



参考网址:
(1)恶意PDF分析的5个步骤
【https://countuponsecurity[.]com/2014/09/22/malicious-documents-pdf-analysis-in-5-steps/?utm_source=tuicool&utm_medium=referral】
(2)解剖一个恶意的pdf
【https://www[.]cert-ist.com/public/en/SO_detail?code=malicious_pdf】
(3)深入浅出实战***恶意PDF文档
【http://netsecurity[.]51cto[.]com/art/200907/138668[.]htm】
(5)pdfid,pdfparse工具
https://blog.didierstevens.com/category/pdf/
(6)PDF文件解析与PDF恶代分析中的一些坑
【http://www[.]itbaby[.]me/blog/59f7ea965d21b31fcd4e2037】
(7)文档分析备忘录
【https://zeltser[.]com/media/docs/analyzing-malicious-document-files[.]pdf】
(8)pdfid下载
http://didierstevens.com/files/software/pdfid_v0_2_3.zip
为什么pdf利用js
恶意PDF文件使用PDF阅读器中发现的漏洞(通常是Acrobat Reader)强制读者在打开PDF文件时运行任意代码。这些漏洞通常是缓冲区溢出,在PDF阅读器解析制作的文件时发生。通常可以找到这些漏洞:
(1)在PDF基元:例如,对参数大于2 ^ 24的PDF原语“/ Colors”的调用会导致Adobe Reader 9.3发生堆溢出(请参阅CERT-IST / AV-2009.469,CVE-2009-3459)
(2)在 PDF阅读器中嵌入的JavaScript解释器中:例如,调用JavaScript“Collab.getIcon”方法会导致Acrobat Reader 9.0中的堆栈溢出(请参阅CERT-IST / AV-2009.078,CVE-2009-0927)
为了充分利用内存溢出并在发生溢出时能够运行任意代码,***者需要知道发生溢出时PDF阅读器内存的确切布局。但更多的时候,它会使用JavaScript代码在触发漏洞之前执行“堆喷”。这种技术允许执行任意代码而不知道要修改的确切内存位置。然后***者用多条跳转指令填充内存到其***代码,增加了发生溢出时执行其中一个的概率。
因此,即使不是绝对必要的,大多数恶意PDF文件都包含一个JavaScript代码:
要么是因为目标漏洞在于JavaScript解释器,
或者因为***技术使用JavaScript(例如堆喷射***)。
要在打开文档时触发该JavaScript代码,甚至在特定事件发生后再触发该JavaScript代码,***者将使用以下PDF基元之一:“/ OpenAction”或“/ AA”(附加操作)。
有两种典型的情况可能导致恶意PDF导致用户系统感染:
(1)当受害者访问恶意网站时,感染最常发生,恶意网站旨在强制网页浏览器自动打开被困PDF。在这种情况下,它是受到***的“Acrobat Reader”浏览器插件。通过在陷印的网页中插入一个小的“iframe”标签(例如,尺寸为1 x 1像素),这种***可能非常隐蔽(隐形和无声)。
(2)也可以通过向受害者发送附在电子邮件上的被困PDF文件来完成。电子邮件本身会用任何好的借口鼓励受害者打开附件。在这种情况下,这是受到***的独立“Acrobat Reader”应用程序。
(3)还有第三种情况,可以用于非常特殊(并且不常见)的情况,这种情况下,漏洞也影响到Adobe附加到Windows文件资源管理器应用程序的扩展。当鼠标光标移动到PDF文件图标上时,此扩展允许Windows资源管理器显示PDF文件的预览或弹出工具提示以及一般信息。在这种情况下,只要查看恶意PDF文件所在目录的内容(例如网络共享)就足以触发感染。在“JBIG2Decode”漏洞的情况下(参见CERT-IST / AV-2009.078,CVE-2009-0658)已经证明了这种感染情况。
五个步骤
(1)查找并提取Javascript
(2)反混淆JavaScript
(3)提取shellcode
(4)创建一个shellcode可执行文件
(5)分析shellcode并确定做什么。
PDF字段研判:
/Page gives an indication of the number of pages in the PDF document. Most malicious PDF document have only one page.
/Encrypt indicates that the PDF document has DRM or needs a password to be read.
/ObjStm counts the number of object streams. An object stream is a stream object that can contain other objects, and can therefor be used to obfuscate objects (by using different filters).
/JS and /JavaScript indicate that the PDF document contains JavaScript. Almost all malicious PDF documents that I’ve found in the wild contain JavaScript (to exploit a JavaScript vulnerability and/or to execute a heap spray). Of course, you can also find JavaScript in PDF documents without malicious intend.
/AA and /OpenAction indicate an automatic action to be performed when the page/document is viewed. All malicious PDF documents with JavaScript I’ve seen in the wild had an automatic action to launch the JavaScript without user interaction.
The combination of automatic action and JavaScript makes a PDF document very suspicious.
/JBIG2Decode indicates if the PDF document uses JBIG2 compression. This is not necessarily and indication of a malicious PDF document, but requires further investigation.
/RichMedia is for embedded Flash.
/Launch counts launch actions.
/XFA is for XML Forms Architecture.关键字
obj #obj对象开始
endobj #obj对象结束
stream #stream流对象开始
endstream #stream流对象结束
xref #交叉引用表开始
trailer #文件尾对象开始
startxref #交叉引用表结束
/Page #文件页数
/Encrypt #是否加密
/ObjStm #objectstreams的数量,objectstreams可包含其他Object对象,即嵌套
/JS #代表javascript嵌有JavaScript代码,可直接提取恶意代码
/JavaScript #代表javascript嵌有JavaScript代码,可直接提取恶意代码
/AA #以下三个为特定特征,打开对象自动执行
/OpenAction
/AcroForm
/URI #内嵌url链接
/Filter #/Filter字段出现,表示了下面的stream流进行了加密
/RichMedia #富文本
/Launch #执行Action的次数与OpenAction字段关联
#/xxxx 带斜杠的关键字包含在<<>>字典内部
RTF提取

PDF分析命令


分析过程
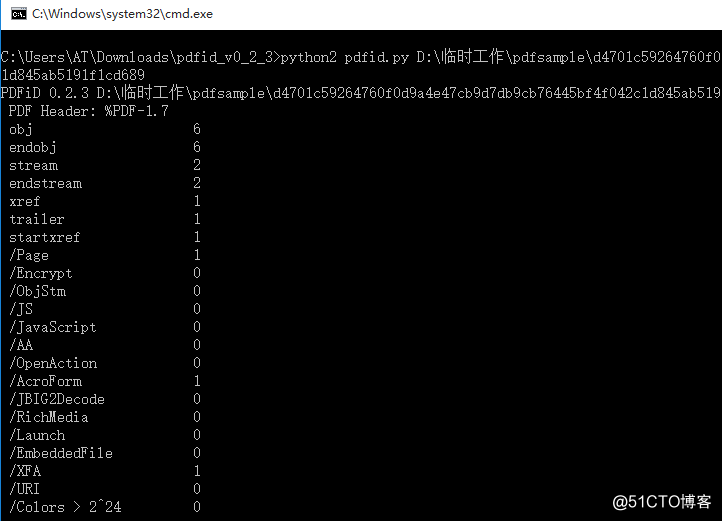
从中可以看到obj对象有6个
其中/AcroFrom 和/XFA两个对象可能存在js混淆代码
我们再使用pdf-parser来解剖pdf文件,看具体的对象细节
使用
Usage: pdf-parser.py [options] pdf-file|zip-file|url
pdf-parser, use it to parse a PDF document
Options:
--version show program's version number and exit
-h, --help show this help message and exit
-s SEARCH, --search=SEARCH
string to search in indirect objects (except streams)
-f, --filter pass stream object through filters (FlateDecode,
ASCIIHexDecode, ASCII85Decode, LZWDecode and
RunLengthDecode only)
-o OBJECT, --object=OBJECT
id of indirect object to select (version independent)
-r REFERENCE, --reference=REFERENCE
id of indirect object being referenced (version
independent)
-e ELEMENTS, --elements=ELEMENTS
type of elements to select (cxtsi)
-w, --raw raw output for data and filters
-a, --stats display stats for pdf document
-t TYPE, --type=TYPE type of indirect object to select
-v, --verbose display malformed PDF elements
-x EXTRACT, --extract=EXTRACT
filename to extract malformed content to
-H, --hash display hash of objects
-n, --nocanonicalizedoutput
do not canonicalize the output
-d DUMP, --dump=DUMP filename to dump stream content to
-D, --debug display debug info
-c, --content display the content for objects without streams or
with streams without filters
--searchstream=SEARCHSTREAM
string to search in streams
--unfiltered search in unfiltered streams
--casesensitive case sensitive search in streams
--regex use regex to search in streams
-g, --generate generate a Python program that creates the parsed PDF
file
--generateembedded=GENERATEEMBEDDED
generate a Python program that embeds the selected
indirect object as a file
-y YARA, --yara=YARA YARA rule (or directory or @file) to check streams
(can be used with option --unfiltered)
--yarastrings Print YARA strings
--decoders=DECODERS decoders to load (separate decoders with a comma , ;
@file supported)
--decoderoptions=DECODEROPTIONS
options for the decoder
-k KEY, --key=KEY key to search in dictionaries对象1对象/fliter 表明流被加密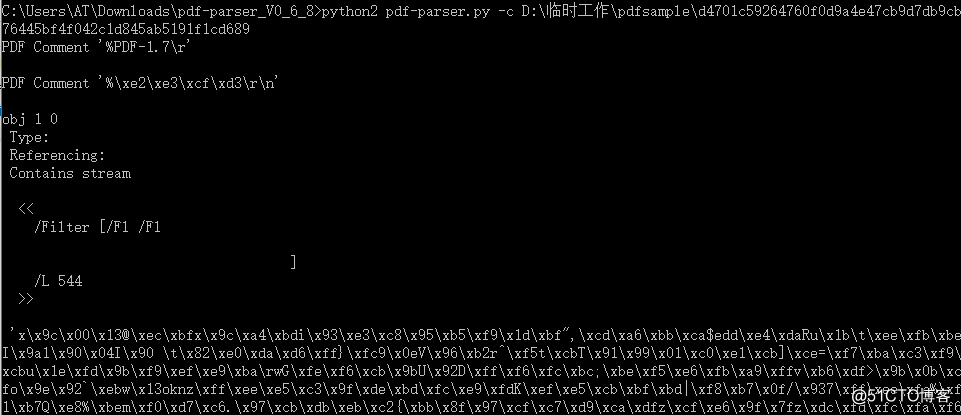
对象2引用了对象1中的/XFA
通过-filter开关。-raw开关允许以更简单的方式显示输出。解压编码的流数据
可以看到js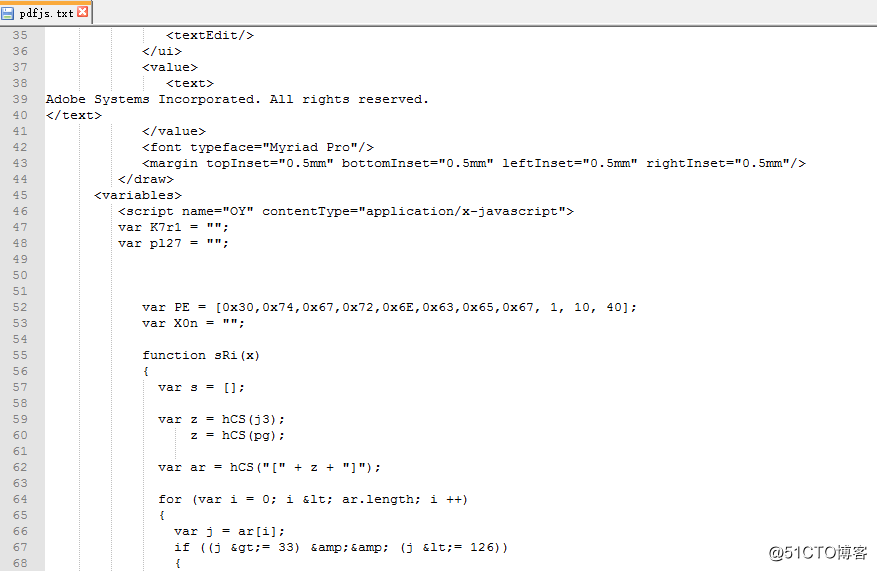
PDF文档构造
(1)头部
每个PDF文档必须以标明其为PDF文档的一行代码(即幻数)开头;它还规定了用于描述这个文档的PDF语言规范版本号:%PDF-1.1。
在一个PDF文档中,以符号%开头的行都是注释行,注释行的内容将被忽略,但是有两个例外:
文档的开头:%PDF-X.Y
文档的结尾:%%EOF
(2)对象,对象是pdf文档基本元素
首先是catalog,目录对象,它告诉pdf阅读器,为了装配文档,需要从哪里开始查找对象:
1 0 obj
/Type /Catalog
/Outlines 2 0 R
/Pages 3 0 R这实际上是一个间接对象,因为它具有一个编号,并且可以通过该编号来引用对象。用法为:一个编号、一个版本号、单词obj,对象体,最后是单词endobj,如下:
1 0 obj
object主体
endobj通过联合使用对象编号和版本号,我们就能够唯一引用一个对象
我们的第一个对象catalog 的类型是字典类型,字典类型在pdf文档中非常常见。该类型以符号<<开头,并以符号>>作为结束
字典的元素由键和值两部分组成,也就是说一个元素就是一个名/值对,即数据有一个名称,还有一个与之相对应的值:字典不仅可以存放元素,而且还能存放对象甚至其他字典。大部分字典都是利用第一个元素来声明自身的类型 ,该元素以/type为键,其后跟一个类型本身的名称(对本例而言就是/catalog)为值:
(Type /Catalog)
对象catalog必须给出这个PDF中能找到的页面(对应pages对象)和大纲(对应于outline对象)如下:
/Outlines 2 0 R
/Pages 3 0 R2 0 R和3 0 R表示引用间接对象2和间接对象3.间接对象2描述大纲,间接对象3描述页面。
下面为添加的第二个间接对象:
2 0 obj
/Type /Outlines
/Count 0
endobj这个对象是一个/Outlines类型的字典。它具有一个键为/Count、值为0的元素。这意味着这个PDF文档没有大纲。我们可以通过编号2和版本0来引用对象。
我们前面定义了catalog(目录)和outlines(大纲)对象,接下来还得定义我们的页面。
Kids 元素是一个页面列表;一个列表必须用方括弧括住。因此依据这个Pages对象来看,我们的文档中只有一个页面;这个页面的具体规定,见间接对象4(注意引用4 0 R ):
3 0 obj
/Type /Pages
/Kids [4 0 R]
/Count 1
endobj要描述页面,我们必须规定页面的内容、用于显示这个页面的资源以及页面的大小。这些任务可由下面的代码来完成:
4 0 obj
/Type /Page
/Parent 3 0 R
/MediaBox [0 0 612 792]
/Contents 5 0 R
/Resources <<
/ProcSet [/PDF /Text]
/Font << /F1 6 0 R >>
endobj页面内容是由间接对象5来规定的。/MediaBox 是页面的尺寸。这个页面所用的资源是字体和PDF文字绘制例程。我们在间接对象6中将字体规定为[F1]。
间接对象5中存放的是页面内容,它是一种特殊的对象,即流对象。流对象可以用来保存由单词stream和endstream包围的对象内容。流对象的好处是允许使用多种类型的编码技术(在PDF语言中称为过滤器),例如压缩(例如zlib FlateDecode编码)。考虑到易读性,我们没有在这个流中实施压缩处理:
5 0 obj
/Length 43 >>
stream
BT /F1 24 Tf 100 700 Td (Hello World) Tj ET
endstream
endobj这个流的内容是一组PDF文字绘制指令。这些指令是由BT和ET括起来的,实际上就是命令绘制例程做下面的事情:
使用大小为24的F1字体
转到100 700位置处
绘制文字:Hello World
在PDF语言中,字符串必须用圆括号括起来。
我们的PDF文档已经基本上组装好了。我们需要的最后一个对象是font(字体)对象:
6 0 obj
/Type /Font
Subtype /Type1
/Name /F1
/BaseFont /Helvetica
/Encoding /MacRomanEncoding
endobj(3)尾部
上面就是绘制一个页面所需的全部对象。但是仅有这些内容还不足以使阅读程序(即显示pdf文档的程序,如Adobe的Acrobat Reader)来读取和显示我们的PDF文档。绘制例程需要知道文档描述起始于哪个对象(即root对象),以及每个对象的索引之类的技术细节。
每个对象的索引称为交叉引用xref,它描述每个间接对象的编号、版本和绝对的文件位置。PDF文档中的第一个索引必须从版本为65535的0号对象开始:
标识符xref后面的第一个数字是第一个间接对象(这里是0号对象)的编号,第二个数字是xref表(7个表项)的大小。
第一栏是间接对象的绝对位置。第二行的值12表明间接对象1的起始地址距文件开头为12字节。第二栏是版本,第三栏指出对象正在使用(用n表示)还是已经释放(用f表示)。
定义交叉引用之后,我们在尾部中定义root对象:
trailer
/Size 7
/Root 1 0 R不难看出,这是一个字典。最后,我们需要利用xref元素的绝对位置和幻数%%EOF来结束这个PDF文档:其中,644是在这个PDF文件内的xref的绝对位置
startxref
644
%%EOF完成清单
%PDF-1.1
1 0 obj
/Type /Catalog /Outlines 2 0 R /Pages 3 0 R
endobj
2 0 obj
/Type /Outlines /Count 0
endobj
3 0 obj
/Type /Pages /Kids [4 0 R] /Count 1
endobj
4 0 obj
/Type /Page /Parent 3 0 R /MediaBox [0 0 612 792] /Contents 5 0 R
/Resources <<
/ProcSet [/PDF /Text]
/Font << /F1 6 0 R >>
endobj
5 0 obj
/Length 43 >>
stream
BT /F1 24 Tf 100 700 Td (Hello World) Tj ET
endstream
endobj
6 0 obj
/Type /Font /
Subtype /Type1
/Name /F1
/BaseFont /Helvetica
/Encoding /MacRomanEncoding
endobj
xref
0 7
0000000000 65535 f
0000000012 00000 n
0000000089 00000 n
0000000145 00000 n
0000000214 00000 n
0000000419 00000 n
0000000520 00000 n
trailer
/Size 7 /Root 1 0 R
startxref
644
%%EOF(4)添加有效载荷
PDF语言支持为事件关联相应的动作。举例来说,当某个页面被查看的时候,可以执行相应的动作(例如 访问一个网站)。我们感兴趣的是在打开一个PDF文档的时候执行某个动作。通过为catalog对象添加一个/OpenAction键,我们可以让PDF文档在打开时无需人工介入就执行某个动作。
1 0 obj
/Type /Catalog
/Outlines 2 0 R
/Pages 3 0 R
/OpenAction 7 0 R
endobj当打开我们的PDF文档的时候,间接对象7所规定的动作将被执行。我们可以规定一个URI动作。一个URI动作能够自动地打开一个URI,在我们这个例子中是一个URL:
7 0 obj
/Type /Action
/S /URI
/URI (https://DidierStevens.com)
endobj
ss 5、(内嵌js)
PDF语言支持内嵌的 JavaScript。然而,这个JavaScript引擎在与底层操作系统的交互方面能力非常有限,所以根本没法干坏事。 举例来说,嵌入到一个PDF文档的JavaScript代码不能访问任何文件。所以,恶意PDF文档必须利用某些安全漏洞才能摆脱JavaScript引擎的限制来执行任意的代码。我们可以使用下面的JavaScript动作,在PDF文档打开时添加并执行一些JavaScript脚本:
7 0 obj
/Type /Action
/S /JavaScript
/JS (console.println("Hello"))
endobj(6)漏洞利用
许多恶意PDF文档利用了PDF的util.printf方法的JavaScript安全漏洞来发动***。Core Security Technologies发表了一个通报,其中含有一个PoC,如下所示:
var num = 12999999999999999999888888.....
util.printf(„%45000f”,num)当这个JavaScript将被嵌入到一个PDF文档并在(在 Windows XP SP2上使用Adobe Acrobat Reader 8.1.2)打开的时候,它将试图执行地址0x30303030的代码而造成访问越界。 这意味着,通过缓冲区溢出,执行PoC将跳转至地址0x30303030(0x30是ASCII字符0的十六进制表示法)(即PoC一执行,控制流程(系统控制权)就交给0x30303030处的指令)。 因此要想利用该漏洞,我们需要编写我们的程序(shellcode),当然该程序需要从0x30303030处开始执行。
使用内嵌的JavaScript的问题是,我们不能直接写内存。Heap Spraying(堆喷射)是一种较易获得任意代码执行Exploit的技术手段。 每当我们在JavaScript中声明字符串并为其赋值时,这个字符串就会被写到一段内存中,这段内存是从堆中分配的,所谓堆就是专门预留给程序变量的一部分内存。 我们没有影响被使用的那些内存,所以我们不能命令JavaScript使用地址0x30303030的内存。 但是如果我们分配大量的字符串,那么很可能其中的一个字符串分配的内存中包含了地址0x30303030。 分配许许多多的字符串称为Heap Spraying(堆喷射)。
如果我们在堆喷射之后执行我们的PoC,就很有可能得到一个从地址0x30303030之前的某处开始、从地址0x30303030之后的某处终止的字符串,这样的话,该字符串中(起始于地址0x30303030)那些字节就会被CPU当作机器代码语句来执行。
但是,如何让我们指定的字符串包含用来利用起始于地址0x30303030的机器指令的正确语句呢? 同样,我们也无法直接完成这个任务;我们需要一种迂回战术。
如果我们设法使一个字符串被CPU当作机器代码程序(shellcode)来解释的话,那么CPU将开始执行我们从地址0x30303030开始的程序。 不过这个方法不太理想;我们的程序必须从它的第一条指令开始执行,而不是从中间的某个地方开始执行。为了解决这个问题,我们需要在程序前面填充大量NOP指令。 我们在用于堆喷射的字符串中存储这个NOP-sled,继之以我们shellcode。 NOP-sled是一个特殊程序,它的特性是每个指令的长度都是单字,而且每个指令都没有时间的操作(NOP,即空操作 ),那就是说 CPU不断执行下一个NOP指令,如此下去直到它到达我们的shellcode并且执行它(滑下NOP-sled)。
下面是一个堆喷射的范例,实际取自一个带有NOP-sled和shellcode的恶意PDF文档(参见 图 3)。
Sccs是带有shellcode的字符串,bgbl是带有NOP-code的字符串。
因为shellcode常常必须很小,所以它将通过网络下载另一个程序(恶意软件)并执行它。对于pdf文档来说,还有一种方法可用。第二阶段的程序可以嵌入到PDF文档,而shellcode可以从PDF文档提取并且执行。
(6)分析
事实上,所有的pdf文档都包含非ASCII字符,因此我们需要使用一个十六进制编辑器来分析它们。我们打开一个可疑的PDF文档,并搜索字符串JavaScript(参见图 4)。

虽然只是有一点用于格式化对象的空格,但是您应该认出PDF对象的结构:对象31是一个JavaScript动作/S /JavaScript,脚本本身没有包含在这个对象中,但是可以在对象32(注意引用3 0 R)中找到。 搜索字符串“31 0 R”,我们发现对象16引用了对象31“/AA <> ”,以及一个页面/Type /Page ,如图5所示。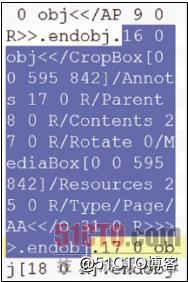
/AA 是一个注释动作,这意味着当这个页面被查看的时候这个动作就会执行。因此,我们知道:当这个PDF文档被打开的时候,它将执行一个JavaScript脚本。 让我们看看这个脚本(对象32 )的样子。
为了对它进行解压,我们可以提取二进制流(1154字节长),并通过一个简单的Perl或者Python程序对它进行解压。使用Python语言,我们只需要导入zlib,然后就可以对数据进行解压了,假设我们已经将我们的二进制流存储在data中了。
样本
MD5:d4701c59264760f0d9a4e47cb9d7db9cb76445bf4f042c1d845ab5191f1cd689
MD5: aaf8534120b88423f042b9d19f1c59ab
MD5: 98a727a32fee7115d9599b4df9b6b433
转载于:https://blog.51cto.com/antivirusjo/2054410

















 3259
3259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









