






 本文介绍了循环神经网络(RNN)及其变种长短时记忆网络(LSTM)的基本原理与应用。通过实例演示如何利用LSTM生成类似金庸、古龙武侠作品中的人物名字。
本文介绍了循环神经网络(RNN)及其变种长短时记忆网络(LSTM)的基本原理与应用。通过实例演示如何利用LSTM生成类似金庸、古龙武侠作品中的人物名字。
Magicly:之前翻译了一篇介绍RNN的文章,一直没看到作者写新的介绍LSTM的blog,于是我又找了其他资料学习。本文先介绍一下LSTM,然后用LSTM在金庸、古龙的人名上做了训练,可以生成新的武侠名字,如果有兴趣的,还可以多搜集点人名,用于给小孩儿取名呢,哈哈,justforfun,大家玩得开心…
RNN回顾
RNN的出现是为了解决状态记忆的问题,解决方法很简单,每一个时间点t的隐藏状态h(t)不再简单地依赖于数据,还依赖于前一个时间节点t-1的隐藏状态h(t-1)。可以看出这是一种递归定义(所以循环神经网络又叫递归神经网络Recursive Neural Network),h(t-1)又依赖于h(t-2),h(t-2)依赖于h(t-3)…所以h(t)依赖于之前每一个时间点的输入,也就是说h(t)记住了之前所有的输入。
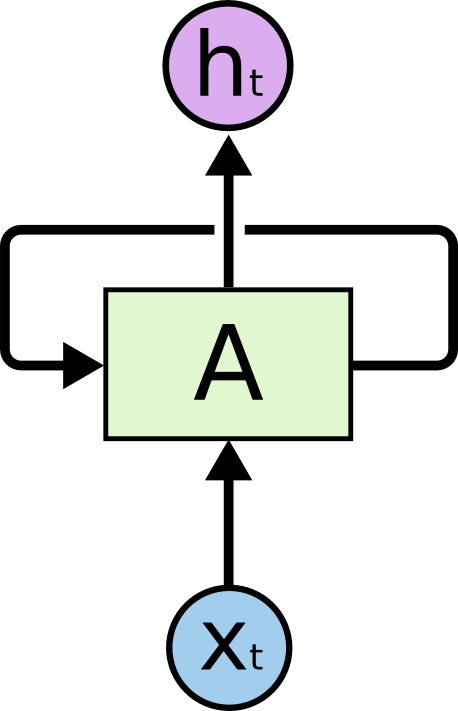
上图如果按时间展开,就可以看出RNN其实也就是普通神经网络在时间上的堆叠。
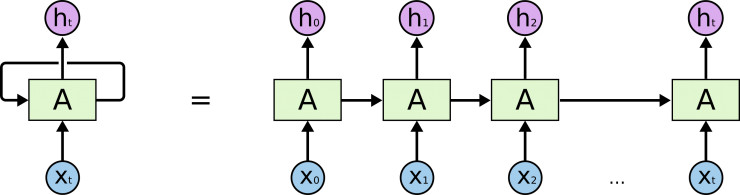
RNN问题:Long-Term Dependencies
一切似乎很完美,但是如果h(t)依赖于h(t - 1000),依赖路径特别长,会导致计算梯度的时候出现梯度消失的问题,训练时间很长根本没法实际使用。下面是一个依赖路径很长的例子:
1 我老家【成都】的。。。【此处省去500字】。。。我们那里经常吃【火锅】。。。
LSTM
Long Short Term Memory神经网络,也就是LSTM,由 Hochreiter & Schmidhuber于1997年发表。它的出现就是为了解决Long-Term Dependencies的问题,很来出现了很多改进版本,目前应用在相当多的领域(包括机器翻译、对话机器人、语音识别、Image Caption等)。
标准的RNN里,重复的模块里只是一个很简单的结构,如下图:
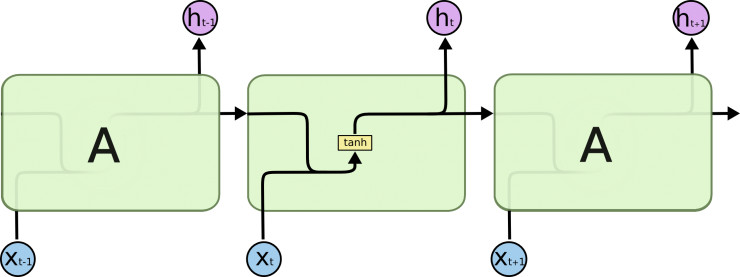
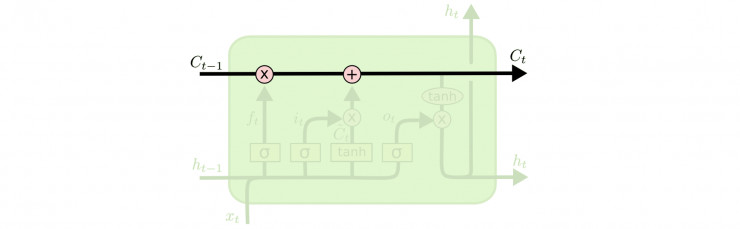
LSTM也是类似的链表结构,不过它的内部构造要复杂得多:
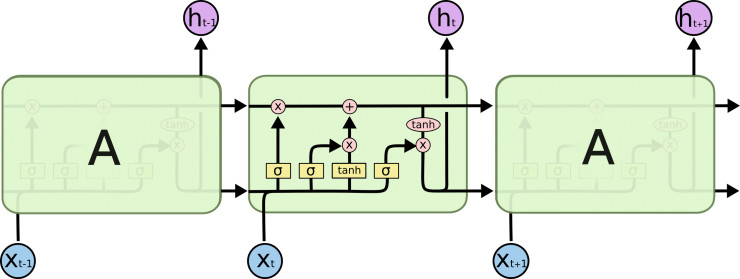
上图中的图标含义如下:

LSTM的核心思想是cell state(类似于hidden state,有LSTM变种把cell state和hidden state合并了, 比如GRU)和三种门:输入门、忘记门、输出门。
cell state每次作为输入传递到下一个时间点,经过一些线性变化后继续传往再下一个时间点(我还没看过原始论文,不知道为啥有了hidden state后还要cell state,好在确实有改良版将两者合并了,所以暂时不去深究了)。
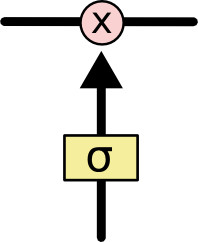
门的概念来自于电路设计(我没学过,就不敢卖弄了)。LSTM里,门控制通过门之后信息能留下多少。如下图,sigmoid层输出[0, 1]的值,决定多少数据可以穿过门, 0表示谁都过不了,1表示全部通过。
下面我们来看看每个“门”到底在干什么。
首先我们要决定之前的cell state需要保留多少。 它根据h(t-1)和x(t)计算出一个[0, 1]的数,决定cell state保留多少,0表示全部丢弃,1表示全部保留。为什么要丢弃呢,不是保留得越多越好么?假设LSTM在生成文章,里面有小明和小红,小明在看电视,小红在厨房做饭。如果当前的主语是小明, ok,那LSTM应该输出看电视相关的,比如找遥控器啊, 换台啊,如果主语已经切换到小红了, 那么接下来最好暂时把电视机忘掉,而输出洗菜、酱油、电饭煲等。
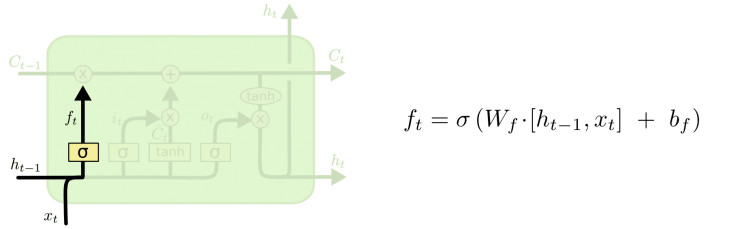
第二步就是决定输入多大程度上影响cell state。这个地方由两部分构成, 一个用sigmoid函数计算出有多少数据留下,一个用tanh函数计算出一个候选C(t)。 这个地方就好比是主语从小明切换到小红了, 电视机就应该切换到厨房。
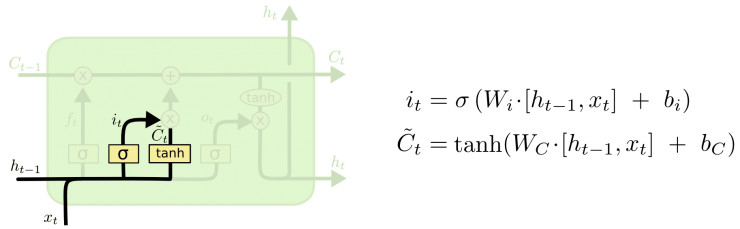
然后我们把留下来的(t-1时刻的)cell state和新增加的合并起来,就得到了t时刻的cell state。
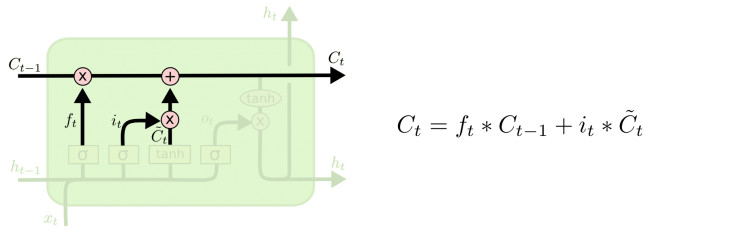
最后我们把cell state经过tanh压缩到[-1, 1],然后输送给输出门([0, 1]决定输出多少东西)。

现在也出了很多LSTM的变种, 有兴趣的可以看这里。另外,LSTM只是为了解决RNN的long-term dependencies,也有人从另外的角度来解决的,比如Clockwork RNNs by Koutnik, et al. (2014).
show me the code!
我用的Andrej Karpathy大神的代码, 做了些小改动。这个代码的好处是不依赖于任何深度学习框架,只需要有numpy就可以马上run起来!
""" Minimal character-level Vanilla RNN model. Written by Andrej Karpathy (@karpathy) BSD License """ import numpy as np # data I/O data = open('input.txt', 'r').read() # should be simple plain text file all_names = set(data.split("\n")) chars = list(set(data)) data_size, vocab_size = len(data), len(chars) print('data has %d characters, %d unique.' % (data_size, vocab_size)) char_to_ix = {ch: i for i, ch in enumerate(chars)} ix_to_char = {i: ch for i, ch in enumerate(chars)} # print(char_to_ix, ix_to_char) # hyperparameters hidden_size = 100 # size of hidden layer of neurons seq_length = 25 # number of steps to unroll the RNN for learning_rate = 1e-1 # model parameters Wxh = np.random.randn(hidden_size, vocab_size) * 0.01 # input to hidden Whh = np.random.randn(hidden_size, hidden_size) * 0.01 # hidden to hidden Why = np.random.randn(vocab_size, hidden_size) * 0.01 # hidden to output bh = np.zeros((hidden_size, 1)) # hidden bias by = np.zeros((vocab_size, 1)) # output bias def lossFun(inputs, targets, hprev): """ inputs,targets are both list of integers. hprev is Hx1 array of initial hidden state returns the loss, gradients on model parameters, and last hidden state """ xs, hs, ys, ps = {}, {}, {}, {} hs[-1] = np.copy(hprev) loss = 0 # forward pass for t in range(len(inputs)): xs[t] = np.zeros((vocab_size, 1)) # encode in 1-of-k representation xs[t][inputs[t]] = 1 hs[t] = np.tanh(np.dot(Wxh, xs[t]) + np.dot(Whh, hs[t - 1]) + bh) # hidden state # unnormalized log probabilities for next chars ys[t] = np.dot(Why, hs[t]) + by # probabilities for next chars ps[t] = np.exp(ys[t]) / np.sum(np.exp(ys[t])) loss += -np.log(ps[t][targets[t], 0]) # softmax (cross-entropy loss) # backward pass: compute gradients going backwards dWxh, dWhh, dWhy = np.zeros_like( Wxh), np.zeros_like(Whh), np.zeros_like(Why) dbh, dby = np.zeros_like(bh), np.zeros_like(by) dhnext = np.zeros_like(hs[0]) for t in reversed(range(len(inputs))): dy = np.copy(ps[t]) # backprop into y. see # http://cs231n.github.io/neural-networks-case-study/#grad if confused # here dy[targets[t]] -= 1 dWhy += np.dot(dy, hs[t].T) dby += dy dh = np.dot(Why.T, dy) + dhnext # backprop into h dhraw = (1 - hs[t] * hs[t]) * dh # backprop through tanh nonlinearity dbh += dhraw dWxh += np.dot(dhraw, xs[t].T) dWhh += np.dot(dhraw, hs[t - 1].T) dhnext = np.dot(Whh.T, dhraw) for dparam in [dWxh, dWhh, dWhy, dbh, dby]: # clip to mitigate exploding gradients np.clip(dparam, -5, 5, out=dparam) return loss, dWxh, dWhh, dWhy, dbh, dby, hs[len(inputs) - 1] def sample(h, seed_ix, n): """ sample a sequence of integers from the model h is memory state, seed_ix is seed letter for first time step """ x = np.zeros((vocab_size, 1)) x[seed_ix] = 1 ixes = [] for t in range(n): h = np.tanh(np.dot(Wxh, x) + np.dot(Whh, h) + bh) y = np.dot(Why, h) + by p = np.exp(y) / np.sum(np.exp(y)) ix = np.random.choice(range(vocab_size), p=p.ravel()) x = np.zeros((vocab_size, 1)) x[ix] = 1 ixes.append(ix) return ixes n, p = 0, 0 mWxh, mWhh, mWhy = np.zeros_like(Wxh), np.zeros_like(Whh), np.zeros_like(Why) mbh, mby = np.zeros_like(bh), np.zeros_like(by) # memory variables for Adagrad smooth_loss = -np.log(1.0 / vocab_size) * seq_length # loss at iteration 0 while True: # prepare inputs (we're sweeping from left to right in steps seq_length # long) if p + seq_length + 1 >= len(data) or n == 0: hprev = np.zeros((hidden_size, 1)) # reset RNN memory p = 0 # go from start of data inputs = [char_to_ix[ch] for ch in data[p:p + seq_length]] targets = [char_to_ix[ch] for ch in data[p + 1:p + seq_length + 1]] # sample from the model now and then if n % 100 == 0: sample_ix = sample(hprev, inputs[0], 200) txt = ''.join(ix_to_char[ix] for ix in sample_ix) print('----\n %s \n----' % (txt, )) # forward seq_length characters through the net and fetch gradient loss, dWxh, dWhh, dWhy, dbh, dby, hprev = lossFun(inputs, targets, hprev) smooth_loss = smooth_loss * 0.999 + loss * 0.001 if n % 100 == 0: print('iter %d, loss: %f' % (n, smooth_loss)) # print progress # perform parameter update with Adagrad for param, dparam, mem in zip([Wxh, Whh, Why, bh, by], [dWxh, dWhh, dWhy, dbh, dby], [mWxh, mWhh, mWhy, mbh, mby]): mem += dparam * dparam param += -learning_rate * dparam / \ np.sqrt(mem + 1e-8) # adagrad update p += seq_length # move data pointer n += 1 # iteration counter if ((smooth_loss < 10) or (n >= 20000)): sample_ix = sample(hprev, inputs[0], 2000) txt = ''.join(ix_to_char[ix] for ix in sample_ix) predicted_names = set(txt.split("\n")) new_names = predicted_names - all_names print(new_names) print('predicted names len: %d, new_names len: %d.\n' % (len(predicted_names), len(new_names))) break
view rawmin-char-rnn.py hosted with by GitHub
然后从网上找了金庸小说的人名,做了些预处理,每行一个名字,保存到input.txt里,运行代码就可以了。古龙的没有找到比较全的名字, 只有这份武功排行榜,只有100多人。
下面是根据两份名单训练的结果,已经将完全一致的名字(比如段誉)去除了,所以下面的都是LSTM“新创作发明”的名字哈。来, 大家猜猜哪一个结果是金庸的, 哪一个是古龙的呢?
{'姜曾铁', '袁南兰', '石万奉', '郭万嗔', '蔡家', '程伯芷', '汪铁志', '陈衣', '薛铁','哈赤蔡师', '殷飞虹', '钟小砚', '凤一刀', '宝兰', '齐飞虹', '无若之', '王老英', '钟','钟百胜', '师', '李沅震', '曹兰', '赵一刀', '钟灵四', '宗家妹', '崔树胜', '桑飞西','上官公希轰', '刘之余人童怀道', '周云鹤', '天', '凤', '西灵素', '大智虎师', '阮徒忠','王兆能', '袁铮衣商宝鹤', '常伯凤', '苗人大', '倪不凤', '蔡铁', '无伯志', '凤一弼','曹鹊', '黄宾', '曾铁文', '姬胡峰', '李何豹', '上官铁', '童灵同', '古若之', '慕官景岳','崔百真', '陈官', '陈钟', '倪调峰', '妹沅刀', '徐双英', '任通督', '上官铁褚容', '大剑太','胡阳', '生', '南仁郑', '南调', '石双震', '海铁山', '殷鹤真', '司鱼督', '德小','若四', '武通涛', '田青农', '常尘英', '常不志', '倪不涛', '欧阳', '大提督', '胡玉堂','陈宝鹤', '南仁通四蒋赫侯'}
{'邀三', '熊猫开', '鹰星', '陆开', '花', '薛玉罗平', '南宫主', '南宫九', '孙夫人','荆董灭', '铁不愁', '裴独', '玮剑', '人', '陆小龙王紫无牙', '连千里', '仲先生','俞白', '方大', '叶雷一魂', '独孤上红', '叶怜花', '雷大归', '恕飞', '白双发','邀一郎', '东楼', '铁中十一点红', '凤星真', '无魏柳老凤三', '萧猫儿', '东郭先凤','日孙', '地先生', '孟摘星', '江小小凤', '花双楼', '李佩', '仇珏', '白坏刹', '燕悲情','姬悲雁', '东郭大', '谢晓陆凤', '碧玉伯', '司实三', '陆浪', '赵布雁', '荆孤蓝','怜燕南天', '萧怜静', '龙布雁', '东郭鱼', '司东郭金天', '薛啸天', '熊宝玉', '无莫静','柳罗李', '东官小鱼', '渐飞', '陆地鱼', '阿吹王', '高傲', '萧十三', '龙童', '玉罗赵','谢郎唐傲', '铁夜帝', '江小凤', '孙玉玉夜', '仇仲忍', '萧地孙', '铁莫棠', '柴星夫','展夫人', '碧玉', '老无鱼', '铁铁花', '独', '薛月宫九', '老郭和尚', '东郭大路陆上龙关飞','司藏', '李千', '孙白人', '南双平', '王玮', '姬原情', '东郭大路孙玉', '白玉罗生', '高儿','东珏天', '萧王尚', '九', '凤三静', '和空摘星', '关吹雪', '上官官小凤', '仇上官金飞','陆上龙啸天', '司空星魂', '邀衣人', '主', '李寻欢天', '东情', '玉夫随', '赵小凤', '东郭灭', '邀祟厚', '司空星'}
感兴趣的还可以用古代诗人、词人等的名字来做训练,大家机器好或者有时间的可以多训练下,训练得越多越准确。
总结
RNN由于具有记忆功能,在NLP、Speech、Computer Vision等诸多领域都展示了强大的力量。实际上,RNN是图灵等价的。
1 If training vanilla neural nets is optimization over functions, training recurrent nets is optimization over programs.
LSTM是一种目前相当常用和实用的RNN算法,主要解决了RNN的long-term dependencies问题。另外RNN也一直在产生新的研究,比如Attention机制。有空再介绍咯。。。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









