default.xml中
- 本地mapred-site.xml - 覆盖mapred-default.xml中的相同参数
- 作业代码本身的任何设置 - 覆盖mapred-site.xml中的相同参数
| keep.failed.task.files | 假 | 是否应保留失败任务的文件。这应仅用于失败的作业,因为存储永远不会被回收。它还可以防止映射输出在使用时从reduce目录中删除。 |
| mapred.job.reuse.jvm.num.tasks | -1 | 每个jvm运行多少个任务。如果设置为-1,则没有限制。 |
| mapred.map.tasks.speculative.execution | 真正 | 如果为true,则可以并行执行一些映射任务的多个实例。 |
| mapred.reduce.tasks.speculative.execution | 真正 | 如果为true,则可以并行执行某些reduce任务的多个实例。 |
| mapred.reduce.tasks | 1 | 每个作业的默认减少任务数。通常设置为群集减少容量的99%,因此如果节点发生故障,则仍可以在单个波浪中执行减少。当mapred.job.tracker属性的值为local时忽略。 |
| mapred.job.map.memory.physical.mb | 此作业的映射任务的最大物理内存限制。如果超出限制,任务尝试将失败。 | |
| mapred.job.reduce.memory.physical.mb | 减少此作业任务的最大物理内存限制。如果超出限制,任务尝试将失败。 | |
| mapreduce.task.classpath.user.precedence | 假 | 如果用户想要设置不同的类路径,则设置为true。 |
| mapred.max.maps.per.node | -1 | 运行作业的地图任务的每节点限制。值-1表示没有限制。 |
| mapred.max.reduces.per.node | -1 | 每个节点限制运行减少作业的任务。值-1表示没有限制。 |
| mapred.running.map.limit | -1 | 对作业运行映射任务的群集范围限制。值-1表示没有限制。 |
| mapred.running.reduce.limit | -1 | 群集范围限制运行减少作业的任务。值-1表示没有限制。 |
| mapreduce.tasktracker.cache.local.numberdirectories | 10000 | 此属性的值设置在给定分布式缓存存储中创建的最大子目录数。无论是否超过总大小阈值,都将清除超出此限制的缓存项。 |
| mapred.reduce.child.java.opts | -XX:错误文件= /选择/核/ mapreduce_java_error%p.log | Java选择reduce任务。MapR默认堆大小(-Xmx)由tasktracker中为mapreduce保留的内存决定。减少任务的内存比map任务多。reduce任务的默认内存=(为mapreduce保留的总内存)*(2 * #retillots /(#mapslots + 2 * #relowlots)) |
| mapred.reduce.child.ulimit | ||
| io.sort.factor | 256 | 在文件排序期间同时合并的流的数量。此属性的值确定打开文件句柄的数量。 |
| io.sort.mb | 380 | 此值设置在写入最终映射输出之前保存映射输出的内存缓冲区的大小(以兆字节为单位)。此属性的较低值会增加溢出的可能性。建议的做法是将此值设置为地图输出平均大小的1.5倍。 |
| io.sort.record.percent | 0.17 | |
| io.sort.record.percent | 0.17 | 由io.sort.mb属性指定的内存缓冲区的百分比,专用于跟踪记录边界。收集线程在阻塞之前可以收集的最大记录数是io.sort.mb和io.sort.percent的乘积值的四分之一。 |
| io.sort.spill.percent | 0.99 | 此属性的值设置缓冲区或记录收集缓冲区的软限制。达到软限制的线程开始在后台将内容溢出到磁盘。请注意,这并不意味着任何数据块到溢出。不要将此值降低到0.5以下。 |
| mapred.reduce.slowstart.completed.maps | 0.95 | 作业中应该在减少之前完成的作业中的地图数量的分数被安排。 |
| mapreduce.reduce.input.limit | -1 | 减少输入大小的限制。如果 reduce 的估计输入大小大于此值,则作业失败。一个 值-1意味着没有限制设置。 |
| mapred.reduce.parallel.copies | 12 | 在复制(随机播放)阶段,默认的并行传输数由reduce运行。 |
| jobclient.completion.poll.interval | 5000 | 此属性的值指定JobClient的轮询频率(以毫秒为单位)到JobTracker以获取有关作业状态的更新。减少此值可在单节点系统上进行更快速的测试。在生产群集上调整此值可能会导致意外的客户端 - 服务器流量。 |
| jobclient.output.filter | 失败 | 此属性的值指定控制发送到JobClient控制台的任务的用户日志输出的过滤器。法律价值观是:
|
| jobclient.progress.monitor.poll.interval | 1000 | 此属性的值指定JobClient的状态报告频率(以毫秒为单位)到控制台并检查作业完成情况。 |
| job.end.notification.url | HTTP://本地主机:8080 / jobstatus.php =的jobId $&的jobId = jobStatus $ jobStatus | 此属性的值指定在作业完成时调用的URL,以报告作业的结束状态。URL中只有两个变量是合法的,$ jobId和$ jobStatus。如果存在,这些变量将由它们各自的值替换。 |
| job.end.retry.attempts | 0 | 此属性的值指定Hadoop尝试联系通知URL的最大次数。 |
| job.end.retry.interval | 30000 | 此属性的值指定尝试联系通知URL之间的间隔(以毫秒为单位)。 |
| keep.failed.task.files | 假 | 将此属性的值设置为True可保留失败任务的文件。由于系统不会自动回收此存储,因此仅为失败的作业保留文件。将此属性的值设置为True还会在reduce目录中保留映射输出,因为将消耗映射输出,而不是在使用时删除映射输出。 |
| local.cache.size | 10737418240 | 此属性的值指定分配给每个本地TaskTracker目录以存储分布式缓存数据的字节数。 |
| mapr.centrallog.dir | 日志 | 此属性的值指定指向中央日志位置的本地卷路径下的相对路径$ {mapr.localvolumes.path} / <hostname> /${mapr.centrallog.dir }。 |
| mapr.localvolumes.path | 在/ var / MAPR /本地 | 本地卷的路径。 |
| map.sort.class | org.apache.hadoop.util.QuickSort | 排序键的默认排序类。 |
| tasktracker.http.threads | 2 | HTTP服务器的工作线程数。 |
| topology.node.switch.mapping.impl | org.apache.hadoop.net.ScriptBasedMapping | DNSToSwitchMapping的默认实现。它调用topology.script.file.name属性中指定的脚本来解析节点名称。如果没有为topology.script.file.name属性设置值,则会为所有节点名返回默认值DEFAULT_RACK。 |
| topology.script.number.args | 100 | 使用topology.script.file.name配置的脚本运行的最大参数数。每个参数都是一个IP地址。 |
| mapr.task.diagnostics.enabled | 假 | 将此属性的值设置为True以在杀死无响应的任务尝试之前运行MapR诊断脚本。 |
| mapred.acls.enabled | 假 | 此属性的值指定是否在各种队列和作业级别操作期间检查ACL以进行用户授权。将此属性的值设置为True可在用户使用Map / Reduce API,RPC,控制台或Web用户界面请求队列和作业操作时启用JobTracker和TaskTracker进行的访问控制检查。 |
| mapred.child.oom_adj | 10 | 此属性的值指定对特定于Linux的内存不足杀手的内存不足值的调整。合法值为0-15。 |
| mapred.child.renice | 10 | 此属性的值指定0到19之间的整数,供Linux nice}}实用程序使用。 |
| mapred.child.taskset | 真正 | 将此属性的值设置为False以防止在任务集中运行作业。有关更多信息,请参阅任务集(1)的手册页。 |
| mapred.child.tmp | ./tmp | 此属性的值设置map和reduce任务的临时目录的位置。将此值设置为绝对路径以直接分配目录。相对路径位于任务的工作目录下。Java任务使用选项-Djava.io.tmpdir = tmp目录的绝对路径执行。使用环境变量TMPDIR = tmp目录的绝对路径设置管道和流。 |
| mapred.cluster.ephemeral.tasks.memory.limit.mb | 200 | 此属性的值指定小作业的最大大小(以兆字节为单位)。该值在内存中保留用于临时插槽。JobTracker和TaskTracker节点必须将此属性设置为相同的值。 |
| mapred.cluster.map.memory.mb | -1 | 此属性的值设置调度程序使用的Map-Reduce框架中单个映射槽的虚拟内存大小。如果调度支持此功能,作业还可以通过向多个插槽,一个地图的任务mapred.job.map.memory.mb,由值指定的限制mapred.cluster.max.map.memory.mb。默认值-1禁用该功能。将此值设置为有用的内存大小以启用该功能。 |
| mapred.cluster.max.map.memory.mb | -1 | 此属性的值设置由调度程序使用的Map-Reduce框架启动的单个映射任务的虚拟内存大小。如果调度支持此功能,作业还可以通过向多个插槽,一个地图的任务mapred.job.map.memory.mb,由值指定的限制mapred.cluster.max.map.memory.mb。默认值-1禁用该功能。将此值设置为有用的内存大小以启用该功能。 |
| mapred.cluster.max.reduce.memory.mb | -1 | 此属性的值设置由调度程序使用的Map-Reduce框架启动的单个reduce任务的虚拟内存大小。如果调度支持此功能,作业还可以通过向多个插槽,一个地图的任务mapred.job.reduce.memory.mb,由值指定的限制mapred.cluster.max.reduce.memory.mb。默认值-1禁用该功能。将此值设置为有用的内存大小以启用该功能。 |
| mapred.cluster.reduce.memory.mb | -1 | 此属性的值设置调度程序使用的Map-Reduce框架中单个reduce插槽的虚拟内存大小。如果调度支持此功能,作业还可以通过向多个插槽,一个地图的任务mapred.job.reduce.memory.mb,由值指定的限制mapred.cluster.max.reduce.memory.mb。默认值-1禁用该功能。将此值设置为有用的内存大小以启用该功能。 |
| mapred.compress.map.output | 假 | 将此属性的值设置为True可以在通过网络发送输出之前使用SequenceFile压缩来压缩映射输出。 |
| mapred.fairscheduler.assignmultiple | 真正 | 将此属性的值设置为False可防止FairScheduler分配多个任务。 |
| mapred.fairscheduler.eventlog.enabled | 假 | 将此属性的值设置为True以启用{{ $ {HADOOP_LOG_DIR} / fairscheduler /中的调度程序日志记录 |
| mapred.fairscheduler.smalljob.max.inputsize | 10737418240 | 此属性的值指定定义小作业的最大大小(以字节为单位)。 |
| mapred.fairscheduler.smalljob.max.maps | 10 | 此属性的值指定小作业中允许的最大映射数。 |
| mapred.fairscheduler.smalljob.max.reducer.inputsize | 1073741824 | 此属性的值指定小作业中减速器的最大估计输入大小(以字节为单位)。 |
| mapred.fairscheduler.smalljob.max.reducers | 10 | 此属性的值指定小作业中允许的最大缩减器数。 |
| mapred.healthChecker.interval | 60000 | 此属性的值设置节点运行状况脚本运行的频率(以毫秒为单位)。 |
| mapred.healthChecker.script.timeout | 600000 | 此属性的值设置频率(以毫秒为单位),在该频率之后,节点脚本因无响应而被终止并报告为失败。 |
| mapred.inmem.merge.threshold | 1000 | 当等于此属性值的多个文件累积时,内存中合并将触发并溢出到磁盘。将此属性的值设置为零或更小,以强制合并和溢出仅触发RAMFS内存消耗。 |
| mapred.job.map.memory.mb | -1 | 此属性的值设置作业的单个映射任务的虚拟内存大小。如果调度支持此功能,作业还可以通过向多个插槽,一个地图的任务mapred.cluster.map.memory.mb,由值指定的限制mapred.cluster.max.map.memory.mb。如果mapred.cluster.map.memory.mgb属性的值也为-1,则默认值-1将禁用该功能。将此值设置为有用的内存大小以启用该功能。 |
| mapred.job.queue.name | 默认 | 此属性的值指定作业提交到的队列。此属性的值必须与系统的mapred.queue.names中定义的队列名称匹配。队列的ACL设置必须允许当前用户将作业提交到队列。 |
| mapred.job.reduce.input.buffer.percent | 0 | 此属性的值指定相对于最大堆大小的内存百分比。在shuffle之后,在reduce开始之前,内存中剩余的map输出必须占用比该阈值更少的内存。 |
| mapred.job.reduce.memory.mb | -1 | 此属性的值设置作业的单个reduce任务的虚拟内存大小。如果调度支持此功能,作业还可以通过向多个插槽,一个地图的任务mapred.cluster.reduce.memory.mb,由值指定的限制mapred.cluster.max.reduce.memory.mb。如果mapred.cluster.map.memory.mgb属性的值也为-1,则默认值-1将禁用该功能。将此值设置为有用的内存大小以启用该功能。 |
| mapred.job.reuse.jvm.num.tasks | -1 | 此属性的值设置在每个JVM上运行的任务数。默认值-1设置无限制。 |
| mapred.job.shuffle.input.buffer.percent | 0.7 | 此属性的值设置在shuffle期间从最大堆大小分配的内存百分比到存储映射输出。 |
| mapred.job.shuffle.merge.percent | 0.66 | 此属性的值设置分配给mapred.job.shuffle.input.buffer.percent中存储地图输出的总内存的百分比。当映射输出的内存存储达到此百分比时,将触发内存中合并。 |
| mapred.job.tracker.handler.count | 10 | 此属性的值设置JobTracker的服务器线程数。作为最佳实践,将此值设置为TaskTracker节点数量的大约4%。 |
| mapred.job.tracker.history.completed.location | 在/ var / MAPR /组/ mapred / JobTracker的/历史/完成 | 此属性的值设置存储已完成的作业历史记录文件的位置。如果此属性未指定值,则已完成的作业文件将存储在本地文件系统中的$ {hadoop.job.history.location} / done中。 |
| mapred.job.tracker.http.address | 0.0.0.0:50030 | 此属性的值指定JobTracker的HTTP服务器地址和端口。指定0作为使服务器在空闲端口上启动的端口。 |
| mapred.jobtracker.instrumentation | org.apache.hadoop.mapred.JobTrackerMetricsInst | 专家:与每个JobTracker关联的检测类。 |
| mapred.jobtracker.job.history.block.size | 3145728 | 此属性的值设置作业历史记录文件的块大小。将作业历史记录转储到磁盘非常重要,因为作业恢复使用作业历史记录。 |
| mapred.jobtracker.jobhistory.lru.cache.size | 五 | 此属性的值指定要在内存中加载的作业历史记录文件的数量。首次访问作业时会加载作业。基于LRU清除缓存。 |
| mapred.job.tracker | maprfs:/// | JobTracker地址ip:port或使用uri maprfs:///表示默认集群或maprfs:/// mapr / san_jose_cluster1连接'san_jose_cluster1'集群。“”local“”表示独立模式。 |
| mapred.jobtracker.maxtasks.per.job | -1 | 将此属性的值设置为任何正整数,以设置单个作业的最大任务数。默认值-1表示没有最大值。 |
| mapred.job.tracker.persist.jobstatus.active | 假 | 将此属性的值设置为True可启用作业状态信息的持久性。 |
| mapred.job.tracker.persist.jobstatus.dir | 的/ var / MAPR /簇/ mapred /的JobTracker / jobsInfo | 此属性的值指定在JobTracker重新启动之间退出内存队列后作业状态信息仍然存在的目录。 |
| mapred.job.tracker.persist.jobstatus.hours | 0 | 此属性的值指定作业状态信息持续时间(以小时为单位)。信息从内存队列中删除后以及JobTracker重新启动之间可以获得持久作业状态信息。默认值零将禁用作业状态信息持久性。 |
| mapred.jobtracker.port | 9001 | JobTracker监听的IPC端口。 |
| mapred.jobtracker.restart.recover | 真正 | 将此属性的值设置为False以在重新启动时禁用作业恢复。 |
| mapred.jobtracker.retiredjobs.cache.size | 1000 | 此属性的值指定缓存中保留的已停用作业状态的数量。 |
| mapred.jobtracker.retirejob.check | 30000 | 此属性的值指定退役作业线程用于检查已完成作业的频率间隔。 |
| mapred.line.input.format.linespermap | 1 | NLineInputFormat中每个拆分的行数。 |
| mapred.local.dir.minspacekill | 0 | 此属性的值指定mapred.local.dir属性指定的目录中的可用空间阈值。当可用空间低于此阈值时,在所有当前任务完成并清理之前,不再请求任务。当可用空间低于此阈值时,将按以下顺序终止正在运行的任务,直到可用空间高于阈值:
|
| mapred.local.dir.minspacestart | 0 | 此属性的值指定mapred.local.dir指定的目录的可用空间阈值。当可用空间低于此阈值时,不会请求任务。 |
| mapred.local.dir | 的/ tmp / MAPR-的hadoop / mapred /本地 | 此属性的值指定MapReduce本地化作业文件的目录。本地化作业文件是TaskTracker下载的与作业相关的文件,包括作业配置,作业JAR文件和添加到DistributedCache的文件。每个任务尝试都有一个mapred.local.dir目录下的专用子目录。共享文件以符号方式链接到这些子目录。 |
| mapred.map.child.java.opts | -XX:错误文件= /选择/核/ mapreduce_java_error%p.log | 此属性存储映射任务的Java选项。如果存在,@ taskid @符号将替换为当前的TaskID。例如,要将详细垃圾回收日志记录到/ tmp中为taskid命名的文件并将堆最大值设置为1GB,请将此属性设置为值-Xmx1024m -verbose:gc -Xloggc:/ tmp / @ taskid @ .gc。映射 的配置变量。{map / reduce} .child.ulimit控制子进程的最大虚拟内存。 在Hadoop的MapR发行版中,默认为-Xmx由TaskTracker为mapreduce保留的内存决定。减少任务使用内存而不是map任务。映射任务的默认内存遵循公式(为mapreduce保留的总内存)*(#mapslots /(#mapslots + 1.3 * #reducelots))。 |
| mapred.map.child.log.level | 信息 | 此属性的值设置映射任务的日志记录级别。允许的级别是:
|
| 了mapred.map.max.attempts | 4 | 专家:此属性的值设置每个地图任务的最大尝试次数。 |
| mapred.map.output.compression.codec | org.apache.hadoop.io.compress.DefaultCodec | 如果启用了地图输出压缩,则指定用于压缩地图输出的压缩编解码。 |
| mapred.maptask.memory.default | 800 | 当mapred.tasktracker.map.tasks.maximum参数的值为-1时,此参数指定以MB为单位的大小,该大小用于确定此节点上的映射任务槽的默认总数。 |
| mapred.map.tasks | 2 | 每个作业的默认地图任务数。当mapred.job.tracker属性的值为local时忽略。 |
| mapred.maxthreads.generate.mapoutput | 1 | 专家:用于排序和写入映射输出分区的映射内任务线程数。 |
| mapred.maxthreads.partition.closer | 1 | 专家:异步关闭或刷新映射输出分区的线程数。 |
| mapred.merge.recordsBeforeProgress | 10000 | 在向TaskTracker发送进度通知之前合并期间要处理的记录数。 |
| mapred.min.split.size | 0 | 应将映射输入的最小大小块拆分为。具有最小分割大小的文件格式优先于此设置。 |
| mapred.output.compress | 假 | 将此属性的值设置为True可压缩作业输出。 |
| mapred.output.compression.codec | org.apache.hadoop.io.compress.DefaultCodec | 启用作业输出压缩时,此属性的值指定压缩编解码。 |
| mapred.output.compression.type | 记录 | 将作业输出压缩为SequenceFiles时,此值的属性指定如何压缩作业输出。法律价值观是:
|
| mapred.queue.default.state | RUNNING | 此属性的值定义默认队列的状态,可以是STOPPED或RUNNING。可以在运行时更改此值。 |
| mapred.queue.names | 默认 | 此属性的值指定为此JobTracker配置的队列的逗号分隔列表。作业被添加到队列中,调度程序可以为各种队列配置不同的调度属性。要为队列配置属性,队列的名称必须与此值中指定的名称匹配。此处使用命名约定mapred.queue配置所有调度程序通用的队列属性。$ QUEUE-NAME。$ PROPERTY-NAME。 此参数中配置的队列数可能取决于正在使用的调度程序的类型,如mapred.jobtracker.taskScheduler中所指定。例如,JobQueueTaskScheduler仅支持单个队列,这是此处配置的默认队列。在添加队列之前验证调度是否支持多个队列。 |
| mapred.reduce.child.log.level | 信息 | reduce任务的日志记录级别。允许的级别是:
|
| mapred.reduce.copy.backoff | 300 | 此属性的值指定reducer在声明提取失败之前获取一个映射输出所花费的最长时间(以秒为单位)。 |
| mapred.reduce.max.attempts | 4 | 专家:每次减少任务的最大尝试次数。 |
| mapred.reducetask.memory.default | 1500 | 当mapred.tasktracker.reduce.tasks.maximum参数的值为-1时,此参数指定以MB为单位的大小,该大小用于确定此节点上的reduce任务槽的默认总数。 |
| mapred.skip.attempts.to.start.skipping | 2 | 此属性的值指定了许多任务尝试次数。在许多任务尝试之后,跳过模式处于活动状态。当跳过模式处于活动状态时,任务将报告它将在TaskTracker旁边处理的记录范围。在这个记录范围内,TaskTracker知道哪些记录是可疑的,并且在进一步执行时会跳过可疑记录。 |
| mapred.skip.map.auto.incr.proc.count | 真正 | MapRunner调用map函数后,SkipBadRecords.COUNTER_MAP_PROCESSED_RECORDS递增。对于异步处理记录的应用程序或缓冲区输入记录,请将此属性的值设置为False。此类应用程序必须直接递增此计数器 |
| mapred.skip.map.max.skip.records | 0 | 不良记录周围可接受的跳过记录数,每个映射器中的坏记录。该号码包括不良记录。默认值0禁用检测和跳过错误记录。框架尝试通过重试来缩小跳过的范围,直到满足此阈值或者此任务的所有尝试都用完为止。将值设置为Long.MAX_VALUE以防止框架缩小跳过的范围。 |
| mapred.skip.reduce.auto.incr.proc.count | 真正 | MapRunner调用reduce函数后,SkipBadRecords.COUNTER_MAP_PROCESSED_RECORDS递增。对于异步处理记录的应用程序或缓冲区输入记录,请将此属性的值设置为False。此类应用程序必须直接递增此计数器 |
| mapred.skip.reduce.max.skip.groups | 0 | 坏记录周围的可接受跳过记录数,每个坏记录中的坏记录。该号码包括不良记录。默认值0禁用检测和跳过错误记录。框架尝试通过重试来缩小跳过的范围,直到满足此阈值或者此任务的所有尝试都用完为止。将值设置为Long.MAX_VALUE以防止框架缩小跳过的范围。 |
| mapred.submit.replication | 10 | 此属性的值指定已提交作业文件的复制级别。作为最佳实践,请将此值设置为大约节点数的平方根。 |
| mapred.task.cache.levels | 2 | 此属性的值指定任务缓存的最大级别。例如,如果级别为2,则缓存的任务位于主机级别和机架级别。 |
| mapred.task.calculate.resource.usage | 真正 | 将此属性的值设置为False以防止使用$ {mapreduce.tasktracker.resourcecalculatorplugin}参数。 |
| mapred.task.profile | 假 | 将此属性的值设置为True可以启用任务分析以及系统收集分析器信息。 |
| mapred.task.profile.maps | 0-2 | 此属性的值将映射任务的范围设置为配置文件。当mapred.task.profile属性的值设置为False 时,将忽略此属性。 |
| mapred.task.profile.reduces | 0-2 | 此属性的值将reduce任务的范围设置为profile。当mapred.task.profile属性的值设置为False 时,将忽略此属性。 |
| mapred.task.timeout | 600000 | 此属性的值指定任务在任务未执行以下任何操作时终止的时间(以毫秒为单位):
|
| mapred.tasktracker.dns.interface | 默认 | 此属性的值指定TaskTracker从其报告其IP地址的网络接口的名称。 |
| mapred.tasktracker.dns.nameserver | 默认 | 此属性的值指定TaskTracker用于确定JobTracker主机名的名称服务器(DNS)的主机名或IP地址。 |
Oozie的
| hadoop.proxyuser.root.hosts | * | 指定超级用户必须连接的主机才能充当另一个用户。将主机指定为以逗号分隔的IP地址列表或运行Oozie服务器的主机名。 |
| hadoop.proxyuser.mapr.groups | MAPR,工作人员 | |
| hadoop.proxyuser.root.groups | 根 | 超级用户可以充当列出的组的任何成员。 |
输入分片(Input Split):在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组。
Hadoop 2.x默认的block大小是128MB,Hadoop 1.x默认的block大小是64MB,可以在hdfs-site.xml中设置dfs.block.size,注意单位是byte。
分片大小范围可以在mapred-site.xml中设置,mapred.min.split.size mapred.max.split.size,minSplitSize大小默认为1B,maxSplitSize大小默认为Long.MAX_VALUE = 9223372036854775807
那么分片到底是多大呢?
minSize=max{minSplitSize,mapred.min.split.size}
maxSize=mapred.max.split.size
splitSize=max{minSize,min{maxSize,blockSize}}
我们再来看一下源码
所以在我们没有设置分片的范围的时候,分片大小是由block块大小决定的,和它的大小一样。比如把一个258MB的文件上传到HDFS上,假设block块大小是128MB,那么它就会被分成三个block块,与之对应产生三个split,所以最终会产生三个map task。我又发现了另一个问题,第三个block块里存的文件大小只有2MB,而它的block块大小是128MB,那它实际占用Linux file system的多大空间?
答案是实际的文件大小,而非一个块的大小。
有大神已经验证这个答案了:http://blog.youkuaiyun.com/samhacker/article/details/23089157
1、往hdfs里面添加新文件前,hadoop在linux上面所占的空间为 464 MB:
2、往hdfs里面添加大小为2673375 byte(大概2.5 MB)的文件:
2673375 derby.jar
3、此时,hadoop在linux上面所占的空间为 467 MB——增加了一个实际文件大小(2.5 MB)的空间,而非一个block size(128 MB):
4、使用hadoop dfs -stat查看文件信息:
这里就很清楚地反映出: 文件的实际大小(file size)是2673375 byte, 但它的block size是128 MB。
5、通过NameNode的web console来查看文件信息:
结果是一样的: 文件的实际大小(file size)是2673375 byte, 但它的block size是128 MB。
6、不过使用‘hadoop fsck’查看文件信息,看出了一些不一样的内容—— ‘1(avg.block size 2673375 B)’:
值得注意的是,结果中有一个 ‘1(avg.block size 2673375 B)’的字样。这里的 'block size' 并不是指平常说的文件块大小(Block Size)—— 后者是一个元数据的概念,相反它反映的是文件的实际大小(file size)。以下是Hadoop Community的专家给我的回复:
“The fsck is showing you an "average blocksize", not the block size metadata attribute of the file like stat shows. In this specific case, the average is just the length of your file, which is lesser than one whole block.”
最后一个问题是: 如果hdfs占用Linux file system的磁盘空间按实际文件大小算,那么这个”块大小“有必要存在吗?
其实块大小还是必要的,一个显而易见的作用就是当文件通过append操作不断增长的过程中,可以通过来block size决定何时split文件。以下是Hadoop Community的专家给我的回复:
“The block size is a meta attribute. If you append tothe file later, it still needs to know when to split further - so it keeps that value as a mere metadata it can use to advise itself on write boundaries.”
补充:我还查到这样一段话
原文地址:http://blog.youkuaiyun.com/lylcore/article/details/9136555
一个split的大小是由goalSize, minSize, blockSize这三个值决定的。computeSplitSize的逻辑是,先从goalSize和blockSize两个值中选出最小的那个(比如一般不设置map数,这时blockSize为当前文件的块size,而goalSize是文件大小除以用户设置的map数得到的,如果没设置的话,默认是1)。
hadooop提供了一个设置map个数的参数mapred.map.tasks,我们可以通过这个参数来控制map的个数。但是通过这种方式设置map的个数,并不是每次都有效的。原因是mapred.map.tasks只是一个hadoop的参考数值,最终map的个数,还取决于其他的因素。
为了方便介绍,先来看几个名词:
block_size : hdfs的文件块大小,默认为64M,可以通过参数dfs.block.size设置
total_size : 输入文件整体的大小
input_file_num : 输入文件的个数
(1)默认map个数
如果不进行任何设置,默认的map个数是和blcok_size相关的。
default_num = total_size / block_size;
(2)期望大小
可以通过参数mapred.map.tasks来设置程序员期望的map个数,但是这个个数只有在大于default_num的时候,才会生效。
goal_num = mapred.map.tasks;
(3)设置处理的文件大小
可以通过mapred.min.split.size 设置每个task处理的文件大小,但是这个大小只有在大于block_size的时候才会生效。
split_size = max(mapred.min.split.size, block_size);
split_num = total_size / split_size;
(4)计算的map个数
compute_map_num = min(split_num, max(default_num, goal_num))
除了这些配置以外,mapreduce还要遵循一些原则。 mapreduce的每一个map处理的数据是不能跨越文件的,也就是说min_map_num >= input_file_num。 所以,最终的map个数应该为:
final_map_num = max(compute_map_num, input_file_num)
经过以上的分析,在设置map个数的时候,可以简单的总结为以下几点:
(1)如果想增加map个数,则设置mapred.map.tasks 为一个较大的值。
(2)如果想减小map个数,则设置mapred.min.split.size 为一个较大的值。
(3)如果输入中有很多小文件,依然想减少map个数,则需要将小文件merger为大文件,然后使用准则2。
---------------------
dfs.block.size
决定HDFS文件block数量的多少(文件个数),它会间接的影响Job Tracker的调度和内存的占用(更影响内存的使用),
两个推测式执行
mapred.map.tasks.speculative.execution=true
mapred.reduce.tasks.speculative.execution=true
1
2
这是两个推测式执行的配置项,默认是true
所谓的推测执行,就是当所有task都开始运行之后,Job Tracker会统计所有任务的平均进度,如果某个task所在的task node机器配置比较低或者CPU load很高(原因很多),导致任务执行比总体任务的平均执行要慢,此时Job Tracker会启动一个新的任务(duplicate task),原有任务和新任务哪个先执行完就把另外一个kill掉,这也是我们经常在Job Tracker页面看到任务执行成功,但是总有些任务被kill,就是这个原因。
mapred.child.java.opts
一般来说,都是reduce耗费内存比较大,这个选项是用来设置JVM堆的最大可用内存,但不要设置过大,如果超过2G(这个数字有待考证),就应该考虑一下优化程序。
Input Split的大小,决定了一个Job拥有多少个map,默认64M每个Split,如果输入的数据量巨大,那么默认的64M的block会有特别多Map Task,集群的网络传输会很大,给Job Tracker的调度、队列、内存都会带来很大压力。
mapred.min.split.size
这个配置决定了每个Input Split 的最小值,也间接决定了一个job的map数量
HDFS块大小是在job写入时决定的,而分片的大小,是由三个元素决定的(在3个中取最大的那个)
(1) 输入的块数 (2) mapred.min.split.size (3) job.setNumMapTasks()
mapred.compress.map.output
压缩Map的输出,这样做有两个好处:
a)压缩是在内存中进行,所以写入map本地磁盘的数据就会变小,大大减少了本地IO次数
b) reduce从每个map节点copy数据,也会明显降低网络传输的时间
注:数据序列化其实效果会更好,无论是磁盘IO还是数据大小,都会明显的降低。
io.sort.mb
以MB为单位,默认100M,这个值比较小
map节点没运行完时,内存的数据过多,要将内存中的内容写入洗盘,这个设置就是设置内存缓冲的大小,在suffle之前这个选项定义了map输出结果在内存里占用buffer的大小,当buffer达到某个阈值(后面那条配置),会启动一个后台线程来对buffer的内容进行排序,然后写入本地磁盘(一个spill文件)
根据map输出数据量的大小,可以适当的调整buffer的大小,注意是适当的调整,并不是越大越好,假设内存无限大,io.sort.mb=1024(1G), 和io.sort.mb=300 (300M),前者未必比后者快:
(1)1G的数据排序一次
(2)排序3次,每次300MB
一定是后者快(归并排序)
io.sort.spill.percent
这个值就是上面提到的buffer的阈值,默认是0.8,即80%,当buffer中的数据达到这个阈值,后台线程会起来对buffer中已有的数据进行排序,然后写入磁盘,此时map输出的数据继续往剩余的20% buffer写数据,如果buffer的剩余20%写满,排序还没结束,map task被block等待。
如果你确认map输出的数据基本有序,排序时间很短,可以将这个阈值适当调高,更理想的,如果你的map输出是有序的数据,那么可以把buffer设的更大,阈值设置为1.
io.sort.factor
同时打开的文件句柄的数量,默认是10
当一个map task执行完之后,本地磁盘上(mapred.local.dir)有若干个spill文件,map task最后做的一件事就是执行merge sort,把这些spill文件合成一个文件(partition,combine阶段)。
执行merge sort的时候,每次同时打开多少个spill文件,就是由io.sort.factor决定的。打开的文件越多,不一定merge sort就越快,也要根据数据情况适当的调整。
注:merge排序的结果是两个文件,一个是index,另一个是数据文件,index文件记录了每个不同的key在数据文件中的偏移量(即partition)。
在map节点上,如果发现map所在的子节点的机器io比较重,原因可能是io.sort.factor这个设置的比较小,io.sort.factor设置小的话,如果spill文件比较多,merge成一个文件要很多轮读取操作,这样就提升了io的负载。io.sort.mb小了,也会增加io的负载。
如果设置了执行combine的话,combine只是在merge的时候,增加了一步操作,不会改变merge的流程,所以combine不会减少或者增加文件个数。另外有个min.num.spills.for.combine的参数,表示执行一个merge操作时,如果输入文件数小于这个数字,就不调用combiner。如果设置了combiner,在写spill文件的时候也会调用,这样加上merge时候的调用,就会执行两次combine。
提高reduce的执行效率,除了在hadoop框架方面的优化,重点还是在代码逻辑上的优化.比如:对reduce接受到的value可能有重复的,此时如果用Java的Set或者STL的Set来达到去重的目的,那么这个程序不是扩展良好的(non-scalable),受到数据量的限制,当数据膨胀,内存势必会溢出 mapred.reduce.parallel.copies
reduce copy数据的线程数量,默认值是5 reduce到每个完成的Map Task 拷贝数据(通过RPC调用),默认同时启动5个线程到map节点取数据。这个配置还是很关键的,
如果你的map输出数据很大,有时候会发现map早就100%了,reduce却在缓慢的变化,那就是copy数据太慢了,比如5个线程 copy 10G的数据,确实会很慢,这时就要调整这个参数,但是调整的太大,容易造成集群拥堵,所以 Job tuning的同时,也是个权衡的过程,要熟悉所用的数据!
mapred.job.shuffle.input.buffer.percent
当指定了JVM的堆内存最大值以后,上面这个配置项就是Reduce用来存放从Map节点取过来的数据所用的内存占堆内存的比例,默认是0.7,即70%,通常这个比例是够了,但是对于大数据的情况,这个比例还是小了一些,0.8-0.9之间比较合适。(前提是你的reduce函数不会疯狂的吃掉内存mapred.job.shuffle.merge.percent(默认值0.66)
mapred.inmem.merge.threshold(默认值1000)
第一个指的是从Map节点取数据过来,放到内存,当达到这个阈值之后,后台启动线程(通常是Linux native process)把内存中的数据merge sort,写到reduce节点的本地磁盘;
第二个指的是从map节点取过来的文件个数,当达到这个个数之后,也进行merger sort,然后写到reduce节点的本地磁盘;这两个配置项第一个优先判断,其次才判断第二个thresh-hold。
从实际经验来看,mapred.job.shuffle.merge.percent默认值偏小,完全可以设置到0.8左右;第二个默认值1000,完全取决于map输出数据的大小,如果map输出的数据很大,默认值1000反倒不好,应该小一些,如果map输出的数据不大(lightweight),可以设置2000或者以上。
mapred.reduce.slowstart.completed.maps (map完成多少百分比时,开始shuffle)
当map运行慢,reduce运行很快时,如果不设置mapred.reduce.slowstart.completed.maps会使job的shuffle时间变的很长,map运行完很早就开始了reduce,导致reduce的slot一直处于被占用状态。mapred.reduce.slowstart.completed.maps 这个值是和“运行完的map数除以总map数”做判断的,当后者大于等于设定的值时,开始reduce的shuffle。所以当map比reduce的执行时间多很多时,可以调整这个值(0.75,0.80,0.85及以上)
下面从流程里描述一下各个参数的作用:
当map task开始运算,并产生中间数据时,其产生的中间结果并非直接就简单的写入磁盘。这中间的过程比较复杂,并且利用到了
内存buffer来进行已经产生的部分结果的缓存,并在内存buffer中进行一些预排序来优化整个map的性能。每一个map都会对应存
在一个内存buffer(MapOutputBuffer),map会将已经产生的部分结果先写入到该buffer中,这个buffer默认是100MB大小,但
是这个大小是可以根据job提交时的参数设定来调整的,该参数即为:io.sort.mb。当map的产生数据非常大时,并且把io.sort.mb
调大,那么map在整个计算过程中spill的次数就势必会降低,map task对磁盘的操作就会变少,如果map tasks的瓶颈在磁盘上,
这样调整就会大大提高map的计算性能。
map在运行过程中,不停的向该buffer中写入已有的计算结果,但是该buffer并不一定能将全部的map输出缓存下来,当map输出
超出一定阈值(比如100M),那么map就必须将该buffer中的数据写入到磁盘中去,这个过程在mapreduce中叫做spill。map并
不是要等到将该buffer全部写满时才进行spill,因为如果全部写满了再去写spill,势必会造成map的计算部分等待buffer释放空间的
情况。所以,map其实是当buffer被写满到一定程度(比如80%)时,就开始进行spill。这个阈值也是由一个job的配置参数来控
制,即io.sort.spill.percent,默认为0.80或80%。这个参数同样也是影响spill频繁程度,进而影响map task运行周期对磁盘的读写
频率的。但非特殊情况下,通常不需要人为的调整。调整io.sort.mb对用户来说更加方便。
当map task的计算部分全部完成后,如果map有输出,就会生成一个或者多个spill文件,这些文件就是map的输出结果。map在正
常退出之前,需要将这些spill合并(merge)成一个,所以map在结束之前还有一个merge的过程。merge的过程中,有一个参数
可以调整这个过程的行为,该参数为:io.sort.factor。该参数默认为10。它表示当merge spill文件时,最多能有多少并行的stream
向merge文件中写入。比如如果map产生的数据非常的大,产生的spill文件大于10,而io.sort.factor使用的是默认的10,那么当
map计算完成做merge时,就没有办法一次将所有的spill文件merge成一个,而是会分多次,每次最多10个stream。这也就是说,
当map的中间结果非常大,调大io.sort.factor,有利于减少merge次数,进而减少map对磁盘的读写频率,有可能达到优化作业的
目的。
当job指定了combiner的时候,我们都知道map介绍后会在map端根据combiner定义的函数将map结果进行合并。运行combiner 函数的时机有可能会是merge完成之前,或者之后,这个时机可以由一个参数控制,即min.num.spill.for.combine(default 3),
当job中设定了combiner,并且spill数最少有3个的时候,那么combiner函数就会在merge产生结果文件之前运行。通过这样的方式,就可以在spill非常多需要merge,并且很多数据需要做conbine的时候,减少写入到磁盘文件的数据数量,同样是为了减少对磁盘的读写频率,有可能达到优化作业的目的。
减少中间结果读写进出磁盘的方法不止这些,还有就是压缩。也就是说map的中间,无论是spill的时候,还是最后merge产生的结果文件,都是可以压缩的。压缩的好处在于,通过压缩减少写入读出磁盘的数据量。对中间结果非常大,磁盘速度成为map执行瓶颈的job,尤其有用。控制map中间结果是否使用压缩的参数为:mapred.compress.map.output(true/false)。将这个参数设置为true时,那么map在写中间结果时,就会将数据压缩后再写入磁盘,读结果时也会采用先解压后读取数据。这样做的后果就是:写入磁盘的中间结果数据量会变少,但是cpu会消耗一些用来压缩和解压。所以这种方式通常适合job中间结果非常大,瓶颈不在cpu,而是在磁盘的读写的情况。说的直白一些就是用cpu换IO。根据观察,通常大部分的作业cpu都不是瓶颈,除非运算逻辑异常复杂。所以对中间结果采用压缩通常来说是有收益的。
当采用map中间结果压缩的情况下,用户还可以选择压缩时采用哪种压缩格式进行压缩,现在hadoop支持的压缩格式有:
GzipCodec,LzoCodec,BZip2Codec,LzmaCodec等压缩格式。通常来说,想要达到比较平衡的cpu和磁盘压缩比,LzoCodec
比较适合。但也要取决于job的具体情况。用户若想要自行选择中间结果的压缩算法,可以设置配置参数:
mapred.map.output.compression.codec=org.apache.hadoop.io.compress.DefaultCodec或者其他用户自行选择的压缩方式。
---------------------
用fsck命令统计 查看HDFS上在某一天日志的大小,分块情况以及平均的块大小,即
[hduser@da-master jar]$ hadoop fsck /wcc/da/kafka/report/2015-01-11
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
15/01/13 18:57:23 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Connecting to namenode via http://da-master:50070
FSCK started by hduser (auth:SIMPLE) from /172.21.101.30 for path /wcc/da/kafka/report/2015-01-11 at Tue Jan 13 18:57:24 CST 2015
....................................................................................................
....................................................................................................
........................................Status: HEALTHY
Total size: 9562516137 B
Total dirs: 1
Total files: 240
Total symlinks: 0
Total blocks (validated): 264 (avg. block size 36221652 B)
Minimally replicated blocks: 264 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 2
Average block replication: 2.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 5
Number of racks: 1
FSCK ended at Tue Jan 13 18:57:24 CST 2015 in 14 milliseconds
The filesystem under path '/wcc/da/kafka/report/2015-01-11' is HEALTHY
用表格整理出来:
Date Time
Total(GB)
Total blocks
AveBlockSize(MB)
2014/12/21
9.39
268
36
2014/12/20
9.5
268
36
2014/12/19
8.89
268
34
2014/11/5
8.6
266
33
2014/10/1
9.31
268
36
分析问题的存在性:从表中可以看出,每天日志量的分块情况:总共大概有268左右的块数,平均块大小为36MB左右,远远不足128MB,这潜在的说明了一个问题。日志产生了很多小文件,大多数都不足128M,严重影响集群的扩展性和性能:首先,在HDFS中,任何block,文件或者目录在内存中均以对象的形式存储,每个对象约占150byte,如果有1000 0000个小文件,每个文件占用一个block,则namenode大约需要2G空间。如果存储1亿个文件,则namenode需要20G空间,这样namenode内存容量严重制约了集群的扩展; 其次,访问大量小文件速度远远小于访问几个大文件;HDFS最初是为流式访问大文件开发的,如果访问大量小文件,需要不断的从一个datanode跳到另一个datanode,严重影响性能;最后,处理大量小文件速度远远小于处理同等大小的大文件的速度,因为每一个小文件要占用一个slot,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上,累计起来的总时长必然增加。我们采取的策略是先合并小文件,比如整理日志成user_report.tsv,client_report.tsv,AppLog_UserDevice.tsv, 再运行job
---------------------
Hive的后端存储是HDFS,它对大文件的处理是非常高效的,如果合理配置文件系统的块大小,NameNode可以支持很大的数据量。但是在数据仓库中,越是上层的表其汇总程度就越高,数据量也就越小。而且这些表通常会按日期进行分区,随着时间的推移,HDFS的文件数目就会逐渐增加。
小文件带来的问题
关于这个问题的阐述可以读一读Cloudera的这篇文章。简单来说,HDFS的文件元信息,包括位置、大小、分块信息等,都是保存在NameNode的内存中的。每个对象大约占用150个字节,因此一千万个文件及分块就会占用约3G的内存空间,一旦接近这个量级,NameNode的性能就会开始下降了。
此外,HDFS读写小文件时也会更加耗时,因为每次都需要从NameNode获取元信息,并与对应的DataNode建立连接。对于MapReduce程序来说,小文件还会增加Mapper的个数,每个脚本只处理很少的数据,浪费了大量的调度时间。当然,这个问题可以通过使用CombinedInputFile和JVM重用来解决。
Hive小文件产生的原因
前面已经提到,汇总后的数据量通常比源数据要少得多。而为了提升运算速度,我们会增加Reducer的数量,Hive本身也会做类似优化——Reducer数量等于源数据的量除以hive.exec.reducers.bytes.per.reducer所配置的量(默认1G)。Reducer数量的增加也即意味着结果文件的增加,从而产生小文件的问题。
解决小文件的问题可以从两个方向入手:
1. 输入合并。即在Map前合并小文件
2. 输出合并。即在输出结果的时候合并小文件
配置Map输入合并
-- 每个Map最大输入大小,决定合并后的文件数
set mapred.max.split.size=256000000;
-- 一个节点上split的至少的大小 ,决定了多个data node上的文件是否需要合并
set mapred.min.split.size.per.node=100000000;
-- 一个交换机下split的至少的大小,决定了多个交换机上的文件是否需要合并
set mapred.min.split.size.per.rack=100000000;
-- 执行Map前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
配置Hive结果合并
我们可以通过一些配置项来使Hive在执行结束后对结果文件进行合并:
hive.merge.mapfiles 在map-only job后合并文件,默认true
hive.merge.mapredfiles 在map-reduce job后合并文件,默认false
hive.merge.size.per.task 合并后每个文件的大小,默认256000000
hive.merge.smallfiles.avgsize 平均文件大小,是决定是否执行合并操作的阈值,默认16000000
Hive在对结果文件进行合并时会执行一个额外的map-only脚本,mapper的数量是文件总大小除以size.per.task参数所得的值,触发合并的条件是:
根据查询类型不同,相应的mapfiles/mapredfiles参数需要打开;
结果文件的平均大小需要大于avgsize参数的值。
示例:
-- map-red job,5个reducer,产生5个60K的文件。
create table dw_stage.zj_small as
select paid, count (*)
from dw_db.dw_soj_imp_dtl
where log_dt = '2014-04-14'
group by paid;
-- 执行额外的map-only job,一个mapper,产生一个300K的文件。
set hive.merge.mapredfiles= true;
create table dw_stage.zj_small as
select paid, count (*)
from dw_db.dw_soj_imp_dtl
where log_dt = '2014-04-14'
group by paid;
-- map-only job,45个mapper,产生45个25M左右的文件。
create table dw_stage.zj_small as
select *
from dw_db.dw_soj_imp_dtl
where log_dt = '2014-04-14'
and paid like '�idu%' ;
-- 执行额外的map-only job,4个mapper,产生4个250M左右的文件。
set hive.merge.smallfiles.avgsize=100000000;
create table dw_stage.zj_small as
select *
from dw_db.dw_soj_imp_dtl
where log_dt = '2014-04-14'
and paid like '�idu%' ;
压缩文件的处理
对于输出结果为压缩文件形式存储的情况,要解决小文件问题,如果在Map输入前合并,对输出的文件存储格式并没有限制。但是如果使用输出合并,则必须配合SequenceFile来存储,否则无法进行合并,以下是示例:
set mapred.output.compression. type=BLOCK;
set hive.exec.compress.output= true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.LzoCodec;
set hive.merge.smallfiles.avgsize=100000000;
drop table if exists dw_stage.zj_small;
create table dw_stage.zj_small
STORED AS SEQUENCEFILE
as select *
from dw_db.dw_soj_imp_dtl
where log_dt = '2014-04-14'
and paid like '�idu%' ;
使用HAR归档文件
Hadoop的归档文件格式也是解决小文件问题的方式之一。而且Hive提供了原生支持:
set hive.archive.enabled= true;
set hive.archive.har.parentdir.settable= true;
set har.partfile.size=1099511627776;
ALTER TABLE srcpart ARCHIVE PARTITION(ds= '2008-04-08', hr= '12' );
ALTER TABLE srcpart UNARCHIVE PARTITION(ds= '2008-04-08', hr= '12' );
如果使用的不是分区表,则可创建成外部表,并使用har://协议来指定路径。
1. HDFS上的小文件问题
小文件是指文件大小明显小于HDFS上块(block)大小(默认64MB)的文件。如果存储小文件,必定会有大量这样的小文件,否则你也不会使用Hadoop(If you’re storing small files, then you probably have lots of them (otherwise you wouldn’t turn to Hadoop)),这样的文件给hadoop的扩展性和性能带来严重问题。当一个文件的大小小于HDFS的块大小(默认64MB),就将认定为小文件否则就是大文件。为了检测输入文件的大小,可以浏览Hadoop DFS 主页 http://machinename:50070/dfshealth.jsp ,并点击Browse filesystem(浏览文件系统)。
首先,在HDFS中,任何一个文件,目录或者block在NameNode节点的内存中均以一个对象表示(元数据)(Every file, directory and block in HDFS is represented as an object in the namenode’s memory),而这受到NameNode物理内存容量的限制。每个元数据对象约占150byte,所以如果有1千万个小文件,每个文件占用一个block,则NameNode大约需要2G空间。如果存储1亿个文件,则NameNode需要20G空间,这毫无疑问1亿个小文件是不可取的。
其次,处理小文件并非Hadoop的设计目标,HDFS的设计目标是流式访问大数据集(TB级别)。因而,在HDFS中存储大量小文件是很低效的。访问大量小文件经常会导致大量的寻找,以及不断的从一个DatanNde跳到另一个DataNode去检索小文件(Reading through small files normally causes lots of seeks and lots of hopping from datanode to datanode to retrieve each small file),这都不是一个很有效的访问模式,严重影响性能。
最后,处理大量小文件速度远远小于处理同等大小的大文件的速度。每一个小文件要占用一个slot,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上。
2. MapReduce上的小文件问题
Map任务(task)一般一次处理一个块大小的输入(input)(默认使用FileInputFormat)。如果文件非常小,并且拥有大量的这种小文件,那么每一个map task都仅仅处理非常小的input数据,因此会产生大量的map tasks,每一个map task都会额外增加bookkeeping开销(each of which imposes extra bookkeeping overhead)。一个1GB的文件,拆分成16个块大小文件(默认block size为64M),相对于拆分成10000个100KB的小文件,后者每一个小文件启动一个map task,那么job的时间将会十倍甚至百倍慢于前者。
Hadoop中有一些特性可以用来减轻bookkeeping开销:可以在一个JVM中允许task JVM重用,以支持在一个JVM中运行多个map task,以此来减少JVM的启动开销(通过设置mapred.job.reuse.jvm.num.tasks属性,默认为1,-1表示无限制)。(译者注:如果有大量小文件,每个小文件都要启动一个map task,则必相应的启动JVM,这提供的一个解决方案就是重用task 的JVM,以此减少JVM启动开销);另 一种方法是使用MultiFileInputSplit,它可以使得一个map中能够处理多个split。
3. 为什么会产生大量的小文件
至少有两种场景下会产生大量的小文件:
(1)这些小文件都是一个大逻辑文件的一部分。由于HDFS在2.x版本开始支持对文件的append,所以在此之前保存无边界文件(例如,log文件)(译者注:持续产生的文件,例如日志每天都会生成)一种常用的方式就是将这些数据以块的形式写入HDFS中(a very common pattern for saving unbounded files (e.g. log files) is to write them in chunks into HDFS)。
(2)文件本身就是很小。设想一下,我们有一个很大的图片语料库,每一个图片都是一个独一的文件,并且没有一种很好的方法来将这些文件合并为一个大的文件。
4. 解决方案
这两种情况需要有不同的解决方 式。
4.1 第一种情况
对于第一种情况,文件是许多记录(Records)组成的,那么可以通过调用HDFS的sync()方法(和append方法结合使用),每隔一定时间生成一个大文件。或者,可以通过写一个程序来来合并这些小文件(可以看一下Nathan Marz关于Consolidator一种小工具的文章)。
4.2 第二种情况
对于第二种情况,就需要某种形式的容器通过某种方式来对这些文件进行分组。Hadoop提供了一些选择:
4.2.1 HAR File
Hadoop Archives (HAR files)是在0.18.0版本中引入到HDFS中的,它的出现就是为了缓解大量小文件消耗NameNode内存的问题。HAR文件是通过在HDFS上构建一个分层文件系统来工作。HAR文件通过hadoop archive命令来创建,而这个命令实 际上是运行了一个MapReduce作业来将小文件打包成少量的HDFS文件(译者注:将小文件进行合并几个大文件)。对于client端来说,使用HAR文件没有任何的改变:所有的原始文件都可见以及可访问(只是使用har://URL,而不是hdfs://URL),但是在HDFS中中文件数却减少了。
读取HAR中的文件不如读取HDFS中的文件更有效,并且实际上可能较慢,因为每个HAR文件访问需要读取两个索引文件以及还要读取数据文件本身(如下图)。尽管HAR文件可以用作MapReduce的输入,但是没有特殊的魔法允许MapReduce直接操作HAR在HDFS块上的所有文件(although HAR files can be used as input to MapReduce, there is no special magic that allows maps to operate over all the files in the HAR co-resident on a HDFS block)。 可以考虑通过创建一种input format,充分利用HAR文件的局部性优势,但是目前还没有这种input format。需要注意的是:MultiFileInputSplit,即使在HADOOP-4565(https://issues.apache.org/jira/browse/HADOOP-4565)的改进,但始终还是需要每个小文件的寻找。我们非常有兴趣看到这个与SequenceFile进行对比。 在目前看来,HARs可能最好仅用于存储文档(At the current time HARs are probably best used purely for archival purposes.)。
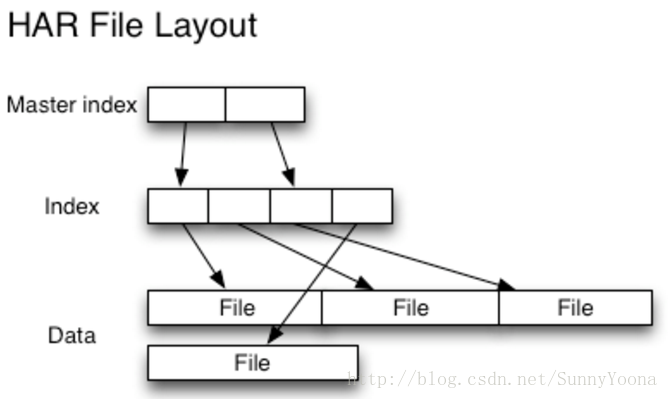
4.2.2 SequenceFile
通常对于"小文件问题"的回应会是:使用序列文件(SequenceFile)。这种方法的思路是,使用文件名(filename)作为key,并且文件内容(file contents)作为value,如下图。在实践中这种方式非常有效。我们回到10,000个100KB小文件问题上,你可以编写一个程序将它们放入一个单一的SequenceFile,然后你可以流式处理它们(直接处理或使用MapReduce)操作SequenceFile。这样同时会带来两个优势:(1)SequenceFiles是可拆分的,因此MapReduce可以将它们分成块并独立地对每个块进行操作;(2)它们同时支持压缩,不像HAR。 在大多数情况下,块压缩是最好的选择,因为它将压缩几个记录为一个块,而不是一个记录压缩一个块。(Block compression is the best option in most cases, since it compresses blocks of several records (rather than per record))。

将现有数据转换为SequenceFile可能很慢。 但是,完全可以并行创建SequenceFile的集合。(It can be slow to convert existing data into Sequence Files. However, it is perfectly possible to create a collection of Sequence Files in parallel.)Stuart Sierra写了一篇关于将tar文件转换为SequenceFile的文章(https://stuartsierra.com/2008/04/24/a-million-little-files ),像这样的工具是非常有用的,我们应该多看看。展望未来,最好设计数据管道,将源数据直接写入SequenceFile(如果可能),而不是作为中间步骤写入小文件。
与HAR文件不同,没有办法列出SequenceFile中的所有键,所以不能读取整个文件。Map File,就像对键进行排序的SequenceFile,只维护了部分索引,所以他们也不能列出所有的键,如下图。
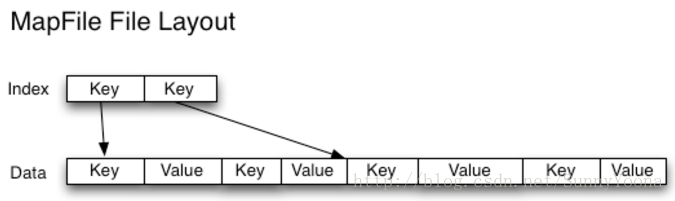
SequenceFile是以Java为中心的。 TFile(https://issues.apache.org/jira/browse/HADOOP-4565 )设计为跨平台,并且可以替代SequenceFile,不过现在还不可用。
4.2.3 HBase
如果你生产很多小文件,那么根据访问模式,不同类型的存储可能更合适(If you are producing lots of small files, then, depending on the access pattern, a different type of storage might be more appropriate)。HBase以Map Files(带索引的SequenceFile)方式存储数据,如果您需要随机访问来执行MapReduce式流式分析,这是一个不错的选择( HBase stores data in MapFiles (indexed SequenceFiles), and is a good choice if you need to do MapReduce style streaming analyses with the occasional random look up)。如果延迟是一个问题,那么还有很多其他选择 - 参见Richard Jones对键值存储的调查(http://www.metabrew.com/article/anti-rdbms-a-list-of-distributed-key-value-stores/)。
原文:http://blog.cloudera.com/blog/2009/02/the-small-files-problem/
Hadoop平台作业参数设置关于mapreduce.job.split.metainfo.maxsize的说明
1、MR程序时执行时报错:
YarnRuntimeException: java.io.IOException:Split metadata size exceeded 10000000.
2、原因分析:
输入文件包括大量小文件或者文件目录,造成Splitmetainfo文件超过默认上限。
3、解决办法:
在mapred-site.xml配置文件中:
修改默认作业参数mapreduce.jobtracker.split.metainfo.maxsize =100000000
或者mapreduce.jobtracker.split.metainfo.maxsize = -1 (默认值是1000000)
<property>
<name>mapreduce.job.split.metainfo.maxsize</name>
<value>10000000</value>
</property>
4、深入分析:
job.splitmetainfo该文件记录split的元数据信息,如input文件过多,记录的文件结构信息超出默认设置就会报错;
这个机制也是Hadoop集群要求文件大小不能过小或目录过多,避免namenode出现元数据加载处理瓶颈,这种业务一般会出现在存储图片上。
如block默认128M,则文件应大于这个,尽量合并小文件
---------------------
运行大作业(文件数目多)时需要注意的参数:
Hadoop2 采用Yarn管理作业,与Hadoop1不同的是,Hadoop2会控制每个任务的内存数量。因此,当作业执行失败时,可根据报错信息调整以下参数
参数一: AM内存
MR_ApplicationMaster占用的内存量。如果一个作业的map过多,可能导致am内存溢出,进而作业失败。
conf.set("yarn.app.mapreduce.am.resource.mb", "3000"); 单位MB. 超过5万个map任务时,建议设为3000以上
conf.set("yarn.app.mapreduce.am.command-opts", "-Djava.net.preferIPv4Stack=true -Xmx2125955249"); 单位字节,一般设为上一个值的70%
还有一个参数mapreduce.job.split.metainfo.maxsize,这是是文件分片的存储空间,建议设为-1,不对其进行限制
Map数太多时,还有一种办法可以有效减少Map数,从而大大降低资源消耗,缩短执行时间,见本文末尾
参数二:Mapper/Reducer内存
Mapper/Reducer内存由两个参数控制。一个是java.opts,代表java进程内存,用于java作业,以及hadoop系统任务,比如排序等;另一个是memory.mb,代表任务总内存,包括java进程内存以及非java内存,比如streaming中的python进程。一般前一个值设为后一个的70%
如果运行过程中Mapper/reduce因内存超量被杀死,或者报OOM,尝试调大以上两个参数。
map java内存:conf.set("mapreduce.map.java.opts", "-Djava.net.preferIPv4Stack=true -Xmx1625955249"); 单位字节
map总内存:conf.set("mapreduce.map.memory.mb", "2000"); 单位MB
reduce java内存:conf.set("mapreduce.reduce.java.opts", "-Djava.net.preferIPv4Stack=true -Xmx1625955249");单位字节
reduce 总内存:conf.set("mapreduce.reduce.memory.mb", "2000"); 单位MB
参数三:虚拟内存
Yarn同时会监控任务虚拟内存用量,如果超量,同样会杀死任务
每单位的物理内存总量对应的虚拟内存量,默认是2.1,表示每使用1MB的物理内存,最多可以使用2.1MB的虚拟内存总量。
conf.set("yarn.nodemanager.vmem-pmem-ratio", "2.1"); 如果内存够用而虚存超量,则可以调大改参数
参数四:运行队列
Hadoop2.* 的集群对用户队列进行资源配额限制。请大家根据自己的业务设置队列,以免对其他用户的作业造成影响。
队列参数为:mapred.job.queue.name
hive队列设置参数:set mapred.queue.name=hadoop; set mapred.job.queue.name=hadoop;
参数五:map切片大小
用户需要根据自己作业的大小对参数mapred.min.split.size和mapred.max.split.size进行调整。min越大,map数量越少;max越小,map数越多。
用户根据自己队列资源分配上限和具体集群使用情况进行调节。
大作业优化建议
对于大作业(Map数超过5万),建议采用输入文件合并,可利用少量Map处理多个输入split,从而减少对Yarn的资源要求,减少调度开销,加快执行过程。
job.setInputFormatClass(CombinInputFormat.class);
重写InputFormat类,使得多个小文件共用一个map。
一个例子
mapreduce.map.maxattempts=3
mapreduce.reduce.maxattempts=2
yarn.resourcemanager.am.max-retries=2
mapreduce.map.failures.maxpercent=20
mapreduce.job.queuename='amap'
mapreduce.map.memory.mb=1024
mapreduce.map.java.opts="-Xmx725955249"
mapreduce.reduce.memory.mb=1024
mapreduce.reduce.java.opts="-Xmx725955249"
作业较大时,可配置下面的变量
yarn.app.mapreduce.am.command-opts='-Xmx3000000000'
yarn.app.mapreduce.am.resource.mb=5000
mapreduce.job.split.metainfo.maxsize=-1
---------------------

















 1387
1387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









