 深度学习中的向量化技巧
深度学习中的向量化技巧







- http://mooc.study.163.com/learn/deeplearning_ai-2001281002?tid=2001392029#/learn/content?type=detail&id=2001701013&cid=2001694016
- 向量化是消除代码中显示for循环语句的艺术
- 在深度学习安全领域,深度学习、练习中,你经常发现在训练大数据集的时候,深度学习算法才会表现的更加优越,所以代码运行的非常快非常重要,否则,如果它运行在一个大的数据集上面,代码可能会话很长的时间来运行,需要等待非常长的时间才能得到结果,
- 所以在深度学习领域,可以去完成一个向量化以及变成一个关键的技巧
- 什么是向量化?
- 在logistic回归中,我们需要去计算
 ,其中w是列向量,x也是列向量,如果有很多的特征,他们就是非常大的向量,所以w和x都是R内的nx维度的向量,
,其中w是列向量,x也是列向量,如果有很多的特征,他们就是非常大的向量,所以w和x都是R内的nx维度的向量, - 所以去计算w'x,
- 如果有一个非向量化的实现,
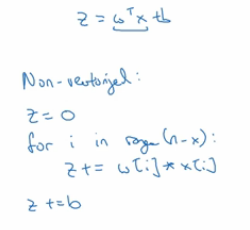
- 这个计算结果将会非常的慢
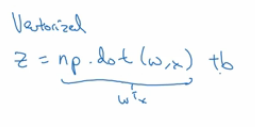
- 作为对比,如果有一个向量化的实现,将会非常直接的计算w^TX
- 在python或者numpy中,需要使用命令z=np.dot(w,x),这是在计算w^T*X,后面直接加上b,我们将会发现这个计算将会非常的快,
- 如果有一个非向量化的实现,
- 使用一个小的例子进行说明
- 向量化实现的矩阵计算
- for循环实现的矩阵计算
- 经过对比之后将会发现,向量化和非向量化之间会有非常大的区别(能接近300倍)
- 在logistic回归中,我们需要去计算
- 扩展深度学习实现是在GPU上做的,GPU也叫做图像处理单元,
- CPU和GPU都有并行化的指令,有时候会叫做SIMD指令,意思就是单指令流多数据,
 这句话的意思是如果你使用np.function(),它能让你去掉显式for循环的函数,这样numpy和python就能够充分利用并行化,去更快的计算
这句话的意思是如果你使用np.function(),它能让你去掉显式for循环的函数,这样numpy和python就能够充分利用并行化,去更快的计算- 这一点对 CPU和GPU上面都是有效成立的,
- GPU更擅长SIMD计算,CPU事实上也不是很差,可能并没有GPU擅长,
- 我们知道了向量化能够加快代码的执行, 经验法则是,只要有其他可能,就不要使用显式for循环,

















 3532
3532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









