



 本文介绍如何使用Scrapy框架结合spynner工具抓取上海证券交易所的A股列表数据,并存储到MySQL数据库。
本文介绍如何使用Scrapy框架结合spynner工具抓取上海证券交易所的A股列表数据,并存储到MySQL数据库。

软件环境
OS系统:win7 64bit 专业版
IDE:pycharm 社区版
Python:2.7.12
spynner:2.19
实验步骤:
新建爬虫工程
Microsoft Windows [版本 6.1.7601]
版权所有 (c) 2009 Microsoft Corporation。保留所有权利。
C:\Windows\System32>d:
D:\>cd Anaconda2-project
D:\Anaconda2-project>scrapy startproject StockBaseInfoSpider
创建成功后,用pycharm打开这个工程,类似这样的
编辑代码
编辑items.py,如下
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
from scrapy import Item, Field
class StockbaseinfospiderItem(Item):
# 公司代码
compCode = Field()
# 公司详情页url
compUrl = Field()
# 公司简称
compName = Field()
# 证券代码
securityCode = Field()
# 交易所代码
exchange = Field()
# 证券简称
securityName = Field()
# 上市日期
theDate = Field()
# 总股本
wholeCapital = Field()
# 流通股本
circulatingCapital = Field()
# 公司公告列表页url
announcementUrl = Field()
在 StockBaseInfoSpider目录下面创建Python package:dbservice,并在此目录下新建DbService.py文件,如下
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
class DbService(object):
def __init__(self):
# charset必须设置为utf8,而不能为utf-8
self.conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='111111', db='spiderdb', charset='utf8')
self.cursor = self.conn.cursor()
pass
def close(self):
if self.cursor:
self.cursor.close()
print '---> close cursor'
if self.conn:
self.conn.close()
print '---> close conn'
# 批量插入多个item
def process_items(self, items):
if items:
for item in items:
self.insertItem(item)
self.conn.commit()
else:
print '---> process_items error: items is None'
# 插入单个item
def process_item(self, item):
self.insertItem(item)
self.conn.commit()
# 没有加异常处理,请自行添加
# on duplicate key update 这个写法是以表中的唯一索引unique字段为主,去更新其他的字段,兼顾insert和update功能,即没有唯一索引对应的数据,就insert,有就update
def insertItem(self, item):
if item:
sql = "insert into spider_stock_base_info " \
"(comp_code, comp_url, comp_name, security_code, exchange, " \
"security_name, the_date, whole_capital, circulating_capital, " \
"announcement_url) " \
"values ('{0}', '{1}', '{2}', '{3}', '{4}', " \
"'{5}', '{6}', {7}, {8}, " \
"'{9}') " \
"on duplicate key update " \
"comp_code=values(comp_code), comp_url=values(comp_url), comp_name=values(comp_name), " \
"security_name=values(security_name), the_date=values(the_date), whole_capital=values(whole_capital), circulating_capital=values(circulating_capital), " \
"announcement_url=values(announcement_url) "
sql = sql.format(item['compCode'], item['compUrl'], item['compName'], item['securityCode'], item['exchange'],
item['securityName'], item['theDate'], item['wholeCapital'], item['circulatingCapital']
, item['announcementUrl'])
self.cursor.execute(sql)
print '---> insert ', item['securityCode'], item['exchange'], item['securityName'], 'success'
else:
print '---> error:item is None, do not insert!'
在spiders目录下面新建SHStockBaseInfoSpider.py文件,如下
# -*- coding: utf-8 -*-
# 上交所A股列表地址,页面是异步查询加载,不能用常规的爬虫方法
# http://www.sse.com.cn/assortment/stock/list/share/
from scrapy import Spider
from bs4 import BeautifulSoup
from StockBaseInfoSpider.items import StockbaseinfospiderItem
import spynner
import pyquery
from StockBaseInfoSpider.dbservice.DbService import DbService
class SHStockBaseInfoSpider(Spider):
name = "StockBaseInfoSpider"
allowed_domains = []
start_urls = [
'http://www.sse.com.cn/assortment/stock/list/share/'
]
download_delay = 1
exchange = 'SH'
dbService = DbService()
# 这个地方没有直接解析response,而是用browser重新加载了当前的self.start_urls[0],这个parse方法只是一个爬虫的入口,具体实现在里面
def parse(self, response):
browser = spynner.Browser()
browser.create_webview()
browser.set_html_parser(pyquery.PyQuery)
browser.load(self.start_urls[0], 20)
# 第一次设置为1,是为了加载第一页数据后不触发下一页button的click事件
self.browserRequest(browser, 1)
# 分页请求
def browserRequest(self, browser, nextClick=None):
print "nextClick:", nextClick
# nextClick != undefined表示还有下一页数据
if nextClick != 'undefined':
# nextClick != 1,说明是第一次爬取,不需要触发下一页button的click事件
if nextClick != 1:
# 触发下一页button的click事件
browser.click("button[class='btn btn-default navbar-btn next-page classPage']")
try:
# 等待5秒钟,待页面渲染完毕,有可能5秒钟还不够,需要测试,有可能5秒钟太长
browser.wait_load(5)
except:
print '我也不知道是什么异常,反正不影响运行就行'
# 解析html页面,提取需要的数据
self.parseData(browser)
# else分支,nextClick == 'undefined',说明没有数据可爬取,关闭数据库连接
else:
self.dbService.close()
print 'Done'
# 解析html页面上的数据
def parseData(self, browser):
# 完整的html页面字符串
body = str(browser.html)
# 使用美丽汤BeautifulSoup工具解析提取数据
soup = BeautifulSoup(body, 'html.parser')
# 下面注释的代码可以将html字符串保存为一个html文件,供分析使用
# with open('stock_info.html', 'w') as f:
# f.write(soup.prettify())
# 找到页面上主要的数据区域,表格区域
js_tableT01 = soup.find('div', 'tab-pane active js_tableT01')
# 获取数据表格
tdclickable = js_tableT01.find('div', 'table-responsive sse_table_T01 tdclickable')
# 获取分页
pagetable = js_tableT01.find('div', 'page-con-table')
# 获取表格中的tbody
tbody = tdclickable.find('tbody')
# 获取tbody中的tr
trs = tbody.find_all('tr')
items = []
# 遍历tr
for tr in trs:
# 每个tr中的td
tds = tr.find_all('td')
# 遍历td
if tds:
tda = tds[0].find('a')
compCode = tda.get_text().strip()
compUrl = 'http://www.sse.com.cn' + tda['href']
compName = tds[1].get_text().strip()
securityCode = tds[2].get_text().strip()
securityName = tds[3].get_text().strip()
theDate = tds[4].get_text().strip()
wholeCapital = tds[5].get_text().strip()
circulatingCapital = tds[6].get_text().strip()
announcementUrl = 'http://www.sse.com.cn' + tds[7].find('a')['href'].strip()
item = StockbaseinfospiderItem()
item['compCode'] = compCode
item['compUrl'] = compUrl
item['compName'] = compName
item['securityCode'] = securityCode
item['exchange'] = self.exchange
item['securityName'] = securityName
# 测试发现有些时间数据为-,导致插入数据库异常
if theDate == '-':
theDate = '1970-01-01'
item['theDate'] = theDate
item['wholeCapital'] = wholeCapital
item['circulatingCapital'] = circulatingCapital
item['announcementUrl'] = announcementUrl
items.append(item)
# 批量插入数据库
self.dbService.process_items(items)
# 获取分页的button
buttons = pagetable.find('div', 'visible-xs mobile-page').find_all('button')
# 下一页的页码
nextPageNum = 'undefined'
if buttons and len(buttons) == 2:
nextPageNum = buttons[1]['page']
else:
nextPageNum = 'undefined'
# 由于页面是异步加载,无刷新分页,所以只能使用spynner触发下一页button的click事件,等待页面加载完毕,继续解析,下面是触发下一次分页操作
self.browserRequest(browser, nextPageNum)在StockBaseInfoSpider目录下面新建run.py文件,如下
# -*- coding: utf-8 -*-
from scrapy import cmdline
cmdline.execute('scrapy crawl StockBaseInfoSpider'.split())新建数据库和表
在本地MySQL服务器上新建数据库spiderdb,在spiderdb上新建表spider_stock_base_info,建表语句如下
CREATE TABLE `spider_stock_base_info` (
`id` INT(11) NOT NULL AUTO_INCREMENT COMMENT '主键自增',
`comp_code` VARCHAR(10) NULL DEFAULT NULL COMMENT '公司代码',
`comp_url` VARCHAR(1000) NULL DEFAULT NULL COMMENT '公司介绍url',
`comp_name` VARCHAR(100) NULL DEFAULT NULL COMMENT '公司名称',
`security_code` VARCHAR(10) NULL DEFAULT NULL COMMENT '证券代码',
`exchange` VARCHAR(10) NULL DEFAULT NULL COMMENT '交易所代码',
`security_name` VARCHAR(100) NULL DEFAULT NULL COMMENT '证券名称',
`the_date` DATE NULL DEFAULT NULL COMMENT '上市时间',
`whole_capital` DECIMAL(10,2) NULL DEFAULT NULL COMMENT '总股本',
`circulating_capital` DECIMAL(10,2) NULL DEFAULT NULL COMMENT '流通股本',
`announcement_url` VARCHAR(1000) NULL DEFAULT NULL COMMENT '公告列表url',
`auto_time` TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '自动时间戳',
PRIMARY KEY (`id`),
UNIQUE INDEX `security_code` (`security_code`, `exchange`),
INDEX `auto_time` (`auto_time`)
)
COMMENT='股票基本信息表'
COLLATE='utf8_general_ci'
ENGINE=InnoDB
;
测试代码和数据
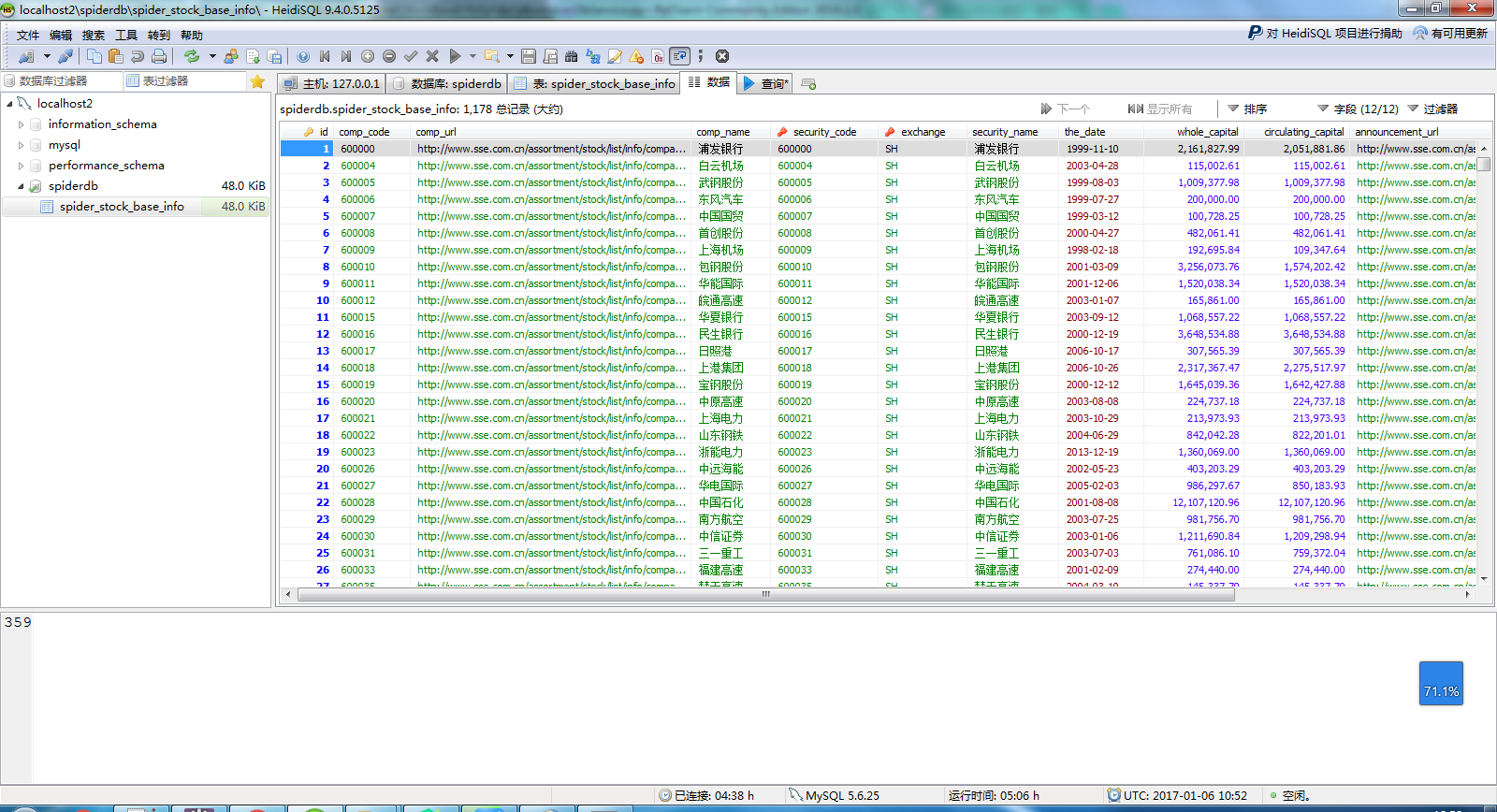
在run.py文件上点右键Run运行,查看控制台打印的日志,查看数据库表中的数据,实验成功。
MySQL中保存的数据,如下图
工程源码地址:https://github.com/listen-zhou/StockBaseInfoSpider
由于pycharm无法提交代码到码云,只能提交到github上,源码中有很详细的注释,有不明白的再回帖问我。
遇到的问题及解决方式
1.无刷新异步加载数据,无法通过分页按钮url爬取
上证交易所网站的A股列表页分页是用的异步加载刷新,无法使用常规的爬虫方式获取数据,特别是分页数据。
解决方案:使用spynner工具模拟一个无头的浏览器访问,并模拟鼠标的点击分页按钮事件,实现分页功能,并获取分页的数据,由于无法使用yield Request的方式执行下一页数据的加载,所以只能在一个parse方法里面处理所有的爬虫请求。
2.spynner获取的网页中文乱码
解决方案:经多方查找,终于在一篇博客中发现解决方法
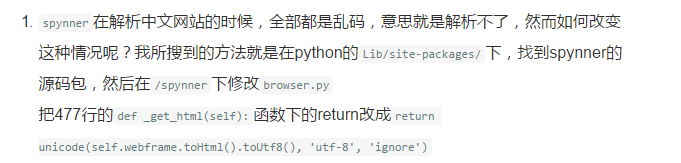
需要将安装的spynner卸载并删除干净,然后从https://pypi.python.org/pypi/spynner下载最新版本的zip包,解压,并按上图中的修改方式修改源码,然后使用Python编译安装,至此spynner安装完毕,就可以重新测试,会发现中文乱码没有了。
3.MySQL数据库插入时中文乱码
解决方案:需要将连接的参数charset设置为utf8,设置为utf-8不行。

















 484
484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









