







spark程序是使用一个spark应用实例一次性对一批历史数据进行处理,spark streaming是将持续不断输入的数据流转换成多个batch分片,使用一批spark应用实例进行处理,侧重点在Steaming上面。我们常说的Spark-Streaming依赖了Spark Core的意思就是,实际计算的核心框架还是spark。我们还是上一张老生常谈的官方图:
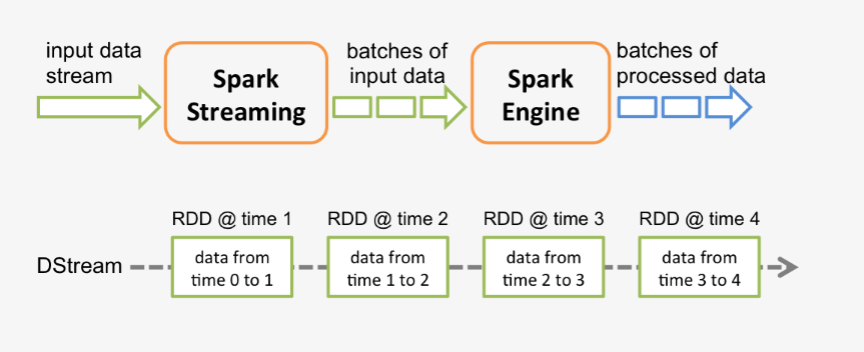
从原理上看,我们将spark-streaming转变为传统的spark需要什么?
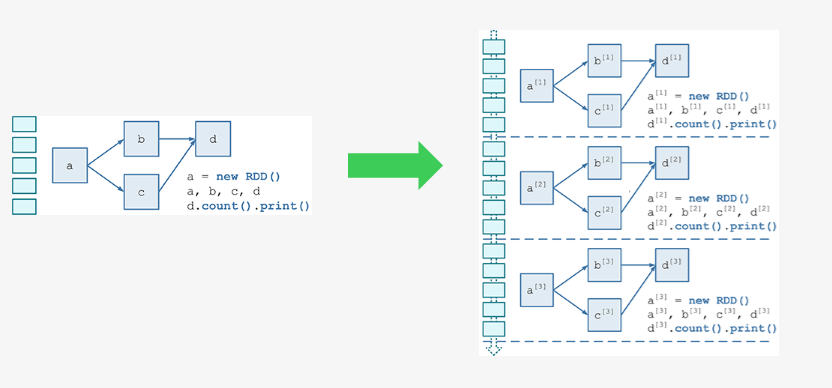
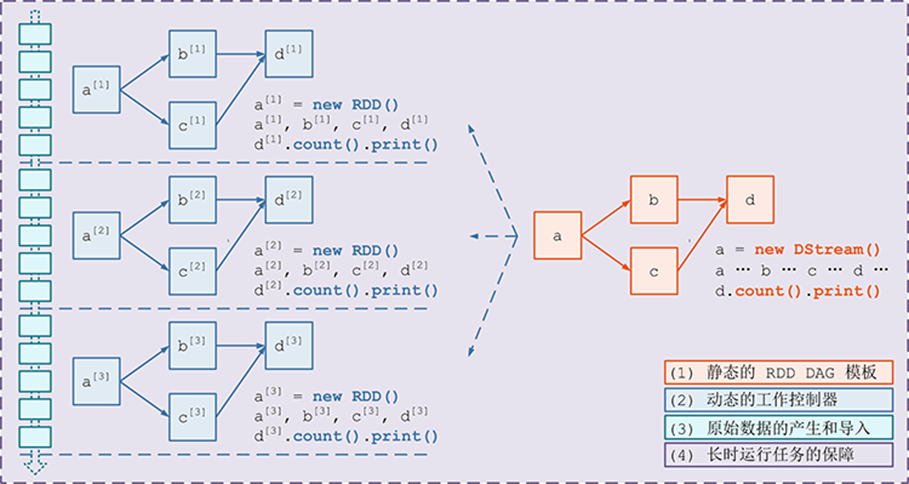
需要构建4个东西:
-
一个静态的 RDD DAG 的模板,来表示处理逻辑;
-
一个动态的工作控制器,将连续的 streaming data 切分数据片段,并按照模板复制出新的 RDD
-
DAG 的实例,对数据片段进行处理;
-
Receiver进行原始数据的产生和导入;Receiver将接收到的数据合并为数据块并存到内存或硬盘中,供后续batch RDD进行消费;对长时运行任务的保障,包括输入数据的失效后的重构,处理任务的失败后的重调。
至于上述过程具体怎么实现,我们会在spark-streaming源码分析的文章中一一解决。本文中图片文字来自于网络。

















 1131
1131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









