



 本文深入探讨了Kubernetes和Docker的网络模型,分析了单主机和跨主机的容器通信方案,包括Host、Bridge、Container和None模式的特点与应用场景。特别介绍了Flannel和Calico等网络方案的实现原理和技术优势。
本文深入探讨了Kubernetes和Docker的网络模型,分析了单主机和跨主机的容器通信方案,包括Host、Bridge、Container和None模式的特点与应用场景。特别介绍了Flannel和Calico等网络方案的实现原理和技术优势。
与 Docker 默认的网络模型不同,Kubernetes 形成了一套自己的网络模型,该网络模型更加适应传统的网络模式,应用能够平滑的从非容器环境迁移到 Kubernetes 环境中。
自从 Docker 容器出现,容器的网络通信一直是众人关注的焦点,而容器的网络方案又可以分为两大部分:
- 单主机的容器间通信;
- 跨主机的容器间通信。
一、单主机 Docker 网络通信
利用 Net Namespace 可以为 Docker 容器创建隔离的网络环境,容器具有完全独立的网络栈,与宿主机隔离。也可以使 Docker 容器共享主机或者其他容器的网络命名空间。
我们在使用docker run创建 Docker 容器时,可以使用--network=选项指定容器的网络模式,Docker 有以下 4 种网络模式:
- host 模式,使用
--network=host指定,不支持多主机; - bridge 模式,使用
--network=bridge指定,默认设置,不支持多主机; - container 模式,使用
--network=container:NAME_or_ID指定,即joiner 容器,不支持多主机; - none 模式,使用
--network=none指定,不支持多主机。
1.1、host 模式
连接到 host 网络的容器共享 Docker host 的网络栈,容器的网络配置与 host 完全一样。
我们先查看一下主机的网络。
[root@datanode03 ~]# ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:44:8d:48:70 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
enp1s0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.203 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::2e0:70ff:fe92:4779 prefixlen 64 scopeid 0x20<link>
ether 00:e0:70:92:47:79 txqueuelen 1000 (Ethernet)
RX packets 46093 bytes 66816291 (63.7 MiB)
RX errors 0 dropped 1 overruns 0 frame 0
TX packets 24071 bytes 1814769 (1.7 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 0 (Local Loopback)
RX packets 170 bytes 107720 (105.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 170 bytes 107720 (105.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0然后创建 host 网络的容器,再查看容器的网络信息。
[root@datanode03 ~]# docker run -it --network=host busybox
Unable to find image 'busybox:latest' locally
latest: Pulling from library/busybox
90e01955edcd: Pull complete
Digest: sha256:2a03a6059f21e150ae84b0973863609494aad70f0a80eaeb64bddd8d92465812
Status: Downloaded newer image for busybox:latest
/ # ifconfig
docker0 Link encap:Ethernet HWaddr 02:42:44:8D:48:70
inet addr:172.17.0.1 Bcast:172.17.255.255 Mask:255.255.0.0
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
enp1s0 Link encap:Ethernet HWaddr 00:E0:70:92:47:79
inet addr:192.168.1.203 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::2e0:70ff:fe92:4779/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:45850 errors:0 dropped:1 overruns:0 frame:0
TX packets:23921 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:66794758 (63.7 MiB) TX bytes:1783655 (1.7 MiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:170 errors:0 dropped:0 overruns:0 frame:0
TX packets:170 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:107720 (105.1 KiB) TX bytes:107720 (105.1 KiB)在容器中可以看到 host 的所有网卡,并且连 hostname 也是 host 的,可以直接使用宿主机 IP 地址与外界通信,无需额外进行 NAT 转换。由于容器通信时,不再需要通过 Linux Bridge 等方式转发或者数据包的封装,性能上有很大的优势。
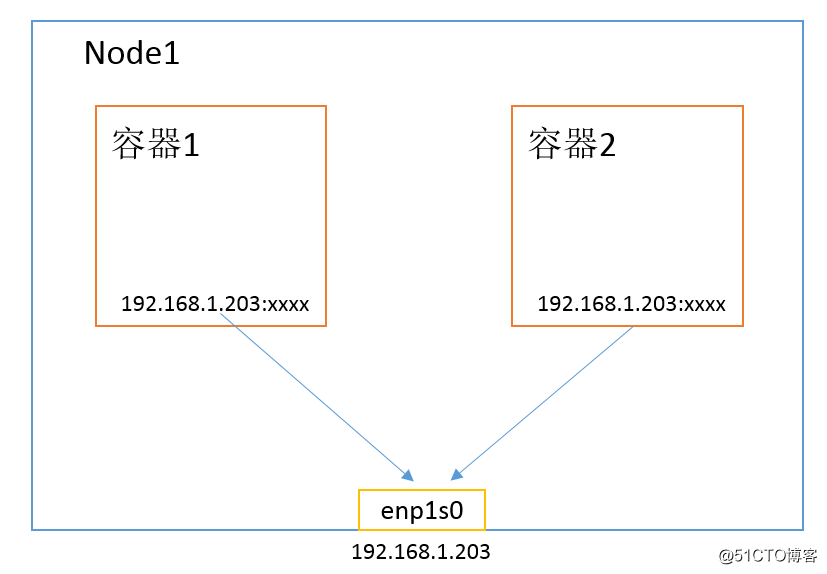
当然,Host 模式有利也有弊,主要包括以下缺点:
容器没有隔离、独立的网络栈:容器因与宿主机共用网络栈而争抢网络资源,并且容器崩溃也可能导致主机崩溃,这再生产环境中是不允许发生的。
端口资源:Docker host 上已经使用的端口就不能再用了。
1.2 Bridge 模式
Bridge 模式是 Docker 默认的网络模式,也是开发者最常用的网络模式。在这种模式下,Docker 为容器创建独立的网络栈,保证容器内的进行使用独立的网络环境,实现容器之间,容器与宿主机之间的网络栈隔离。同时,通过宿主机上的 Docker0 网桥,容器可以与宿主机乃至外界进行网络通信。
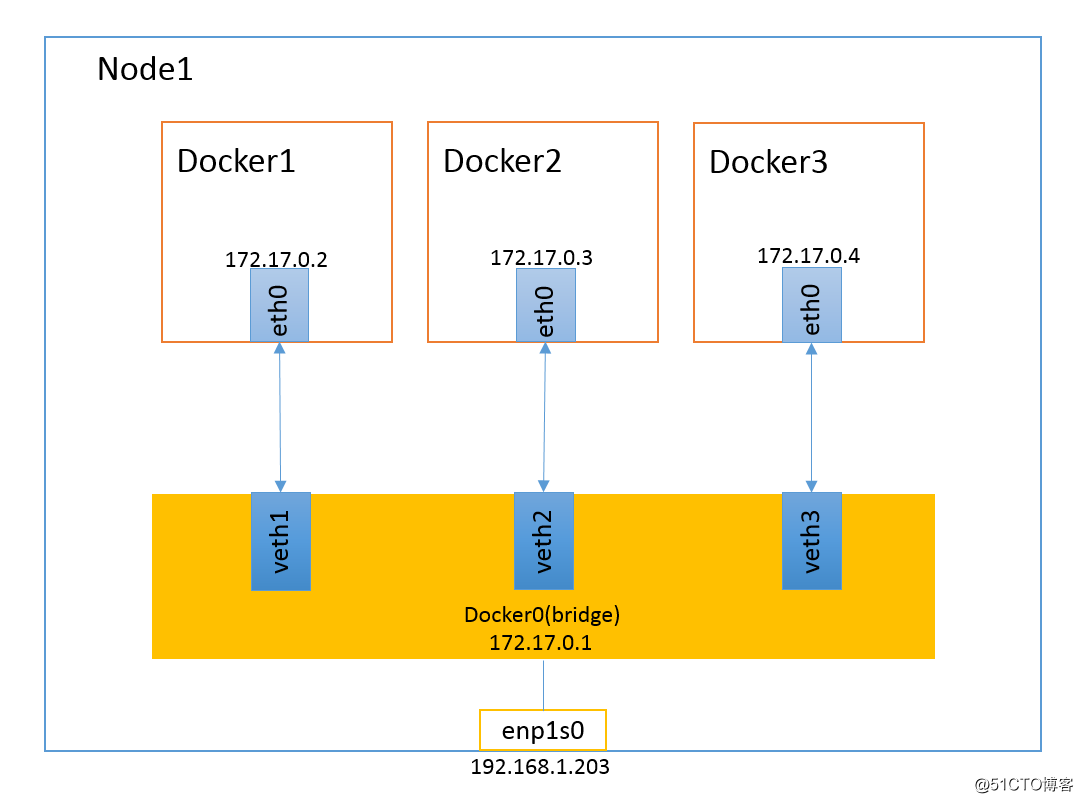
从上图可以看出,容器是可以与宿主机以及外界的其他机器通信的,同一宿主机上,容器之间都是桥接在 Docker0 这个网桥上,Docker0 作为虚拟交换机使容器间互相通信。但是,由于宿主机的 IP 地址与容器 veth pair 的 IP 地址均不在同一个网段,故仅仅依靠 veth pair 和 NameSpace 的技术并不足以使宿主机以外的网络主动发现容器的存在。Docker 采用了端口绑定的方式(通过 iptables 的 NAT),将宿主机上的端口流量转发到容器内的端口上,这样一来,外界就可以与容器中的进程进行通信。
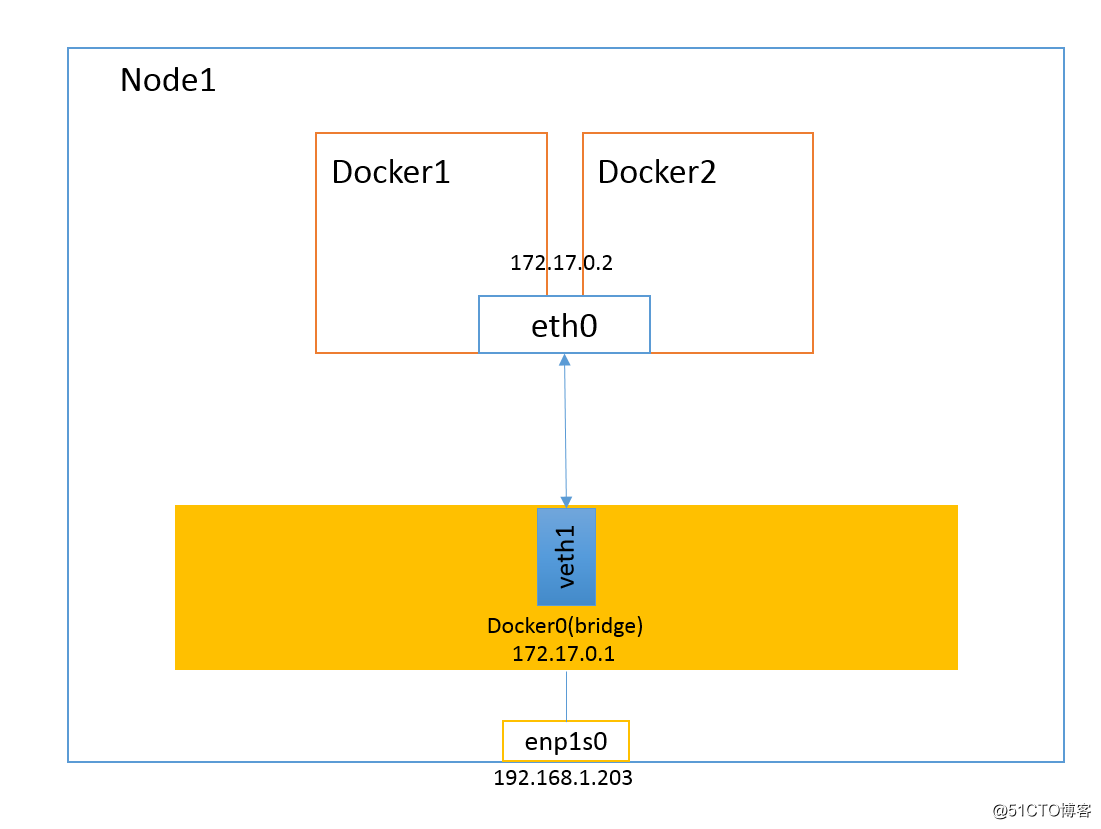
1.3 Container 模式
Container 模式是一种特殊的网络模式。该模式下的容器使用其他容器的网络命名空间,网络隔离性会处于 Bridge 模式与 Host 模式之间。也就是说,当容器与其他容器共享网络命名空间时,这两个容器间不存在网络隔离,但他们与宿主机机器其他容器又存在网络隔离。
Container 模式的容器可以通过 localhost 来与同一网络命名空间下的其他容器通信,传输效率高。这种模式节约了一定数量的网络资源,但并没有改变容器与外界的通信方式。在 Kubernetes 体系架构下引入 Pod 概念,Kubernetes 为 Pod 创建一个基础设施容器,同一 Pod 下的其他容器都以 Container 模式共享这个基础设施容器的网络命名空间,相互之间以 localhost 访问,构成一个统一的整体。
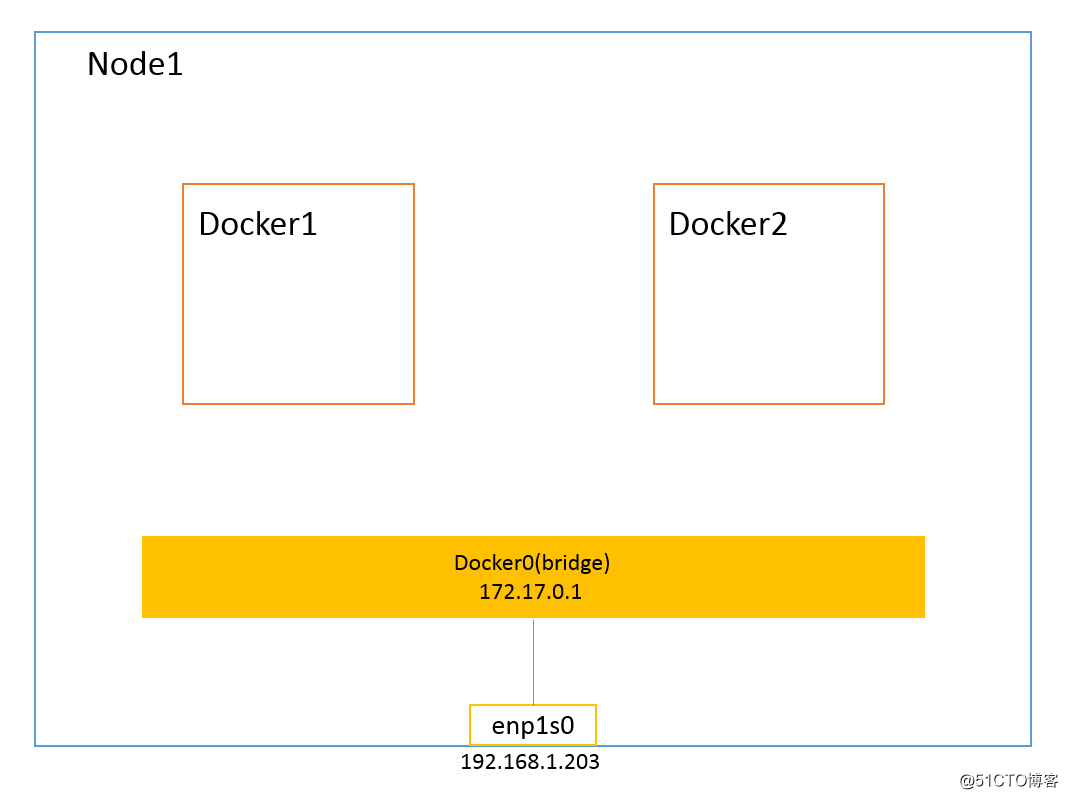
1.4、None 模式
与前几种不同,None 模式的 Docker 容器拥有自己的 Network Namespace,但并不为 Docker 容器进行网络配置。也就是说,该 Docker 容器没有网卡、IP、路由等信息。需要用户为 Docker容器添加网卡、配置 IP 等。
二、跨主机 Docker 网络通信分类
2.1 通信方案
常见的跨主机通信方案主要有以下几种:
- Host 模式:容器直接使用宿主机的网络,这样天生就可以支持跨主机主机通信。这种方式虽然可以解决跨主机通信问题,但应用场景很有限,容易出现端口冲突,也无法做到隔离网络环境,一个容器崩溃很可能引起整个宿主机的崩溃;
- 端口模式:通过绑定容器端口到宿主机端口,跨主机通信时使用
主机 IP + 端口的方式访问容器中的服务。显然,这种方式仅能支持网络栈的 4 层及以上的应用,并且容器与宿主机紧耦合,很难灵活地处理问题,可扩展性不佳; - 定义容器网络:使用 Open vSwitch 或 Flannel 等第三方 SDN 工具,为容器构建可以跨主机通信网络环境。这一类方案一般要求各个主机上的 Docker0 网桥的 cidr 不同,以避免出现 IP 冲突的问题,限制容器在宿主机上可获取的 IP 范围。并且在容器需要对集群外提供服务时,需要比较复杂的配置,对部署实施人员的网络技能要求比较高。
2.2、容器网络规范
容器网络发展到现在,形成了两大阵营:
- Docker 的 CNM;
- Google、CoreOS、Kubernetes 主导的 CNI。
CNM 和 CNI 是网络规范或者网络体系,并不是网络实现,因此不关心容器的网络实现方式,CNM 和 CNI 关心的只是网络管理。
- CNM(Container Network Model):CNM 的优势在于原生,容器网络和 Docker 容器生命周期结合紧密;缺点是被 Docker “绑架”。支持 CNM 网络规范的容器网络实现包括:Docker Swarm overlay、Macvlan & IP networkdrivers、Calico、Contiv、Weave等。
- CNI(Container Network Interface):CNI 的优势是兼容其他容器技术(rkt)以及上层的编排系统(Kubernetes&Mesos)、而且社区活跃势头迅猛;缺点是非 Docker 原生。支持 CNI 的网络规范的容器网络实现包括:Kubernetes、Weave、Macvlan、Calico、Flannel、Contiv、Mesos CNI。
2.3、网络通信实现方案
但从网络实现角度,又可分为:
隧道方案:隧道方案在 IaaS 层的网络中应用也比较多,它的主要缺点是随着节点规模的增长复杂度会提升,而且出了网络问题后跟踪起来比较麻烦,大规模集群情况下这是需要考虑的一个问题。
- Weave:UDP 广播,本机建立新的 BR,通过 PCAP 互通。
- Open vSwitch(OVS):基于 VxLAN 和 GRE 协议,但是性能方面损失比较严重。
- Flannel:UDP 广播,VxLAN。
- Racher:IPSec。
路由方案:一般是基于3层或者2层实现网络隔离和跨主机容器互通的,出了问题也很容易排查。
Calico:基于 BGP 协议的路由方案,支持很细致的 ACL 控制(Nerwork Policy),对混合云亲和度比较高。
Macvlan:从逻辑和 Kernel 层来看,是隔离性和性能最优的方案。基于二层隔离,所以需要二层路由器支持,大多数云服务商不支持,所以混合云上比较难以实现。
三、跨主机 Docker 网络
3.1 Flannel 网络方案
flannel 是 CoreOS 开发的容器网络解决方案。flannel 为每个 host 分配一个 subnet,容器从此 subnet 中分配 IP,这些 IP 可以在 host 间路由,容器间无需 NAT 和 port mapping 就可以跨主机通信。
每个 subnet 都是从一个更大的 IP 池中划分的,flannel 会在每个主机上运行一个叫 flanneld 的 agent,其职责就是从池子中分配 subnet。为了在各个主机间共享信息,flannel 用 etcd(与 consul 类似的 key-value 分布式数据库)存放网络配置、已分配的 subnet、host 的 IP 等信息。
数据包如何在主机间转发是由 backend 实现的。flannel 提供了多种 backend,有 UDP、vxlan、host-gw、aws-vpc、gce 和 alloc 路由,最常用的有 vxlan 和 host-gw。
Flannel 实质上是一种叠加网络(Overlay Network),也就是将 TCP 数据包装在另一种网络包里面进行路由转发和通信。
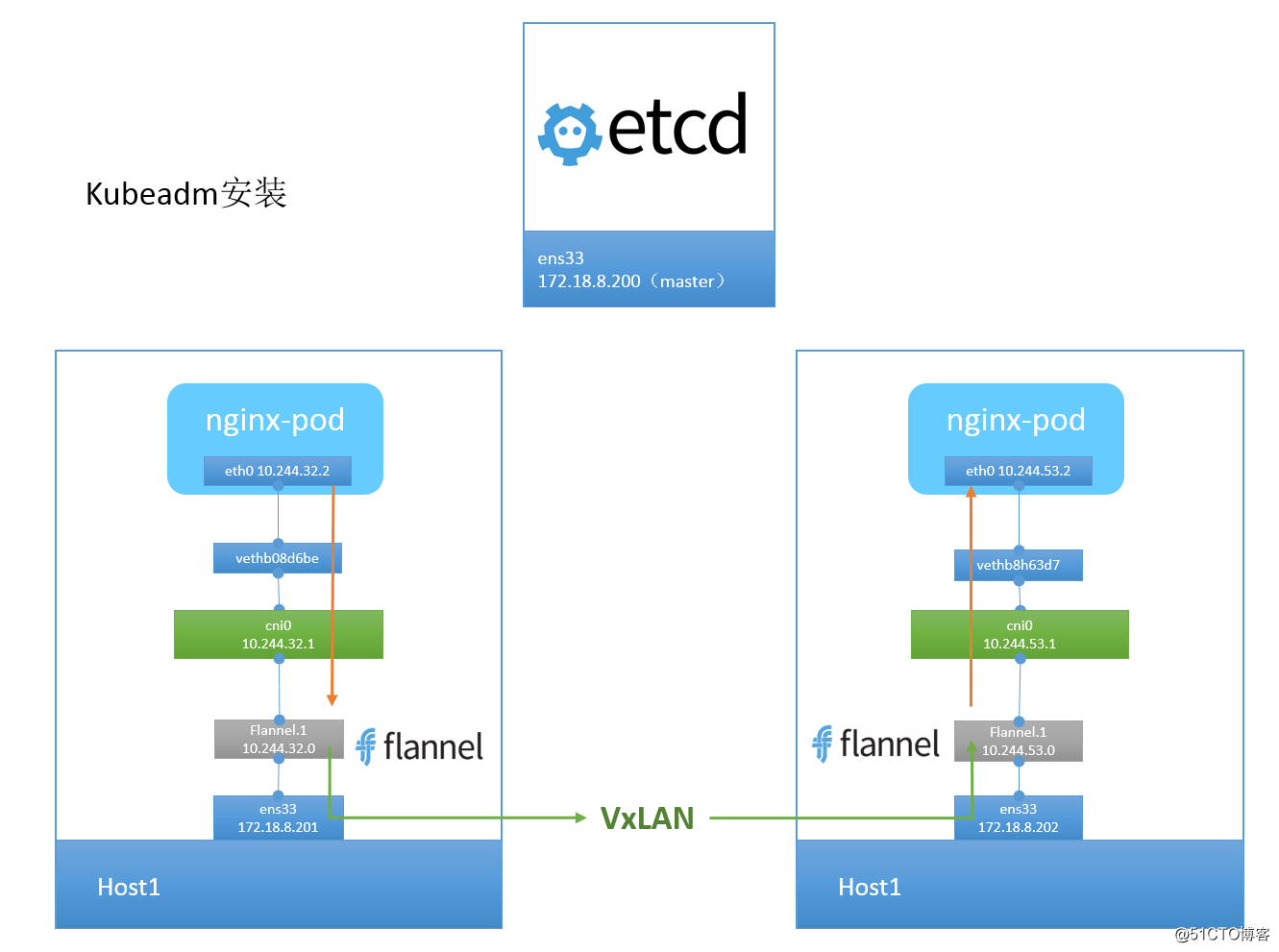
- 容器直接使用目标容器的 IP 访问,默认通过容器内部的 eth0 发送出去;
- 报文通过 veth pair 被发送到 vethXXX;
- vethXXX 是直接连接到 cni0,报文通过虚拟 bridge cni0 发送出去;
- 查找路由表,外部容器 IP 的报文都会转发到 flannel.1 的虚拟网卡,这是一个 P2P 的虚拟网卡,然后报文就被转发到监听在另一端的 flanneld;
- flanneld 通过 etcd 维护了各个节点之间的路由表,把原来的报文 UDP 封装一层,通过配置的 iface 发送出去;
- 报文通过主机之间的网络栈找到目标主机;
- 报文继续往上送,到达传输层,交给监听的 flanneld 程序处理;
- 数据被解包,然后发送给 flannel.1 虚拟网卡;
- 查找路由表,发现对应容器的报文要交给 cni0;
- cni0 连接到自己的容器,把报文发送过去。
我们使用 kubectl apply 安装的 flannel 默认的 backend 为 vxlan,host-gw 是 flannel 的另一个 backend,我们将前面的 vxlan backend 切换成 host-gw。
与 vxlan 不同,host-gw 不会封装数据包,而是在主机的路由表中创建到其他主机 subnet 的路由条目,从而实现容器跨主机通信。要使用 host-gw 首先修改 flannel 的配置 flannel-config.json:
kubectl edit cm kube-flannel-cfg -o yaml -n kube-system找到如下字段进行修改。
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "host-gw"
}
}
host-gw 把每个主机都配置成网关,主机知道其他主机的 subnet 和转发地址,由于 vxlan 需要对数据包进行额外的打包和拆包,性能会比 vxlan 强一些。
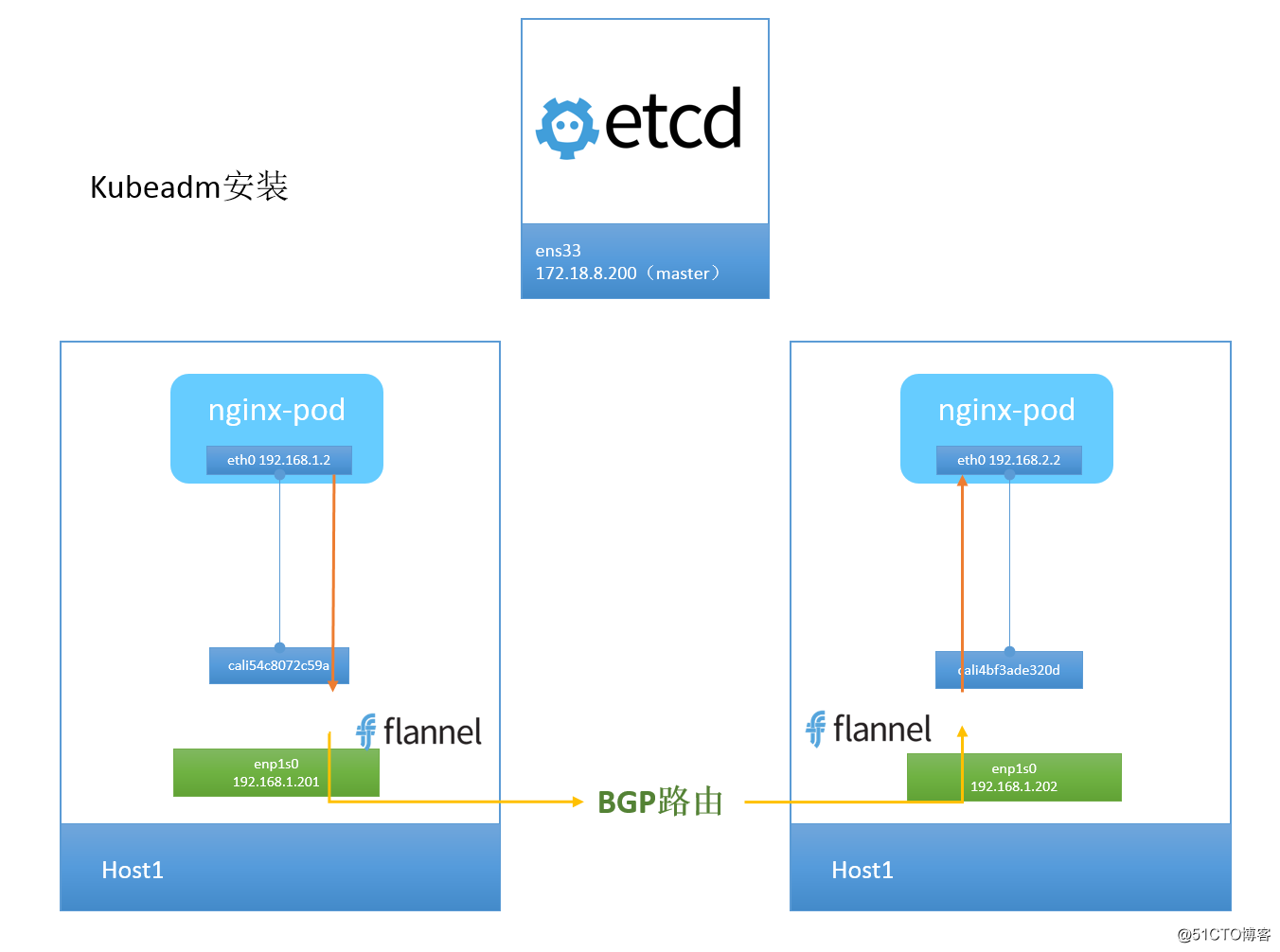
3.2、Calico 网络方案
Calico 把每个操作系统的协议栈当做一个路由器,然后认为所有的容器是连在这个路由器上的网络终端,在路由器之间运行标准的路由协议——BGP,然后让他们自己去学习这个网络拓扑该如何转发,所以Calico 是一个纯三层的虚拟网络方案,Calico 为每个容器分配一个 IP,每个 host 都是 router,把不同 host 的容器连接起来。与 VxLAN 不同的是,Calico 不对数据包做额外封装,不需要 NAT 和端口映射,扩展性和性能都很好。
与其他容器网络方案相比,Calico 还有一大优势:network policy。用户可以动态定义 ACL 规则,控制进出容器的数据包,实现业务需求。
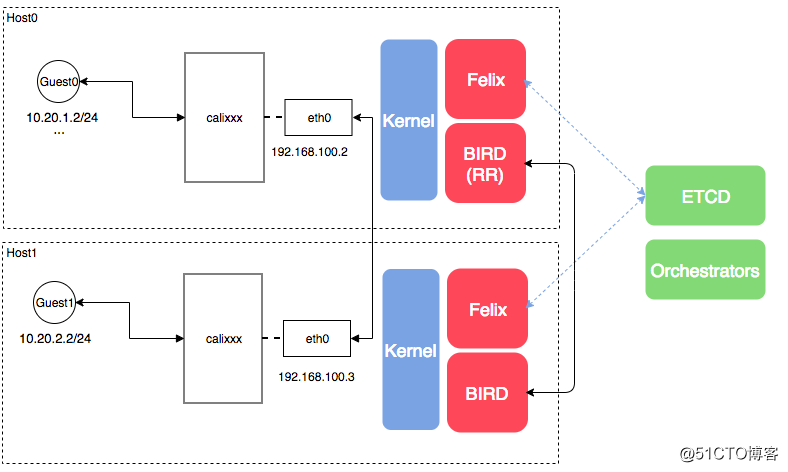
- Felix:运行在每一台 Host 的 agent 进程,主要负责网络接口管理和监听、路由、ARP 管理、ACL 管理和同步、状态上报等;
- Orchestrator Plugin:编排插件,并不是独立运行的某些进程,而是设计与 k8s、OpenStack 等平台集成的插件,如 Neutron’s ML2 plugin 用于用户使用 Neutron API 来管理 Calico,本质是要解决模型和 API 间的兼容性问题;
- Etcd:Calico 模型的存储引擎;
- BGP Client(BIRD):Calico 为每一台 Host 部署一个 BGP Client,使用 BIRD 实现,BIRD 是一个单独的持续发展的项目,实现了众多动态路由协议比如 BGP、OSPF、RIP 等。在 Calico 的角色是监听 Host 上由 Felix 注入的路由信息,然后通过 BGP 协议广播告诉剩余 Host 节点,从而实现网络互通;
- BGP Route Reflector(BIRD):在大型网络规模中,如果仅仅使用 BGP client 形成 mesh 全网互联的方案就会导致规模限制,因为所有节点之间俩俩互联,需要 N^2 个连接,为了解决这个规模问题,可以采用 BGP 的 Router Reflector 的方法,使所有 BGP Client 仅与特定 RR 节点互联并做路由同步,从而大大减少连接数。
3.3 Docker overlay 网络方案
请查看我的博文 http://blog.51cto.com/wzlinux/2112061 。
3.4、Docker macvlan 网络方案
macvlan 本身是 linxu kernel 模块,其功能是允许在同一个物理网卡上配置多个 MAC 地址,即多个 interface,每个 interface 可以配置自己的 IP。macvlan 本质上是一种网卡虚拟化技术,Docker 用 macvlan 实现容器网络就不奇怪了。
macvlan 的最大优点是性能极好,相比其他实现,macvlan 不需要创建 Linux bridge,而是直接通过以太 interface 连接到物理网络。
macvlan 会独占主机的网卡,也就是说一个网卡只能创建一个 macvlan 网络:
但主机的网卡数量是有限的,如何支持更多的 macvlan 网络呢?
好在 macvlan 不仅可以连接到 interface(如 enp0s9),也可以连接到 sub-interface(如 enp0s9.xxx)。
VLAN 是现代网络常用的网络虚拟化技术,它可以将物理的二层网络划分成多达 4094 个逻辑网络,这些逻辑网络在二层上是隔离的,每个逻辑网络(即 VLAN)由 VLAN ID 区分,VLAN ID 的取值为 1-4094。
Linux 的网卡也能支持 VLAN(apt-get install vlan),同一个 interface 可以收发多个 VLAN 的数据包,不过前提是要创建 VLAN 的 sub-interface。
比如希望 enp0s9 同时支持 VLAN10 和 VLAN20,则需创建 sub-interface enp0s9.10 和 enp0s9.20。
在交换机上,如果某个 port 只能收发单个 VLAN 的数据,该 port 为 Access 模式,如果支持多 VLAN,则为 Trunk 模式,所以接下来实验的前提是:
enp0s9 要接在交换机的 trunk 口上。不过我们用的是 VirtualBox 虚拟机,则不需要额外配置了。


















 1969
1969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









