






 本文分享了作者在爬取特定网站过程中遇到的问题及解决方案,包括处理display:none属性对数据的影响、解决302重定向问题的方法等。通过调整爬虫策略和代码实现,成功实现了网页的有效抓取。
本文分享了作者在爬取特定网站过程中遇到的问题及解决方案,包括处理display:none属性对数据的影响、解决302重定向问题的方法等。通过调整爬虫策略和代码实现,成功实现了网页的有效抓取。
淘宝那次抓包,居然发现不了要抓的url位置,三星中。。。
不过不怕,不就是没法快点分析出包嘛,下次用phantomJS硬杠,或者有时间慢慢分析也好。
今天挑战一个稍微好爬的网站:狗搬家(误)
打开后台代码一看,山口山
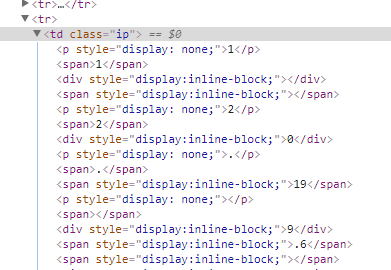
一堆<p style="display:none;">直接影响分析数据。
有个运用无头浏览器的爬虫使用了图像分析法,不过老夫真心认为这玩意还是不要随便用比较好,就像一些简单的网站不要用phantomJS一样
稍微分析ip那里的代码就可以找到解的(避免查水表不发布源代码)去除html标签,连着里面的元素去除什么的,用regex还是比较简单的
结果想再爬这个网页时,出现了302重定向
这里,直接ban掉重定向没有多大用,关键是识别到状态再根据情况重新请求。
从stackoverflow一哥们那里搞来了这段代码:


self.log("(parse_page) response: status=%d, URL=%s" % (response.status, response.url)) if response.status in (302,) and 'Location' in response.headers: self.log("(parse_page) Location header: %r" % response.headers['Location']) yield Request(response.headers['Location'],callback=self.parse,meta=self.meta)
这段代码判定返回状态,并根据情况决定要不要重传。(这里应该有urljoin的,不知为何我安装的scrapy没有)
结果是yield后面的代码没有运行就退出了。
还是一样去stackoverflow求助,结果有人告诉我,ban了filter。
dont_filter这个参数开始是为了防止程序死循环设计的,然鹅在这个框架就成了问题,它不能yield第二层request
初始化request时,dont_filter=true,程序就会不管3721把请求提交,然后数据就返回了
幸好这里的302不会一直302,只要cookies对上了,返回的就是200和网页代码,不会出现栈溢出
self.log("(parse_page) response: status=%d, URL=%s" % (response.status, response.url)) if response.status in (302,) and 'Location' in response.headers: self.log("(parse_page) Location header: %r" % response.headers['Location']) yield Request(response.headers['Location'],callback=self.parse,meta=self.meta,dont_filter=True)
后来仔细看源码。。。特码这个教程只解决了display:none和302的问题,实际的数据还是有毒。。。
看了下http://www.cnblogs.com/w-y-c-m/p/6879551.html这位兄台的方法,姿势get到了!不仅知道了如何反混淆,还学会了debug网站

















 5732
5732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









