







1. Hive开发
1.1. Hive安装部署
1.1.1. Hive概述
Hive是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive定义了简单的类SQL查询语言,称为HQL,它允许熟悉SQL的用户查询数据。同时,这个语言也允许熟悉MapReduce开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作。
Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
Hive的表其实就是HDFS的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
1.1.2. Hive体系结构
Hive的体系结构如下图所示:
图 1 Hive体系结构
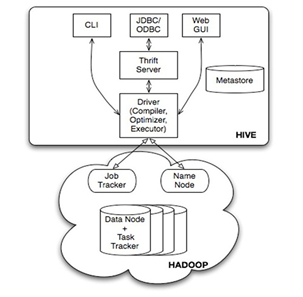
如图所示,用户接口,包括 CLI,JDBC/ODBC,WebUI:
- CLI,即Shell命令行
- JDBC/ODBC 是 Hive 的Java,与使用传统数据库JDBC的方式类似
- WebGUI是通过浏览器访问 Hive
Hive的元数据存储通常是存储在关系数据库如 mysql, derby 中,用 HDFS 进行存储利用 MapReduce 进行计算,Hive包括解释器、编译器、优化器、执行器四个部分。
Hive 将元数据存储在数据库中(metastore),目前只支持 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务)。
下图对Hive和传统关系数据库进行对比:
图 2 Hive与传统关系数据库的对比

1.1.3. Hive安装
具体安装步骤如下所示:
- 在有hadoop环境的client机器上解压缩hive-0.9.0-bin.tar.gz包,并重命名为hive;
- 打开hive/conf下的配置文件:
- #cp hive-default.xml.template hive-default.xml
- #cp hive-default.xml hive-site.xml
- #cp hive-env.sh.template hive-env.sh
- 然后在hive-env.sh配置HADOOP_HOME
- 配置环境变量HIVE_HOME和PATH
最好配置一下jvm堆大小,否则使用jdbc服务的时候很容易内存溢出
安装后进行验证,查看命令行工具是否可用:
#hive --service cli
进入后查看数据库:
hive>show databases;
如果可以正常运行则安装成功。
可以开启hive web界面, 端口号9999:
#hive --service hwi &
用于通过浏览器来访问http://hadoop0:9999/hwi/
启动hive 远程服务 (端口号10000),该服务可以使用java通过jdbc协议访问,运行命令如下:
#hive --service hiveserver &
1.2. Hive开发
1.2.1. Hive的数据类型
Hive的数据类型分为原生和复合两种数据类型,其中原生数据类型有:
- TINYINT
- SMALLINT
- INT
- BIGINT
- BOOLEAN
- FLOAT
- DOUBLE
- STRING
BINARY (Hive 0.8.0以上才可用)
TIMESTAMP (Hive 0.8.0以上才可用)
复合数据类型有:
- arrays: ARRAY<data_type>
- maps: MAP<primitive_type, data_type>
- structs: STRUCT<col_name : data_type [COMMENT col_comment], ...>
- union: UNIONTYPE<data_type, data_type, ...>
1.2.2. Hive的数据存储
Hive的数据存储基于Hadoop HDFS,Hive没有专门的数据存储格式,存储结构主要包括:数据库、文件、表、视图。
创建表时,指定Hive数据的列分隔符与行分隔符即可解析数据。
Hive默认可以直接加载文本文件(TextFile),还支持sequence file,另外还支持一种特殊格式RCFile。
RCFile存储的表是水平划分的,分为多个行组, 每个行组再被垂直划分, 以便每列单独存储,在每个行组中利用一个列维度的数据压缩,并提供一种Lazy解压(decompression)技术来在查询执行时避免不必要的列解压;
RCFile支持弹性的行组大小,行组大小需要权衡数据压缩性能和查询性能两方面,具体结构如下图所示:
图 3 RCFile
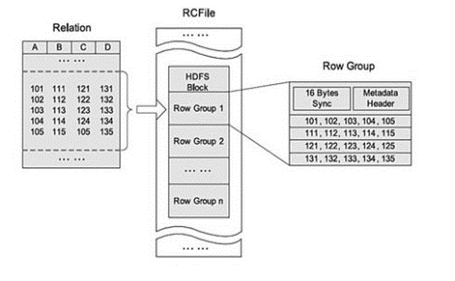
RCFile创建语法如下:
- CREATE TABLE fc_rc_test ( datatime string, section string, domain string, province string, city string, idc string, ext string, ip string, file_size string, down_sudo string)STORED AS RCFILE ;
因rcfile 格式的表的数据必须要从textfile 文件格式表通过 insert 操作才能完成,故先要创建textfile 的表。可以采用外部表的形式导入数据:
- CREATE TABLE fc_rc_ext ( datatime string,section string,domain string,province string, city string,idc string,ext string,ip string,file_size string, down_sudo string)ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"STORED AS textfileLOCATION '/user/hive/warehouse/log/fc';
导入rcfile 格式的数据:
- insert overwrite table fc_rc_test select * from fc_rc_ext ;
1.2.3. Hive的数据模型
数据库,类似传统数据库的DataBase,默认数据库"default“。使用#hive命令后,不使用:
- hive]]>use <数据库名]]>
系统默认的数据库。可以显式使用
- hive]]> use default;
创建一个新库
- hive ]]> create database test_dw;
Hive对表的操作语句类似于mysql的语法:
- SHOW TABLES; # 查看所有的表
- SHOW TABLES '*TMP*'; #支持模糊查询
- DESCRIBE TMP_TABLE; #查看表结构
表分为以下四种类型:
- Table 内部表
与数据库中的 Table 在概念上是类似,每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 test,它在 HDFS 中的路径为:/ warehouse/test。 warehouse是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的数据仓库的目录,所有的 Table 数据(不包括 External Table)都保存在这个目录中。
删除表时,元数据与数据都会被删除。
创建表:
- hive]]>create table inner_table (key string);
加载数据:
- hive]]>load data local inpath '/root/inner_table.dat' into table inner_table;
当数据被加载至表中时,不会对数据进行任何转换。Load 操作只是将数据复制/移动至 Hive 表对应的位置。
- LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
把一个Hive表导入到另一个已建Hive表
- INSERT OVERWRITE TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement FROM from_statement
- Create Table As Select(CTAS)
- CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
- (col_name data_type, ...) …
- AS SELECT …
例:
- create table new_external_test as select * from external_table1;
查看数据:
- select * from inner_table
- select count(*) from inner_table
删除表:
- drop table inner_table
- Partition 分区表
Partition 对应于数据库的 Partition 列的密集索引,在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中,例如:test表中包含 date 和 city 两个 Partition,则对应于date=20130201, city = bj 的 HDFS 子目录为:
- /warehouse/test/date=20130201/city=bj
对应于date=20130202, city=sh 的HDFS 子目录为;
- /warehouse/test/date=20130202/city=sh
创建表:
- create table partition_table(rectime string,msisdn string) partitioned by(daytime string,city string) row format delimited fields terminated by '\t' stored as TEXTFILE;
加载数据到分区
- load data local inpath '/home/partition_table.dat' into table partition_table partition (daytime='2013-02-01',city='bj');
查看数据
- select * from partition_table
- select count(*) from partition_table
删除表
- drop table partition_table
扩展分区:
- alter table partition_table
- add partition (daytime='2013-02-04',city='bj');
删除分区:
- alter table partition_table
- drop partition (daytime='2013-02-04',city='bj')
元数据,数据文件删除,但目录daytime=2013-02-04还在。
其他一下命令:
- SHOW PARTITIONS TMP_TABLE; #查看表有哪些分区
- Bucket Table 桶表
桶表是对数据进行哈希取值,然后放到不同文件中存储。
创建表
- create table bucket_table(id string) clustered by(id) into 4 buckets;
加载数据
set hive.enforce.bucketing = true;可以自动控制上一轮reduce的数量从而适配bucket的个数,当然,用户也可以自主设置mapred.reduce.tasks去适配bucket 个数,推荐使用'set hive.enforce.bucketing = true'
- insert into table bucket_table select name from stu;
- insert overwrite table bucket_table select name from stu;
数据加载到桶表时,会对字段取hash值,然后与桶的数量取模(hash mod分片)。把数据放到对应的文件中。
抽样查询:
- select * from bucket_table tablesample(bucket 1 out of 4 on id);
语法:
- TABLESAMPLE(BUCKET x OUT OF y)
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了64份,当y=32时,抽取 (64/32=)2个bucket的数据,当y=128时,抽取(64/128=)1/2个bucket的数据。x表示从哪个bucket开始抽取。例 如,table总bucket数为32,tablesample(bucket 3 out of 16),表示总共抽取(32/16=)2个bucket的数据,分别为第3个bucket和第(3+16=)19个bucket的数据。
- External Table 外部表
指向已经在HDFS中存在的数据,可以创建Partition,它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异:
内部表 的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除
外部表只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个外部表时,仅删除该链接。
创建表
- hive]]>create external table external_table1 (key string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' location '/home/external';
在HDFS创建目录/home/external
- #hadoop fs -put /home/external_table.dat /home/external
加载数据
- LOAD DATA INPATH '/home/external_table1.dat' INTO TABLE external_table1;
查看数据
- select * from external_table
- select count(*) from external_table
删除表
- drop table external_table
除表外,Hive也有视图,创建视图的代码如下:
- CREATE VIEW v1 AS select * from t1;
1.2.4. Hive的查询
Hive的查询语法如下:
- SELECT [ALL | DISTINCT] select_expr, select_expr, ...
- FROM table_reference
- [WHERE where_condition]
- [GROUP BY col_list]
- [ CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] | [ORDER BY col_list] ]
- [LIMIT number]
语法与mysql基本类似,值得注意的是DISTRIBUTE BY,这个参数实质是指定分发器(Partitioner),终究Hive最终实现还是MapReduce。
对于分区表,可以基于Partition的查询,一般 SELECT 查询是全表扫描。但如果是分区表,查询就可以利用分区剪枝(input pruning)的特性,类似“分区索引“”,只扫描一个表中它关心的那一部分。Hive 当前的实现是,只有分区断言(Partitioned by)出现在离 FROM 子句最近的那个WHERE 子句中,才会启用分区剪枝。例如,如果 page_views 表(按天分区)使用 date 列分区,以下语句只会读取分区为‘2008-03-01’的数据。
- SELECT page_views.* FROM page_views WHERE page_views.date >= '2013-03-01' AND page_views.date <= '2013-03-01'
Limit 可以限制查询的记录数。查询的结果是随机选择的。下面的查询语句从 t1 表中随机查询5条记录:
- SELECT * FROM t1 LIMIT 5
Top N查询,下面的查询语句查询销售记录最大的 5 个销售代表。
- SET mapred.reduce.tasks = 1 #该设置在MapReduce课程中也看到过,因此执行Hive必须要有MapReduce的基础。
- SELECT * FROM sales SORT BY amount DESC LIMIT 5
表连接查询相关操作如下:
内连接
- select b.name,a.* from dim_ac a join acinfo b on (a.ac=b.acip) limit 10;
左外连接
- select b.name,a.* from dim_ac a left outer join acinfo b on a.ac=b.acip limit 10;
具体链接的含义在mysql阶段已经很明确,此处不做解释。
1.2.5. JDBC
Hive可以通过java的jdbc协议调用,但是事实上这个操作意义并不是很大,除非我们要一个数据分析的web应用,终究联机分析和联机事务处理还是有区别的(性能就是最大的区别)。
要进行JDBC链接首先需要将Hive远程服务启动:
- #hive --service hiveserver ]]>/dev/null 2]]>/dev/null &
JAVA客户端相关代码
- Class.forName("org.apache.hadoop.hive.jdbc.HiveDriver");
- Connection con = DriverManager.getConnection("jdbc:hive://master:10000/wlan_dw", "", "");
- Statement stmt = con.createStatement();
- String querySQL="SELECT * FROM wlan_dw.dim_m order by flux desc limit 10";
- ResultSet res = stmt.executeQuery(querySQL);
- while (res.next()) {
- System.out.println(res.getString(1) +"\t" +res.getLong(2)+"\t" +res.getLong(3)+"\t" +res.getLong(4)+"\t" +res.getLong(5));
- }
1.3. UDF
1.3.1. UDF概述
Hive可以允许用户编写自己定义的函数UDF,来在查询中使用。Hive中有3种UDF:
- UDF:操作单个数据行,产生单个数据行;
- UDAF:操作多个数据行,产生一个数据行。
- UDTF:操作一个数据行,产生多个数据行一个表作为输出。
1.3.2. UDF
用户构建的UDF使用过程如下:
第一步:继承UDF或者UDAF或者UDTF,实现特定的方法。
第二步:将写好的类打包为jar。如hivefirst.jar.
第三步:进入到Hive外壳环境中,利用add jar /home/hadoop/hivefirst.jar.注册该jar文件
第四步:为该类起一个别名,create temporary function mylength as 'com.whut.StringLength';这里注意UDF只是为这个Hive会话临时定义的。
第五步:在select中使用mylength();
具体参考本课程代码中的实例。
1.3.3. UDAF
用户的UDAF必须继承了org.apache.hadoop.hive.ql.exec.UDAF;
用户的UDAF必须包含至少一个实现了org.apache.hadoop.hive.ql.exec的静态类,诸如常见的实现了 UDAFEvaluator。
一个计算函数必须实现的5个方法的具体含义如下:
init():主要是负责初始化计算函数并且重设其内部状态,一般就是重设其内部字段。一般在静态类中定义一个内部字段来存放最终的结果。
iterate():每一次对一个新值进行聚集计算时候都会调用该方法,计算函数会根据聚集计算结果更新内部状态。当输入值合法或者正确计算了,则就返回true。
terminatePartial():Hive需要部分聚集结果的时候会调用该方法,必须要返回一个封装了聚集计算当前状态的对象。
merge():Hive进行合并一个部分聚集和另一个部分聚集的时候会调用该方法。
terminate():Hive最终聚集结果的时候就会调用该方法。计算函数需要把状态作为一个值返回给用户。
部分聚集结果的数据类型和最终结果的数据类型可以不同。
1.3.4. UDTF
UDTF(User-Defined Table-Generating Functions) 用来解决 输入一行输出多行(On-to-many maping) 的需求。
编写自己需要的UDTF继承
- org.apache.hadoop.hive.ql.udf.generic.GenericUDTF
实现initialize, process, close三个方法
UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型)。初始化完成后,会调用process方法,对传入的参数进行处理,可以通过forword()方法把结果返回。最后close()方法调用,对需要清理的方法进行清理。
UDTF有两种使用方法,一种直接放到select后面,一种和lateral view一起使用。
- 直接select中使用:
- select explode_map(properties) as (col1,col2) from src;
不可以添加其他字段使用:
- select a, explode_map(properties) as (col1,col2) from src
不可以嵌套调用:
- select explode_map(explode_map(properties)) from src
不可以和group by/cluster by/distribute by/sort by一起使用:
- select explode_map(properties) as (col1,col2) from src group by col1, col2
- 和lateral view一起使用:
- select src.id, mytable.col1, mytable.col2 from src lateral view explode_map(properties) mytable as col1, col2;
lateral view用于和split, explode等UDTF一起使用,它能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。lateral view首先为原始表的每行调用UDTF,UTDF会把一行拆分成一或者多行,lateral view再把结果组合,产生一个支持别名表的虚拟表。
- LATERAL VIEW udtf(expression) tableAlias AS columnAlias
其中 columnAlias是多个用’,’分割的虚拟列名,这些列名从属于表tableAlias
2. 传统开源ETL工具KETTLE使用
2.1. Kettle使用
2.1.1. Kettle概述
ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于金融IT来说,经常会遇到大数据量的处理,转换,迁移,所以了解并掌握一种etl工具的使用,必不可少。
Kettle是一款国外开源的etl工具,纯java编写,绿色无需安装,数据抽取高效稳定。Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
Kettle可以在http://kettle.pentaho.org/网站下载,下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可(目前最高版本已经不提供完整开源代码,可以下载早期开源版本使用,推荐3.5—4.0)。
进入到Kettle目录,如果Kettle部署在windows环境下,双击运行spoon.bat文件,出现如下界面:
图 4 Kettle启动

Kettle家族目前包括3个核心产品:Spoon、Pan、Kitchen。
SPOON 允许你通过图形界面来设计ETL转换过程(Transformation)。
PAN 允许你批量运行由Spoon设计的ETL转换 (例如使用一个时间调度器)。Pan是一个后台执行的程序,没有图形界面。
KITCHEN 允许你批量运行用Chef设计的jobs。KITCHEN 允许你批量使用由Chef设计的任务 (例如使用一个时间调度器)。KITCHEN也是一个后台运行的程序。
2.1.2. Kettle转换
转换是ETL过程的完整流程,换句话说转换包含了数据抽取、转换和加载过程。通过KETTLE的转换,用户可以将抽取转换和加载过程编排成一个数据流,其中抽取转换和加载都是流程中的插件,具体如下图所示:
图 5 KETTLE转换流程
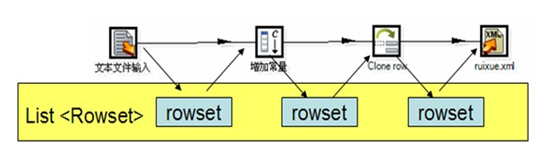
每一个组件将结果通过一个集合队列传递到下一个组件,两个组件之间相当于链接了一根线,这就是流程编排了。
Kettle的具体转换组件如下所示:
输入插件:
文本文件输入、生成记录、表输入、Fixed file input、Get data from XML
输出插件:
XML输出、删除、插入/更新、文本文件输出、更新、表输出
转换插件:
Add a checksum、Replace in string、Set field value、Unique rows(HashSet)、增加常量、增加序列、字段选择、拆分字段
Flow插件:
Abort、Switch/case、空操作、过滤记录
脚本插件:
Modified Java Script Value、执行SQL脚本
查询插件:
File exists、Table exists、调用DB存储过程
转换的执行过程如下所示:
图 6 KETTLE转换流程执行过程
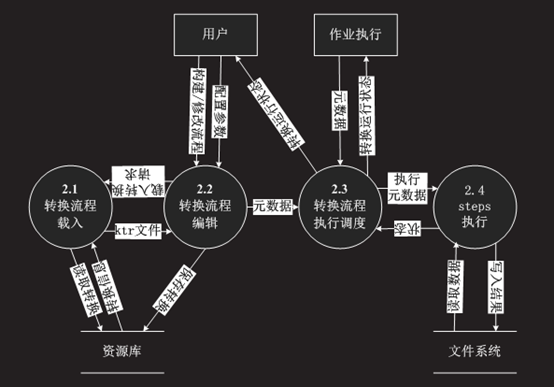
2.1.3. Kettle作业
作业用一句最简单的话就是将多个转换按照既定的任务序列执行,并且可以定期的执行。
图-7 作业具体执行流程
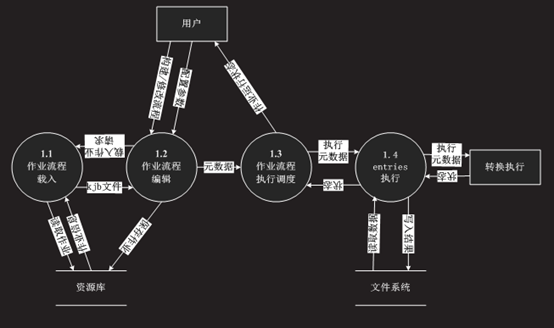
作业的插件如下所示:
通用插件:
START、DUMMY、Transformation
文件管理插件:
Copy Files、Compare folders、Create a folder、Create file、Delete files、Delete folders、File Compare、Move Files、Wait for file、Zip file、Unzip file
条件插件:
Check Db connections、Check files locked、Check if a folder is empty、Check if files exist、File Exists、Table exists、Wait for
脚本插件:
Shell、SQL
Utility插件:
Ping a host、Truncate tables
文件传输插件:
Secure FTP==get a file with SFTP、put a file with SFTP、FTP Delete
2.1.4. Kettle流程部署
我们不能总是依赖图形界面来执行作业和转换,这样系统的执行效率会有损耗,因此我们需要使用命令行工具执行。
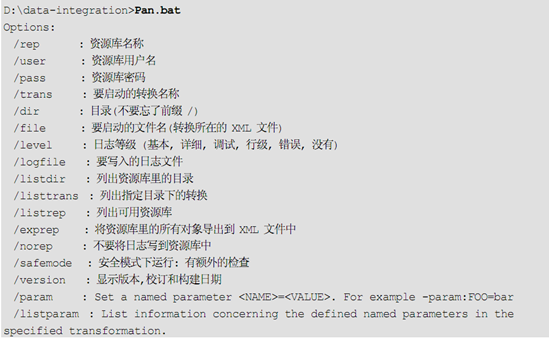
对于转换可以用Pan工具执行,Pan命令来执行转换,下面给出的是pan参数:
图-8 Pan
作业可以用Kitchen工具执行,下面给出的是Kitchen参数:
图-9 Kitchen
2.1.5. 传统数据同步
数据同步有五种方式,以下将介绍这五种方式以及优缺点:
- 全表拷贝
定时清空目的数据源,将源数据源的数据全盘拷贝到目的数据源。一般用于数据量不大,实时性要求不高的场景
优点: 基本不影响业务系统,开发、部署都很简单
缺点: 效率低
- 数据比较
通过比较两边数据源数据,来完成数据同步。一般用于实时性要求不高的场景。
优点: 基本不影响业务系统
缺点: 效率低
- 时间戳
通过比较两边数据源数据,来完成数据同步。一般用于实时性要求不高的场景。
优点: 基本不影响业务系统
缺点: 效率低
- 触发器
在源数据库建立增、删、改触发器,每当源数据库有数据变化,相应触发器就会激活,触发器会将变更的数据保存在一个临时表里。ORCLE 的 同步 CDC (synchronized CDC) 实际上就是使用的触发器
优点: 能做到实时同步
缺点: 降低业务系统性能,ORCLE 的 synchronized CDC 大概降低10% 左右。 影响到业务系统,因为需要在业务系统建立触发器。
- 日志
通过解析预写日志的方式进行数据同步。
预写日志中记录的是用户的操作。
比如oracle、hbase均有预写日志。

















 2027
2027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









