



 本文从Unix的历史背景介绍Linux内核的起源和发展,并深入探讨Linux内核的架构特性,包括内核版本命名规则、内核源码获取及编译流程等。此外还详细介绍了内核编程的特点和挑战。
本文从Unix的历史背景介绍Linux内核的起源和发展,并深入探讨Linux内核的架构特性,包括内核版本命名规则、内核源码获取及编译流程等。此外还详细介绍了内核编程的特点和挑战。
第一章 Linux内核简介
从unix的历史视角来认识Linux内核与Linux操作系统的前世今生。
Unix历史
贝尔实验室设计的一个文件系统原型逐渐演化而成Unix,而后Unix操作系统用C语言重写,让Unix可以被广泛移植。这之后就是一路的创新,变种,Unix成为一个强大且稳定的操作系统。
Unix特点
- 简洁:仅提供几百个系统调用并且有一个非常明确的设计目的
- 抽象:所有东西都被当做文件对待,对数据和设备的操作通过一套相同的系统调用接口来进行的。
- 广泛移植性:Unix内核和系统工具软件使用C语言编写,使得其在各种硬件体系架构面前都具备令人惊异的移植能力
- 进程创建迅速:独特的fork()系统调用
- 简单且稳定的进程间通信元语:一次执行保质保量地完成一个任务;
- 清晰的层次化结构:策略和机制分离的理念,简单的进程间通信元语把单一目的的程序方便地组合在一起,可实现越来越复杂的任务
Linux简介
因为不能修改和发布Minix系统的源代码,Linus开发了自己的操作系统--Linux,Linux是类Unix系统,但没有直接使用Unix源代码,但也没有抛弃Unix的设计目标并且保证了应用程序编程接口的一致,Linux是非商业化的,是自由且公开的。
Linux系统基础:
内核
C库
工具集
系统的基本工具操作系统和内核简介
操作系统:整个系统中负责完成最基本功能和系统管理的那些部分。包括内核、设备驱动程序、启动应到程序、命令行shell或者其他种类的用户界面、基本的文件管理系统工具。
用户界面是操作系统的外在表象,内核才是操作系统的内在核心
内核的组成:
1.中断服务程序(响应中断)
2.调度程序(管理多个进程分享处理器的时间)
3.内存管理程序(管理进程地址空间)
4.系统服务程序(网络、进程间通信)内核空间:系统态和被保护起来的内存空间
系统调用:应用程序与内核通信
应用程序通常调用库函数,再由库函数通过系统调用界面让内核完成任务。
应用程序通过系统调用在内核空间运行,内核称为运行于进程上下文中。
交互关系(应用程序通过系统调用界面陷入内核)是应用程序完成工作的基本方式。内核负责管理系统的硬件设备:
硬件设备相遇系统通信,首先要发出一个异步的中断信号来打断处理器的执行。
中断——中断号——中断服务程序
注意:中断服务程序运行在与所有进程都无关的,专门的中断上下文中运行。将每个处理器在任何指定时间点上的活动必然概括为:
运行于用户空间,执行用户进程
运行于内核空间,处于进程上下文,代表某个特定的进程执行
运行于内核空间,处于中断上下文,与任何进程无关,处理某个特定的中断Linux内核和传统Unix内核的比较
- Unix内核是一个不可分割的静态可执行库,必须以巨大、单独的可执行块的形式在一个单独的地址空间运行,通常需要硬件系统提供页机制(MMU)以管理内存;
Linux内核:模块化设计、抢占式内核。支持内核线程以及动态加载内核模块
单内核:
最大的特点就是内核可以直接调用函数,所有的进程都处于内核态。它从整体上作为一个单独的大的进程来完成,同时也运行在一个单独的地址空间。
简单&性能高
微内核:
功能被划分为多个独立的过程,每一个进程叫做一个服务器。有特权模式和用户模式两种,独立地运行在各自的地址空间。进程间采用IPC通信机制。
Linux内核版本
两种:稳定和处于开发中的。
命名机制:
点号隔开:
主版本号.从版本号.修订版本号.稳定版本号注意:从版本号是偶数——稳定版,奇数——开发版
第二章 从内核出发
获取内核源码
1、使用Git
Git:管理内核源码的一个控制系统,是分布式的。
获取最新提交到Linus版本树的一个副本
$ git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git
下载代码后,更新自己的分支到Linus的最新分支
$ git pull可随时保持与内核官方的代码树一致。
2、安装内核源代码
内核压缩两种形式:GNU zip & bzip2
解压:
bzip2:$ tar xvjf linux-x.y.z.tar.bz2
zip:$ tar xvzf linux-x.y.z.tar.gz注意:内核源代码一般安装在/usr/src/linux目录下,这个源码树并不能用于开发
3、使用补丁
增量补丁可以作为版本转移的桥梁。
只要给旧版本打一个增量补丁,让其旧貌换新颜。
从内部源码树开始,运行
$ patch -p1 < ../patch-x,y,z内核源码树
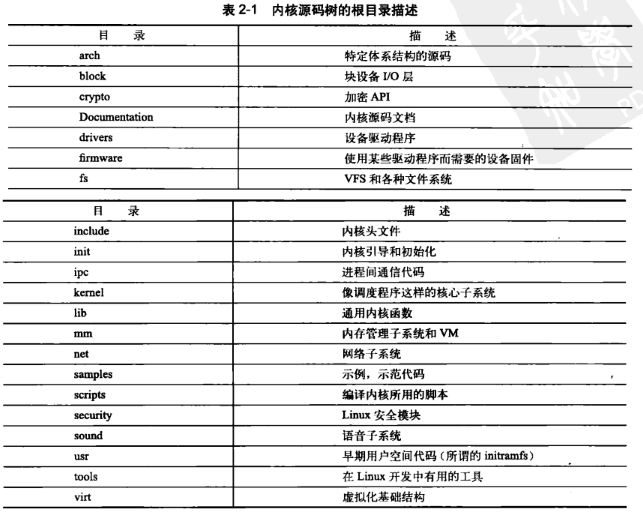
举例:
COPYIN:内核许可证
CREDITS:开发者列表
MAINTAINTERS:维护者列表(维护内核子系统和驱动程序)
Makefile:是基本内核的Makefile。编译内核
1、配置内核
可以配置的各种选项都以CONFIG为前缀。
配置项有
二选一:yes or no
三选一:yes or no or module(选定该配置项但编译的时候以模块形式生成)简化内核配置:
逐一遍历:make config(耗时长)
基于图形工具:make menuconfig
make gconfig
基于默认配置:make defconfig
验证和更新配置:make oldconfig
配置选项CONFIG_IKCONFIG_PROC把完整的压缩过的内核配置文件存放在/proc/config.gz中,再次编译时可以方便地克隆当前的配置。如果当前启用了此选项,可以从/proc下复制出配置文件:
zcat /proc/config.gz > .config编译内核:
make:默认的Makefile自动化编译。2、减少垃圾的编译信息
对输出进行重定向:
$ make > ../detritus
#将错误报告和警告信息重定向到文件中
$ make > /dev/null
#将无用的输出信息重定向到/dev/null中(永无返回值的黑洞)3、衍生多个编译作业
make程序能把编译过程拆分成多个并行的作业。其中每个作业独立并发地运行,有助于加快多处理器系统上的编译过程,也有利于改善处理器的利用率。
默认情况下,make只衍生一个作业。
#以多个作业编译内核
$ make -jn
- j:指定同时执行多任务
- n:要衍生出的作业数4、安装新内核
内核安装按照启动引导工具的说明。
模块安装是自动的,也是独立于体系结构的:
以root身份运行:
$ make modules_install
#把所有已编译的模块安装到正确的主目录/lib/modules下编译时会在根目录下创建一个System.map文件,这是一份符号对照表,将内核符号和他们的起始地址对应起来。
内核开发特点
1、内核开发时既不能访问C库也不能访问标准的C头文件
内核源代码文件不能包含外部头文件。
基本头文件:内核源代码顶级目录下的include中
体系结构相关头文件:内核源代码树的arch/<architecture>/include/asm目录下printk()函数:把格式化好的字符串拷贝到内核日志缓冲区上,syslog程序可以通过读取该缓冲区来获取内核信息。
printk()与printf()的显著区别:
printk()函数允许通过指定一个标志来设置优先级,syslog根据这个标志决定在什么地方显示这个系统信息。
注意:标志和信息之间没有逗号。2、内核编程时必须使用GNU C
GNU:一种操作系统
gcc:GNU编译器的集合1、内联函数:函数会在所调用的位置上展开。可以消除函数调用和返回所带来的开销,但代码会变长。
定义时,需要使用static作为关键字,用inline限定它:
static inline void wolf (unsigned long tail_size)
内联函数必须在使用之前就定义好,一般在头文件中定义。
内核中优先使用内联函数而不是宏。2、内联汇编:通常使用asm()指令嵌入汇编代码,用volatile表示不优化。
Linux内核混合使用了C语言和汇编语言,在偏近体系结构底层或对执行时间要求严格的地方,一般使用汇编语言。
3、分支声明:用于优化条件选择语句。(一个条件经常出现或很少出现)
内核把这条指令封装成了宏,如:
unlikely() - 很少出现,通常为假
likely() - 经常出现,通常为真3、内核编程时缺乏像用户空间那样的内存保护机制
用户程序进行非法内存访问,内核会阻止,但是内核自己非法访问了内存,就没谁可以照顾内核了。
内核中发生内存错误会导致oops(很常见的错误)
另:内核中内存不分页,每用掉一个字节,物理内存都减少一个。
4、内核编程时难以执行浮点运算
用户空间的进程进行浮点操作,是内核完成整数到浮点数操作模式的转换,但内核本身不能陷入。
5、内核给每个进程只有一个很小的定长堆栈
用户空间的栈较大,且能动态增长。
内核栈有准确大小,随体系结构而变。
6、由于内核支持异步中断、抢占和SMP,必须时刻注意同步和并发
内核很容易产生竞争条件。
特别是:
Linux是抢占多任务操作系统
Linux内核支持对称多处理器系统(SMP)
Linux内核支持异步中断
Linux内核可以抢占常用的解决竞争的方法:自旋锁和信号量。
7、要考虑可移植性的重要性
大部分C代码与体系结构无关,必须把与体系结构相关的代码从内核代码树中分离出来。
保持字节序、64位对齐、不假定字长和页面长度等一系列准则有助于移植性。

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









