 数据拟合与模型选择:过拟合与欠拟合的解决方案
数据拟合与模型选择:过拟合与欠拟合的解决方案







在对数据进行拟合,学习模型的过程中,会出现以下情况:
1)high variance, overfitting.过拟合
2)high bias, underfiiting.欠拟合
过拟合出现的原因
1)太多的特征。
2)过少的训练数据。
如何解决?
1)减少特征数
2)模型选择算法(model selection algorithm)
3)正则化:保留特征参数,但尽可能减小其幅值为0。
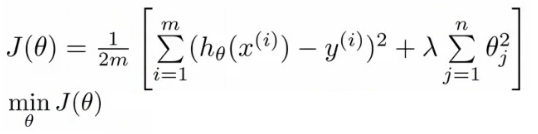
lambuda为正则化参数:看做是一个tradeoff。用于平衡以下两项
1)更好的适应模型
2)将特征的系数尽可能变小
此参数过大,则会出现underfitting. 过小则会出现overfitting.
如何选择正则化参数?后续章节将会论述。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









