



 本文详细阐述了Hadoop分布式文件系统(HDFS)的核心组件和工作原理,包括Namenode和Datanode的角色,以及客户端如何访问HDFS中的文件。重点介绍了数据存储的可靠性保证机制,如冗余副本策略、机架感知、心跳机制、安全模式、校验和及回收站功能。
本文详细阐述了Hadoop分布式文件系统(HDFS)的核心组件和工作原理,包括Namenode和Datanode的角色,以及客户端如何访问HDFS中的文件。重点介绍了数据存储的可靠性保证机制,如冗余副本策略、机架感知、心跳机制、安全模式、校验和及回收站功能。
HDFS是Hadoop的核心模块之一,它是Hadoop分布式文件系统(Hadoop Distributed File System)
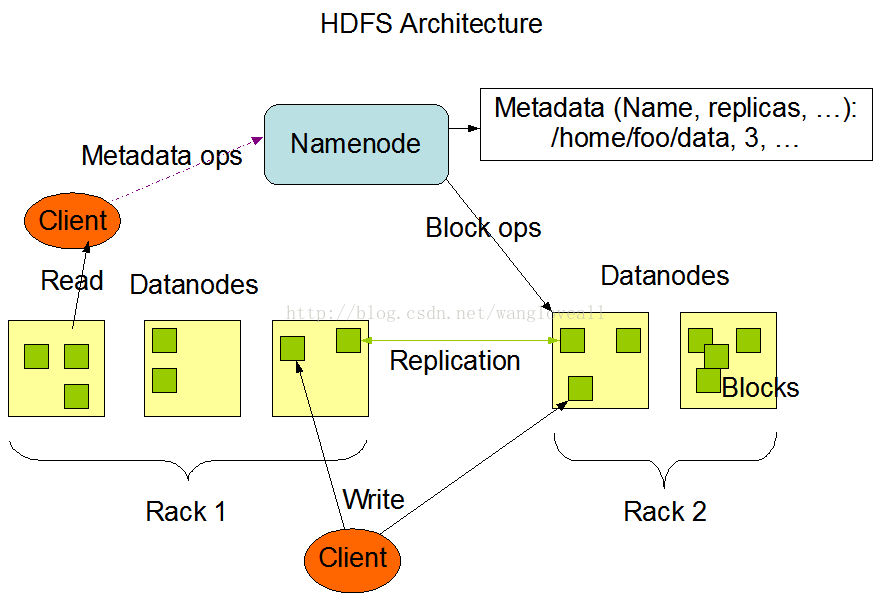
HDFS体系结构如上图所示,它采用主从结构,Namenode属于主段,Datanode属于从端
Namenode
1)管理文件系统的命名空间。
2)记录 每个文件数据快在各个Datanode上的位置和副本信息。
3)协调客户端对文件的访问。
4)记录命名空间内的改动或者空间本省属性的改动。
5)Namenode 使用事务日志记录HDFS元数据的变化。使用映像文件存储文件系统的命名空间,包括文件映射,文件属性等。
从社会学的角度来看,Namenode是HDFS里面的管理者,发挥者管理、协调、操控的作用。
Datanode
1)负责所在物理节点的存储管理。
2)一次写入,多次读取(不修改)。
3)文件由数据库组成,一般情况下,数据块的大小为64MB。
4)数据尽量散步到各个节点。
从社会学的角度来看,Datanode是HDFS的工作者,发挥按着Namenode的命令干活,并且把干活的进展和问题反馈到Namenode的作用。
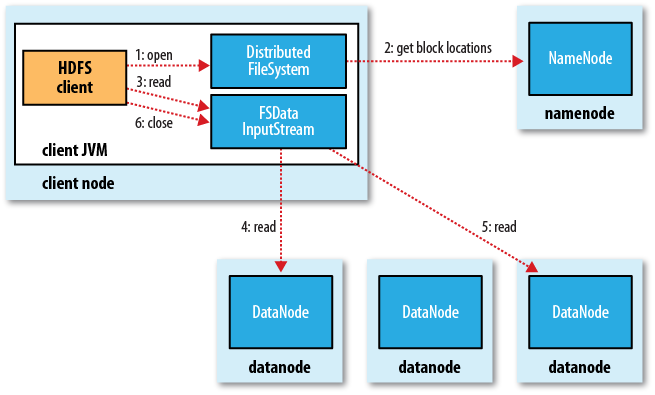
客户端如何访问HDFS中一个文件呢?具体流程如下。
1)首先从Namenode获得组成这个文件的数据块位置列表。
2)接下来根据位置列表知道存储数据块的Datanode。
3)最后访问Datanode获取数据。
注意:Namenode并不参与数据实际传输。
读文件的过程:
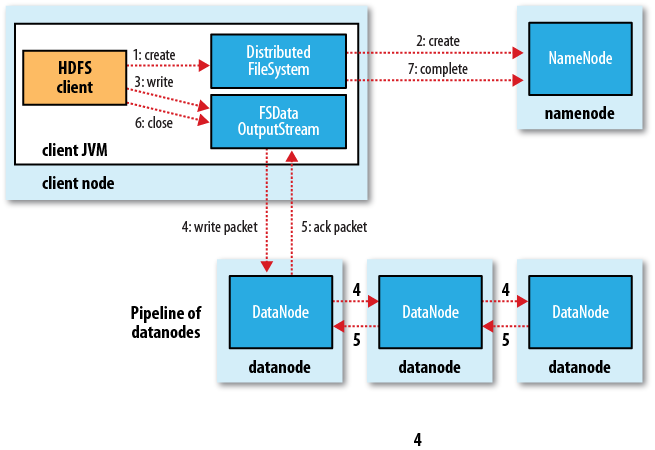
写文件的过程:
数据存储系统,数据存储的可靠性至关重要。HDFS是如何保证其可靠性呢?它主要采用如下机理。
1)冗余副本策略,即所有数据都有副本,副本的数目可以在hdfs-site.xml中设置相应的复制因子。
2)机架策略,即HDFS的“机架感知”,一般在本机架存放一个副本,在其它机架再存放别的副本,这样可以防止机架失效时丢失数据,也可以提供带宽利用率。
3)心跳机制,即Namenode周期性从Datanode接受心跳信号和快报告,没有按时发送心跳的Datanode会被标记为宕机,不会再给任何I/O请求,若是Datanode失效造成副本数量下降,并且低于预先设置的阈值,Namenode会检测出这些数据块,并在合适的时机进行重新复制。
4)安全模式,Namenode启动时会先经过一个“安全模式”阶段。
5)校验和,客户端获取数据通过检查校验和,发现数据块是否损坏,从而确定是否要读取副本。
6)回收站,删除文件,会先到回收站/trash,其里面文件可以快速回复。
7)元数据保护,映像文件和事务日志是Namenode的核心数据,可以配置为拥有多个副本。
8)快照,支持存储某个时间点的映像,需要时可以使数据重返这个时间点的状态。
参考文档:http://www.cnblogs.com/laov/p/3434917.html



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









