






正则提取器的一般使用场景是, 在我第二个请求参数中需要加入第一个请求的返回值, 此时通过正则提取器可以提取第一个请求返回值中指定的字段信息并赋值, 在第二个请求参数中直接引用该变量即可
jmeter的正则提取器截图如下:
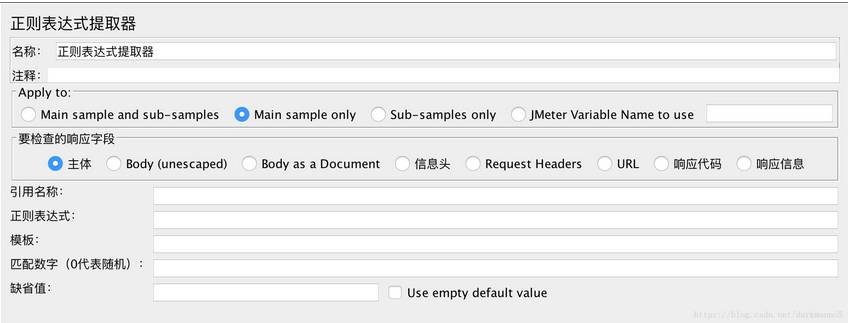
这里写图片描述
简单介绍下其中几个比较重要的字段的信息, 如下表
接下来看下实际的使用,
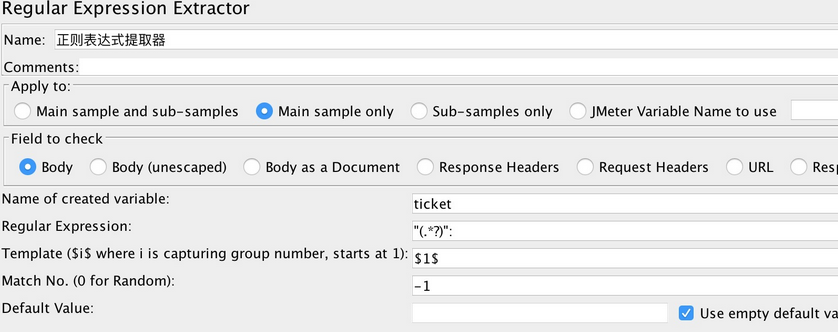
如图所示, 取登录后返回的ticket值, 此时因为方便说明, 使用"(.*?)"来获取返回值中双引号之间的内容:
这里写图片描述
添加debug元件, 展示debug信息如下,
这里写图片描述
此时, ${ticket}表示取的是第一列的值, 第一列是由模板上的$1$确定的,
此时Match No设置为-1 ,表示会返回所有匹配值数组的元素, 可以看到返回有三个元素分别为${ticket_1},${ticket_2},${ticket_3} 此时, 若有多行数据, 且模板处设置的为$1$, 如果选择第一个数组元素, 则:
• ${ticket_1_g0}取的都是第一个匹配值的第一列全部的数据
• ${ticket_1_g1}取的是第一个匹配值的第一列第一行的数据,
• ${ticket_1_g2}取的是第一个匹配值的第一列第二行的数据,
* ${ticket_2_g1}取的是第二个匹配值的第一列第一行的数据,
再来看一个比较简单的正则, 如下, 只取匹配值中的第一个元素:
这里写图片描述
这里写图片描述
Match No设置为1 , 表示只会选择返回的匹配值数组当中的第一个元素, 直接使用${ticket}表示即可, 此时, 若有多行数据, 且模板处设置的为$1$, 则:
• ${ticket_g0}取的都是第一列全部的数据
• ${ticket_g1}取的是第一列第一行的数据,
• ${ticket_g2}取的是第一列第二行的数据,
---------------------
Jmeter中关联可以在需要获取数据的请求上 右键-->后置处理器 选择需要的关联方式,如下图有很多种方法可以提取动态变化数据:

二、正则表达式提取器:
1、比如需要提取如下响应文本中的 “<title>百度一下,你就知道</title>” 里面的 “百度一下,你就知道”:

2、设置正则表达式提取器:

说明:
(1)引用名称:下一个请求要引用的参数名称,如填写title,则可用${title}引用它。
(2)正则表达式:
():括起来的部分就是要提取的。
(3)模板:用$$引用起来,如果在正则表达式中有多个正则表达式,则可以是$2$$3$等等,表示解析到的第几个值给title。如:$1$表示解析到的第1个值
(4)匹配数字:0代表随机取值,1代表全部取值,通常情况下填0
(5)缺省值:如果参数没有取得到值,那默认给一个值让它取。
3、使用2中获取到的值:

三、关于正则表达式的举例说明:
1、提取单个字符串:
假如想匹配Web页面的如下部分:name = "file" value = "readme.txt">并提取readme.txt。一个合适的正则表达式:name = "file" value = "(.+?)">。
():封装了待返回的匹配字符串。
.:匹配任何单个字符串。
+:一次或多次。
?:不要太贪婪,在找到第一个匹配项后停止。
2、提取多个字符串:
假如想匹配Web页面的如下部分:name = "file.name" value = "readme.txt">并提取file.name和readme.txt。一个合适的正则表达式:name = "(.+?)" value = "(.+?)"。这样就会创建2个组,分别用于$1$和$2$
比如:
引用名称:MYREF
模板:$1$$2$
如下变量的值将会被设定:
MYREF: file.namereadme.txt
MYREF_g0: name = "file.name"value = "readme.txt"
MYREF_g1: file.name
MYREF_g2: readme.txt
在需要引用地方可以通过:${MYREF}, ${MYREF_g1进行使用。
Java正则表达式方法
这里就不对Java正则表达式的使用做基础学习了,下面列出了我们在进行“关联”操作时,需要掌握的基本元字符:
( ) :将 () 之间括起来的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域,我们主要就是利用这个元字符配合所指定的字符串匹配规则来进行匹配信息的提取;
.+: 一个以上的任意字符,通过Greediness(贪婪型)匹配策略进行表达式模板的匹配(最大匹配);
.+?:通过?元字符表示一个非贪婪模式匹配,即通过 Reluctant(勉强型)匹配策略进行表达式模板的匹配(最小匹配);
另外,还包括.*,.*?,\d,\D,\w,\W等。
参考:https://www.cnblogs.com/LiangHu/p/6230372.html

















 4881
4881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









