 Excel核选框操作指南
Excel核选框操作指南








添加一个核选框(核选为多选):
右键---->单元格格式---->单元类型---->核选框---->参数设置,然后在核选钮正文的位置输入内容
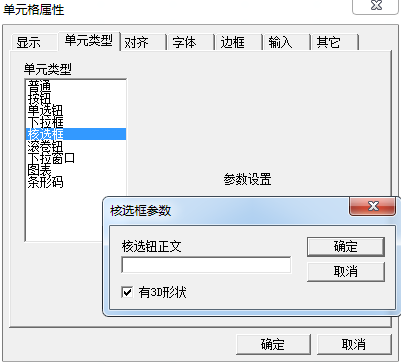
SetCheckCell:向单元格中添加核选扭控件。
SetCheckCell函数的定义形式为:
void SetCheckCell(long col, long row, long sheet, LPCTSTR text, long option)
第一个参数:col:列号;第二个参数:row:行号;第三个参数:sheet:页号;第四个参数:text:核选扭上的文本内容;第五个参数:option:为2是显示3D形状。
GetCheckCellString:获得核选钮单元格中核选钮上的文本内容。
GetCheckCellString函数的定义形式为:
GetCheckCellString(col As Long, row As Long, sheet As Long) As String
第一个参数:col:列号;第二个参数:row:行号;第三个参数:sheet:页号;
GetCellDouble:得到核选框的勾选状态。
GetCellDouble函数的定义形式为:
GetCellDouble(col As Long, row As Long, sheet As Long) As Double
第一个参数:col:列号;第二个参数:row:行号;第三个参数:sheet:页号;
返回值为Double型,1为勾选,0为未勾选

















 3666
3666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









