






 本文详细介绍了ReLU及其变体LeakyReLU、ParametricReLU和RandomizedReLU的功能特性,并深入探讨了ExponentialLinearUnit (ELU)及ScaledELU的工作原理。特别地,文章分析了ScaledELU如何通过特定参数设置使输出数据保持均值为0、方差为1的状态,从而实现类似Batch Normalization的效果,并展示了在某些情况下,使用Scaled Exponential Linear Units (SELU)的神经网络相较于使用Batch Normalization的优势。
本文详细介绍了ReLU及其变体LeakyReLU、ParametricReLU和RandomizedReLU的功能特性,并深入探讨了ExponentialLinearUnit (ELU)及ScaledELU的工作原理。特别地,文章分析了ScaledELU如何通过特定参数设置使输出数据保持均值为0、方差为1的状态,从而实现类似Batch Normalization的效果,并展示了在某些情况下,使用Scaled Exponential Linear Units (SELU)的神经网络相较于使用Batch Normalization的优势。
https://www.bilibili.com/video/av9770302/?p=11
Relu

Leaky Relu
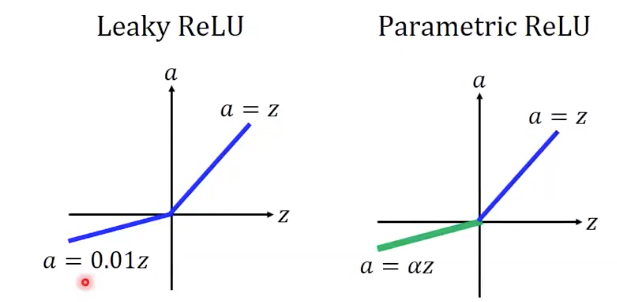
Parametric Relu就是把leaky部分的斜率学出来,而不是指定
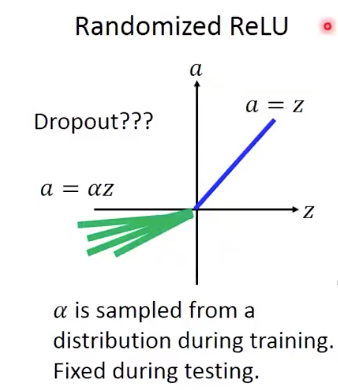
还有一种变体是,Randomized Relu,就是说这个斜率是每次随机的
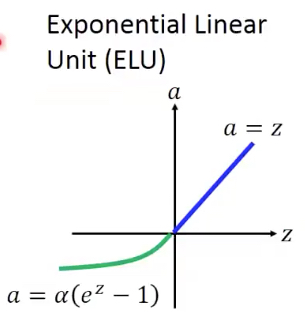
Exponential Linear Unit (ELU)
Scaled ELU
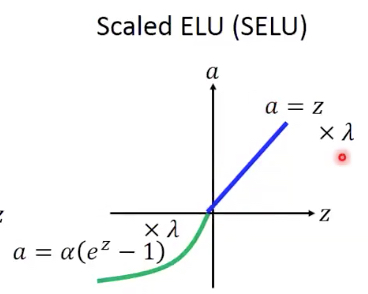
Scaled就是都乘上一个lamda
并且这里给出了alpha和lamda的取值,

这个是推导出来的
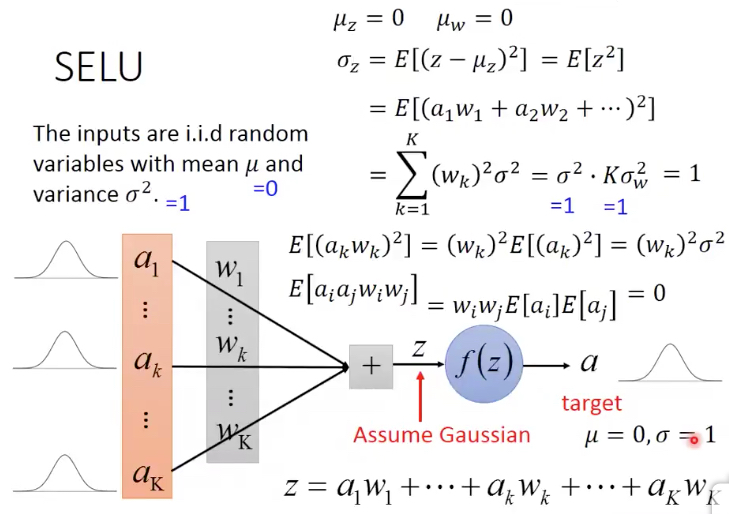
这里如果我们假设所有输入的a的分布为,mean=0, variance=1
所有参数w的分为也是,mean=0, variance=1/K (这个取值上面算出来的,为了保证z的variance为1)
就能得到z的分布也符合mean=0,variance=1
虽然这里对于a1...aK的分布没有假设,但是我们可以假设z的分布式是符合高斯分布的,根据中心极限定理
现在的问题是对于z经过SELU得到a,如果还要保证mean=0,variance=1,求alpha,lamda参数,求出来的值就是上面给出的
看这个推导有两个用处,
1. 知道使用Selu的前提假设,是有假设的,视频里面demo,在不满足假设的情况下,Selu没效果的
假设就是输入和参数的初始化必须要满足前面的分布假设
这里参数的初始化可以用lecun_normal,虽然参数后面会不断调整,但初始化还是很关键
2. 可以看出SELU让输出的分布满足mean=0, variance=1,这就可以达到BathNormalization的效果
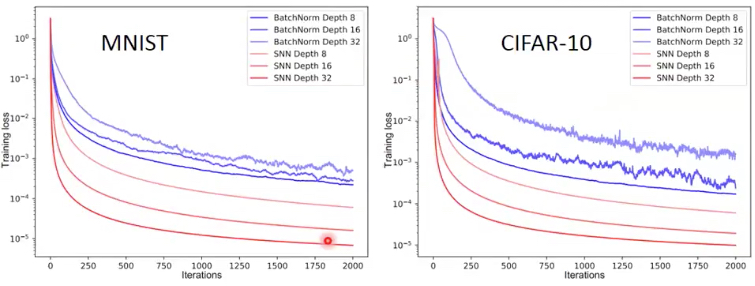
可以看到作者的比较,SELU NN比用BatchNorm的效果要好,loss更低,而且也更平滑
因为BatchNorm,每次是用batch的mean和var,所以用局部代表全局,会有波动,因为每个batch可能有较大的差异


















 374
374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









