






一、概念认识
1、常用的Analyer
SimpleAnalyzer、StopAnalyzer、WhitespaceAnalyzer、StandardAnalyzer
2、TokenStream
分词器做好处理之后得到的一个流,这个流中存储了分词的各种信息,可以通过TokenStream有效的获取到分词单元信息生成的流程
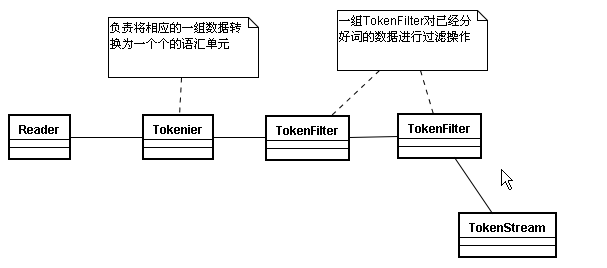
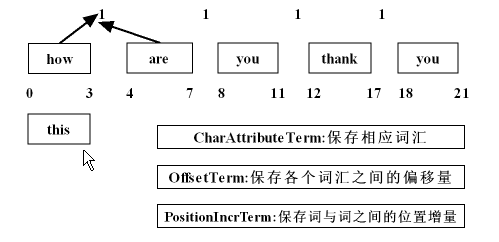
在这个流中所需要存储的数据
3、Tokenizer
主要负责接收字符流Reader,将Reader进行分词操作。有如下一些实现类

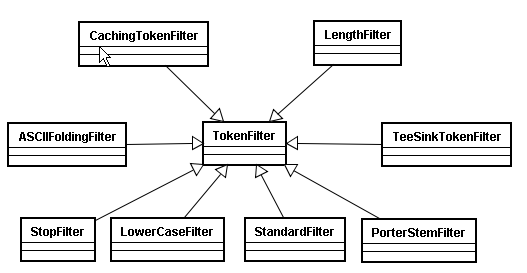
4、TokenFilter
将分词的语汇单元,进行各种各样过滤
5、内置常用分词器分词进行分词的差异
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public
static
void
displayToken(String str,Analyzer a) {
try
{
TokenStream stream = a.tokenStream(
"content"
,
new
StringReader(str));
//创建一个属性,这个属性会添加流中,随着这个TokenStream增加
CharTermAttribute cta = stream.addAttribute(CharTermAttribute.
class
);
while
(stream.incrementToken()) {
System.out.print(
"["
+cta+
"]"
);
}
System.out.println();
}
catch
(IOException e) {
e.printStackTrace();
}
}
|
|
1
2
3
4
5
6
7
8
9
|
public
Map<String,Analyzer> toMap(String[] str,Analyzer ... analyzers){
Map<String,Analyzer> analyzerMap =
new
HashMap<String,Analyzer>();
int
i =
0
;
for
(Analyzer a : analyzers){
analyzerMap.put(str[i], a);
i++;
}
return
analyzerMap;
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
@Test
public
void
test01() {
String[] str ={
"StandardAnalyzer"
,
"StopAnalyzer"
,
"SimpleAnalyzer"
,
"WhitespaceAnalyzer"
};
Map<String,Analyzer> analyzerMap =
new
HashMap<String,Analyzer>();
Analyzer a1 =
new
StandardAnalyzer(Version.LUCENE_35);
Analyzer a2 =
new
StopAnalyzer(Version.LUCENE_35);
Analyzer a3 =
new
SimpleAnalyzer(Version.LUCENE_35);
Analyzer a4 =
new
WhitespaceAnalyzer(Version.LUCENE_35);
analyzerMap = toMap(str,a1,a2,a3,a4);
String txt =
"this is my house,I am come from bilibili qiansongyi,"
+
"My email is dumingjun@gmail.com,My QQ is 888168"
;
for
(String analyzer : analyzerMap.keySet()){
System.out.println(analyzer);
AnalyzerUtils.displayToken(txt, analyzerMap.get(analyzer));
System.out.println(
"=============================="
);
}
}
|

6、中文分词
|
1
2
3
4
5
6
7
8
9
|
public
void
toMap(String txt,Analyzer ... analyzers){
for
(Analyzer a : analyzers){
int
start = a.toString().lastIndexOf(
"."
)+
1
;
int
end = a.toString().lastIndexOf(
"@"
)-
1
;
System.out.println(a.toString().substring(start, end));
AnalyzerUtils.displayToken(txt, a);
System.out.println(
"===================="
);
}
}
|
|
1
2
3
4
5
6
7
8
9
10
|
public
void
test02() {
Analyzer a1 =
new
StandardAnalyzer(Version.LUCENE_35);
Analyzer a2 =
new
StopAnalyzer(Version.LUCENE_35);
Analyzer a3 =
new
SimpleAnalyzer(Version.LUCENE_35);
Analyzer a4 =
new
WhitespaceAnalyzer(Version.LUCENE_35);
Analyzer a5 =
new
MMSegAnalyzer(
new
File(
"D:\\lucene\\mmseg4j\\data"
));
String txt =
"我来自中国广东省广州市天河区的小白"
;
toMap(txt,a1,a2,a3,a4,a5);
}
|

7、位置增量、位置偏移量、分词单元、分词器的类型
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public
static
void
displayAllTokenInfo(String str,Analyzer a) {
try
{
TokenStream stream = a.tokenStream(
"content"
,
new
StringReader(str));
//位置增量的属性,存储语汇单元之间的距离
PositionIncrementAttribute pia =
stream.addAttribute(PositionIncrementAttribute.
class
);
//每个语汇单元的位置偏移量
OffsetAttribute oa = stream.addAttribute(OffsetAttribute.
class
);
//存储每一个语汇单元的信息(分词单元信息)
CharTermAttribute cta = stream.addAttribute(CharTermAttribute.
class
);
//使用的分词器的类型信息
TypeAttribute ta = stream.addAttribute(TypeAttribute.
class
);
for
(;stream.incrementToken();) {
System.out.print(pia.getPositionIncrement()+
":"
);
System.out.print(cta+
"["
+oa.startOffset()+
"-"
+oa.endOffset()+
"]-->"
+ta.type()+
"\n"
);
}
}
catch
(Exception e) {
e.printStackTrace();
}
}
|

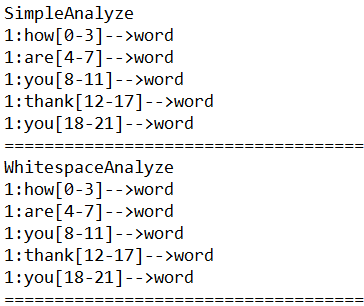
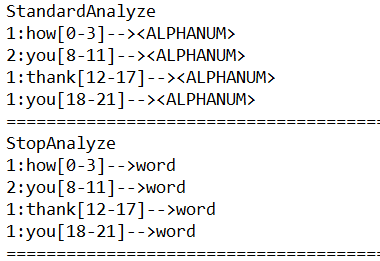
8、停用分词器
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public
class
MyStopAnalyzer
extends
Analyzer {
@SuppressWarnings
(
"rawtypes"
)
private
Set stops;
@SuppressWarnings
(
"unchecked"
)
public
MyStopAnalyzer(String[]sws) {
//会自动将字符串数组转换为Set
stops = StopFilter.makeStopSet(Version.LUCENE_35, sws,
true
);
//将原有的停用词加入到现在的停用词
stops.addAll(StopAnalyzer.ENGLISH_STOP_WORDS_SET);
}
public
MyStopAnalyzer() {
//获取原有的停用词
stops = StopAnalyzer.ENGLISH_STOP_WORDS_SET;
}
@Override
public
TokenStream tokenStream(String fieldName, Reader reader) {
//为这个分词器设定过滤链和Tokenizer
return
new
StopFilter(Version.LUCENE_35,
new
LowerCaseFilter(Version.LUCENE_35,
new
LetterTokenizer(Version.LUCENE_35,reader)), stops);
}
}
|
|
1
2
3
4
5
6
7
8
|
@Test
public
void
test04() {
Analyzer a1 =
new
MyStopAnalyzer(
new
String[]{
"I"
,
"you"
,
"hate"
});
Analyzer a2 =
new
MyStopAnalyzer();
String txt =
"how are you thank you I hate you"
;
AnalyzerUtils.displayToken(txt, a1);
AnalyzerUtils.displayToken(txt, a2);
}
|
9、简单实现同义词索引
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public
class
MySameAnalyzer
extends
Analyzer {
private
SamewordContext samewordContext;
public
MySameAnalyzer(SamewordContext swc) {
samewordContext = swc;
}
@Override
public
TokenStream tokenStream(String fieldName, Reader reader) {
Dictionary dic = Dictionary.getInstance(
"D:\\lucene\\mmseg4j\\data"
);
return
new
MySameTokenFilter(
new
MMSegTokenizer(
new
MaxWordSeg(dic), reader),samewordContext);
}
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
public
class
MySameTokenFilter
extends
TokenFilter {
private
CharTermAttribute cta =
null
;
private
PositionIncrementAttribute pia =
null
;
private
AttributeSource.State current;
private
Stack<String> sames =
null
;
private
SamewordContext samewordContext;
protected
MySameTokenFilter(TokenStream input,SamewordContext samewordContext) {
super
(input);
cta =
this
.addAttribute(CharTermAttribute.
class
);
pia =
this
.addAttribute(PositionIncrementAttribute.
class
);
sames =
new
Stack<String>();
this
.samewordContext = samewordContext;
}
@Override
public
boolean
incrementToken()
throws
IOException {
if
(sames.size()>
0
) {
//将元素出栈,并且获取这个同义词
String str = sames.pop();
//还原状态
restoreState(current);
cta.setEmpty();
cta.append(str);
//设置位置0
pia.setPositionIncrement(
0
);
return
true
;
}
if
(!
this
.input.incrementToken())
return
false
;
if
(addSames(cta.toString())) {
//如果有同义词将当前状态先保存
current = captureState();
}
return
true
;
}
private
boolean
addSames(String name) {
String[] sws = samewordContext.getSamewords(name);
if
(sws!=
null
) {
for
(String str:sws) {
sames.push(str);
}
return
true
;
}
return
false
;
}
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public
class
SimpleSamewordContext2
implements
SamewordContext {
Map<String,String[]> maps =
new
HashMap<String,String[]>();
public
SimpleSamewordContext2() {
maps.put(
"中国"
,
new
String[]{
"天朝"
,
"大陆"
});
}
@Override
public
String[] getSamewords(String name) {
return
maps.get(name);
}
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
@Test
public
void
test05() {
try
{
Analyzer a2 =
new
MySameAnalyzer(
new
SimpleSamewordContext2());
String txt =
"我来自中国广东省广州市天河区的小白"
;
Directory dir =
new
RAMDirectory();
IndexWriter writer =
new
IndexWriter(dir,
new
IndexWriterConfig(Version.LUCENE_35, a2));
Document doc =
new
Document();
doc.add(
new
Field(
"content"
,txt,Field.Store.YES,Field.Index.ANALYZED));
writer.addDocument(doc);
writer.close();
IndexSearcher searcher =
new
IndexSearcher(IndexReader.open(dir));
TopDocs tds = searcher.search(
new
TermQuery(
new
Term(
"content"
,
"咱"
)),
10
);
// Document d = searcher.doc(tds.scoreDocs[0].doc);
// System.out.println(d.get("content"));
AnalyzerUtils.displayAllTokenInfo(txt, a2);
}
catch
(CorruptIndexException e) {
e.printStackTrace();
}
catch
(LockObtainFailedException e) {
e.printStackTrace();
}
catch
(IOException e) {
e.printStackTrace();
}
}
|



















 231
231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









