






 本文介绍如何利用Python Scikit-Learn库进行线性回归分析,包括数据清洗、模型拟合、预测和误差评估等步骤。通过实践案例展示了如何通过马力度量汽车燃油效率。
本文介绍如何利用Python Scikit-Learn库进行线性回归分析,包括数据清洗、模型拟合、预测和误差评估等步骤。通过实践案例展示了如何通过马力度量汽车燃油效率。

1.有挑战的工作
在dataquest,我们无比坚信通过实战来学习,我们希望在各种任务中给你带来学习经验。当任务聚焦于概念时,一系列完整的结构问题的挑战让你通过强化训练去消化。你也可以了解更多关于强化训练的内容在 here 和 here。在许许多多的任务中一系列的挑战会比较相似,但是通过小小的说明资料和巨大的专项练习来消化。
在这些挑战中,我们强烈建议你在自己的电脑中进行编程。也就是dataquest之外的环境去练习。你也可以使用dataquest的交互界面写代码,并迅速运行你的代码,查看你是否写对了。默认情况下,点击 check code按钮运行你的代码,执行检查答案的功能。
如果你有问题,或者运行出错,直接去 Dataquest forums 或者我们的 Slack community
2.数据清洗
在这个挑战任务中,当我们尝试回答以下问题之前,我们需要建立在上一个任务的基础之上:
一辆汽车的燃料效率被它的什么性能怎样影响?
我们聚焦到上一个问题中,关于重量影响着燃料效率拟合的线性回归模型。在这个挑战任务中,我们将要探索马力怎样影响汽车的燃料效率,练习使用cikit-learn来拟合线性回归模型
与weight列horsepower列里丢失值不同的是。这些被?表示。为了让我们能够拟合模型,就把这些行给过虑掉。我们已经读取了cars Dataframe框架的auto-mpg.data数据。
练习:
移走所有在horsepower里包含?的列并且把horsepower列转化为浮点数。
把这个新的Dataframe赋值给 filtered_cars
import pandas as pd
columns = ["mpg", "cylinders", "displacement", "horsepower", "weight", "acceleration", "model year", "origin", "car name"]
cars = pd.read_table("auto-mpg.data", delim_whitespace=True, names=columns)
filtered_cars = cars[cars['horsepower'] != '?']
filtered_cars['horsepower'] = filtered_cars['horsepower'].astype('float')
3.数据的探究
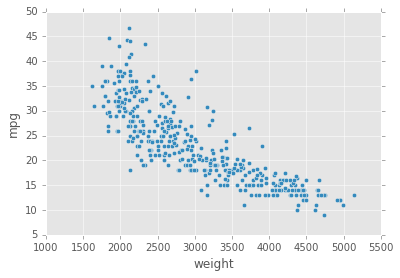
现在我们的horsepower值已经被清理了,horsepower值和mpg值形成了一个视觉散点图。让我们跟weight值和 mpg值形成的散点图做对比。
按照垂直顺序,使用Dataframe框架绘制两个散点图
顶部的图,绘制一个 X轴为horsepower列,Y轴为mpg列的散点图
底部的图,绘制一个X轴为weight列,Y轴为mpg列的散点图。
%matplotlib inline
import matplotlib.pyplot as plt
filtered_cars.plot('horsepower', 'mpg', kind='scatter', c='red')
filtered_cars.plot('weight', 'mpg', kind='scatter', c='blue')
plt.show()

4.拟合一个模型‘
尽管两个X轴非常不同,但是直接比较又比较困难。似乎在汽车马力和燃料效率之间存在某种关系。让我们使用horsepower值拟合一个线性回顾模型来定量这两者之间的关系。
练习:
通过LinearRegresson创造一个新的实例,并赋值给lr
把horsepower列作为输入值,使用fit方法拟合一个线性回归模型
在训练数据(通过filtered_cars的horsepower列值)得出的模型中做一个预测,并把预测结果赋值给 predictions
显示predictions中的前5个值,及filtered_cars中的mpg的前5个值。
import sklearn
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(filtered_cars[["horsepower"]], filtered_cars["mpg"])
predictions = lr.predict(filtered_cars[["horsepower"]])
print(predictions[0:5])
print(filtered_cars["mpg"][0:5].values)
5.绘制预测值
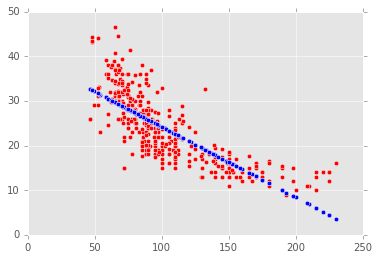
在上个任务中,我们绘制了预测值与实际值的散点图,通过视觉的方式来理解模型的有效性。让我们更好的预测重复练习一下。
练习
将两个散点图画在同一个表中:
其中之一:X轴是horsepower值,Y轴是预测的燃料效率值,使用蓝色绘制
另一个:X轴是horsepower值,Y轴是实际的燃料效率值,使用红色绘制。
plt.scatter(filtered_cars["horsepower"], filtered_cars["mpg"], c='red')
plt.scatter(filtered_cars["horsepower"], predictions, c='blue')
plt.show()
6.错误度量
评估模型跟数据的拟合程度有多好,你可以计算模型的MSE,RMSE值。然后,你可以通过上个任务中你拟合的模型来比较MSE和RMSE。上个任务中你通过汽车的重量(weight 列)和燃料效率(mpg 列)找到的拟合模型,再重新调用一下。
练习:
计算预测值的MSE,赋值给mse
计算预测值的RMSE,赋值给rmse
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(filtered_cars["mpg"], predictions)
print(mse)
rmse = mse ** 0.5
print(rmse)
7.下一步
上一节中,我们计算模型的MSE值是18.78RMSE值是4.33
下面是一个比较两个模型MSE,RMSE值的表格
| weight | horsepower | |
| MSE | 18.78 | 23.94 |
| RMSE | 4.33 | 4.89 |
如果我们只能输入一个值在我们的模型中,那么就输入weight值来预计燃料效率值,因为它的MSE,RMSE值更低。在上个任务中,我们学习通过多重特征值来建立一个更加可靠的预测模型
在这个挑战中,你练习 使用了scikit-learn来拟合一个线性回归模型并且比较了2个不同模型的错误度量值。在下个任务中,我们将探究分类,并具体了解逻辑回归技术。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









